
こんにちは!コンテンツチームの加藤です。
この記事はCData Software Advent Calander 2025 6日目の記事です。
ChatGPTやClaudeの登場以降、多くの企業がAIを業務に活用しようと試みています。しかし、「AIは賢いはずなのに、なぜか期待通りの回答が得られない」という声をよく耳にします。この課題の根本には、LLM(大規模言語モデル)の構造的な制約があります。そして、この制約を乗り越えるための設計思想として注目されているのが「コンテキストエンジニアリング」です。
この記事では、コンテキストエンジニアリングの基本概念から、企業のデータ活用における実践的な適用方法まで解説していきます。
コンテキストエンジニアリングとは?なぜ今注目されているのか
LLMが抱える本質的な課題
LLMが処理できるコンテキストウィンドウには制約があり、データをたくさん与えれば与えただけモデルのパフォーマンスが良くなるわけではありません。逆に、タスクとの関連性が薄い情報が大量に与えられるとモデル側でどのような情報に着目すればいいかがわからなくなり、タスクをこなすことが難しくなってしまいます。こうした課題を解決し、低コストで効果的にAIを活用するためのノウハウやテクニックのことを、コンテキストエンジニアリングといいます。特に自律的にタスクを解決することが求められるエージェントとしてAIを利用する場合には、プロンプトの設計に留まらずどのような外部システムを連携するか、今のタスクに関係する情報だけを与える、などの工夫が必要になってきます。
そもそも「コンテキスト」とは何か
コンテキストエンジニアリングを理解するために、まずLLMにおける「コンテキスト」の構成要素を整理しましょう。LLMがタスクをこなすためにアクセスするコンテキストの構成要素は以下のようなものがあるとされます。
コンテキスト要素 | 説明 |
システムプロンプト | 1つの会話全体におけるモデルの振る舞いを定義する指示。ルールや例を含む。 |
ユーザープロンプト | ユーザーからの直接的なタスクや質問。いわゆるプロンプトですね。 |
状態 / 履歴(短期メモリ) | 現在の会話の文脈を形成する、直近のユーザーとモデルのやり取り。 |
長期メモリ | 複数の会話セッションをまたいで保持される永続的なナレッジベース。ユーザーの好みや過去のプロジェクトの要約など。ChatGPTやClaudeでは「メモリ」機能として実装されています。 |
外部の情報(RAG) | 特定の質問に答えるために、外部の文書、データベース、APIから取得された情報。 |
利用可能なツール | モデルが呼び出し可能な関数やAPIの定義(例: send_email, check_inventory)。MCP のTools ですね。 |
構造化出力 | モデルの応答形式に関する定義(例: JSONスキーマ)。 |
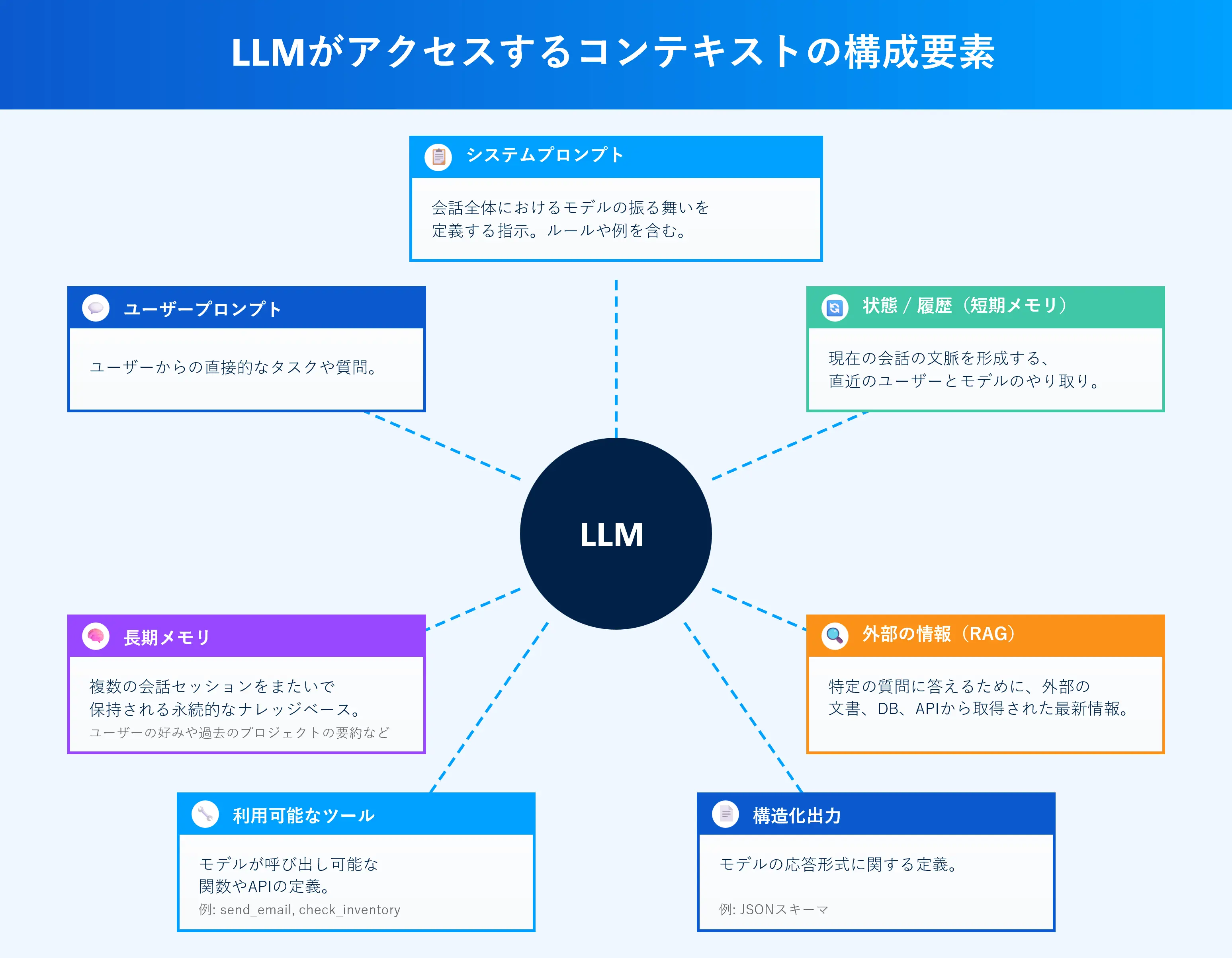
LLMはこれらのデータを「コンテキスト」として受け取り、それに基づいて応答を生成します。つまり、LLMの出力は与えられたコンテキストの内容によって決まると言ってもいいでしょう。
例えば、「先月の自社サイトのパフォーマンスをチャネル別に新規ユーザー数、リードへのコンバージョン数、リードから商談へのコンバージョン数からまとめて」というプロンプトを与えたとしましょう。こうした自社サイト独自の数字はLLMの知識そのものには含まれていないので、外部知識を与えなければハルシネートした適当な数字を返してくるだけで終わってしまいます。それに対して、MCP Server経由で社内のGA4やGoogle広告にアクセスできれば実際の数値に基づいて分析させることができます。また、プロジェクト知識にレポートの出力形式や例を指定しておけば毎回同様の形式でレポートを返してもらえます。
以上で、LLMを扱う上でコンテキストが大事なんだな、というところはわかってもらえると思います。それでは、なぜコンテキストを「エンジニアリング」する必要があるのでしょうか。それは最初に書いたように「LLMが処理できるコンテキストウィンドウには制約があり、データをたくさん与えれば与えただけモデルのパフォーマンスが良くなるわけではない」からです。具体的には以下のような問題が指摘されています。
コンテキストの劣化(Context Rot)
LLMの注意力(アテンション)は有限です。GPT 4.5、Claude 4、Gemini 2.5など(2025年7月時点での)最先端モデルでも、コンテキストが長くなるほど重要な情報への注意が分散し、本来の能力を発揮できなくなることが実験的に確かめられています。

”Context Rot: How Increasing Input Tokens Impacts LLM Performance” より。各モデルのタスク成績(Y軸)が、入力となるデータ量(X軸)が増えるにつれて大きく減退していくことが一目でわかります。
コストとレイテンシーの増大
コンテキストが長くなるほど、処理に必要な計算リソースと時間が増加します。結果として、APIコストの上昇と応答遅延の悪化を招きます。関連して、多くのAIツールは日次や週次で利用量の制限をかけているので、この制限にも引っかかりやすくなります。
さらにAndrew Breunig氏は、長いコンテキストが引き起こす具体的な問題として以下の4点を指摘しています。
コンテキスト汚染(Context Poisoning)
誤った情報やハルシネーション(幻覚)がコンテキストに含まれてしまう問題です。一度誤情報が混入すると、その後の応答全体に悪影響を及ぼします。Gemini 2.5にポケモンをプレイさせる実験で記録されました。
コンテキストによる注意散漫(Context Distraction)
大量のコンテキストがモデルの本来の学習内容を圧倒してしまう問題です。モデルが、訓練時に獲得した知識よりも与えられたコンテキストに依存してしまい直前に行った間違いなどを繰り返すようになるとされます。
コンテキストによる混乱(Context Confusion)
無関係なコンテキストが応答に悪影響を与える問題です。タスクと関係のない情報が多いと、モデルはどの情報に注目すべきか判断できなくなります。
コンテキストの衝突(Context Clash)
コンテキスト内の異なる情報が互いに矛盾してしまう問題です。矛盾した情報が含まれると、モデルは一貫性のない応答を生成してしまいます。
こうしたコンテキスト量の増加が与える悪影響は将来的に解決する可能性もありますが、現時点ではモデルのアーキテクチャそのものに起因する根深い問題とされます。そこで、こうした問題を体系的に解決するための設計思想が「コンテキストエンジニアリング」です。特にAIエージェントとして自律的にタスクを解決させる場合、プロンプトの設計だけでなく、どのような外部システムを連携するか、今のタスクに本当に関係する情報だけを渡すにはどうすればよいか、といった設計上の工夫が必要になります。
コンテキストエンジニアリングの4つの柱
コンテキストエンジニアリングは、主に4つのアプローチで構成されます。
1. 書き出し(Writing)
LLMとのやり取りで得られた重要な情報を、外部記憶として保存する手法です。プロジェクトWikiやナレッジベースのように、会話の中で生まれた洞察や決定事項を蓄積し、後続のタスクで再利用できるようにします。
2. 選択(Selection)
現在のタスクに適したツールや外部知識を、適切に選択できる仕組みを構築することです。多数のデータソースやツールが利用可能な環境では、AIが「今必要なもの」を正確に選び取れることが重要です。
ここで鍵となるのが、データソースやツールの命名規則(Naming Convention)です。AIが各リソースの役割を正しく理解できるよう、明確で一貫性のある名前を付けることで、適切な選択が可能になります。
3. 圧縮(Compression)
会話内容の重要部分を圧縮し、次の会話やタスクに活かす手法です。長い会話履歴をそのまま保持するのではなく、エッセンスを抽出して効率的にコンテキストを管理します。
ただし、圧縮時に重要な情報を失ってしまうリスクもあるため、何を残し何を削るかの判断は慎重に行う必要があります。
4. 分割(Isolation)
複雑なタスクを複数のエージェントに分割して担当させる手法です。たとえば、データを取得するエージェントと、取得したデータが正しいことを検証するエージェントを分けることで、各エージェントのコンテキストをシンプルに保ちつつ、全体として高品質な出力を実現します。
LLMを使ったデータ活用とコンテキストエンジニアリング
企業がAIを活用してデータ分析や業務自動化を行う際、コンテキストエンジニアリングの重要性は一層高まります。
企業データ活用における課題
企業が保有するデータは膨大です。Salesforce、SAP、kintone、各種データベース、Excelファイル...。これらのデータをすべてAIに渡そうとすると、あっという間にコンテキストウィンドウの上限に達してしまいます。
また、データ量の問題だけではありません。分析に不要なデータが大量に含まれていると、AIは本質的な傾向やパターンを見つけることが難しくなります。先述の「コンテキストによる混乱」や「コンテキストによる注意散漫」が発生し、期待した分析結果が得られないのです。
つまり、企業のAI活用を成功させるためには「必要なデータを、必要なだけ取得する」仕組みが不可欠です。
効果的なデータ活用のための要件
AIエージェントがデータを効果的に活用するためには、以下の要件が求められます。
まず、データソースの識別性です。AIが「どのシステムにどんなデータがあるか」を理解できなければ、適切なデータソースを選択することはできません。各システムに分かりやすい名前と説明が付与されていることが重要です。
次に、データ構造の可視性です。テーブル名やカラム名だけでなく、それぞれの意味やデータ型、関連性(主キー・外部キーなど)がAIに伝わる必要があります。これらのメタデータが充実していれば、AIは目的のデータに効率的にアクセスできます。
そして、アクセス方法の標準化です。データソースごとに異なるAPIやクエリ言語を使い分けるのは、AI(そして開発者)にとって大きな負担です。標準化されたインターフェースでアクセスできれば、学習コストを抑えつつ多様なデータソースを活用できます。
CData Connect AI / MCP Serversでコンテキストを最適化したAI活用を実現
これらの要件を満たし、AIエージェントによるデータ活用を実現するソリューションとして、CData はConnect AIとMCP Serversを提供しています。Connect AIはSaaS型の製品で、MCP Serversはローカル / サーバー環境にインストールして使用します。
AIフレンドリーなデータアクセスを実現
Connect AIはAIに、Salesforce、kintone、Google Analyticsなど300以上のデータソースに対してSQLでアクセスする機能を提供します。AIやLLMは各APIの異なる仕様を意識することなく、統一された方法でデータを取得・結合・分析できます。Claude、ChatGPT、Geminiなど人気のAIはSQLについて包括的な知識を持っているので、簡単に実施したい分析を実現できます。
命名規則とメタデータの重要性
コンテキストエンジニアリングの「選択」の柱で述べたように、AIが適切なデータソースを選択するためには、明確な命名規則が重要です。CData Connect AIでは、各データソースに対してAIが理解しやすい名前と説明を付与できます。これにより、AIはタスクに応じて適切なデータソースを自律的に選択することが可能になります。
また、GetTablesやGetColumnsといった機能で取得できるデータには、詳細なメタデータが付与されています。AIはこれらのメタデータを読み取ることで、コンテキストウィンドウを圧迫することなく、必要なデータ構造を把握できるのです。
InstructionsでAIエージェントにデータアクセス方法を教える
Connect AI / MCP Serversの特徴的な機能として、Instructionsがあります。これは、AIエージェントに対してMCP Serverの使い方を体系的に教えるガイド情報を提供する機能です。Instructionsは、以下のような構成でAIエージェントにデータアクセスの方法を伝えます。
データモデルの説明
テーブル:クエリ可能なエンティティを表現
カラム:テーブルを構成する属性
プロシージャ:アクションを実行するための手続き
利用可能なツールの一覧
GetCatalogues:利用可能なデータソースを一覧表示
GetTables:利用可能なテーブルとその説明を一覧表示
GetColumns:テーブルを構成するカラム、主キー/外部キー情報を取得
など
AIエージェントは、まずInstructionsを読み取ることで「このデータソース(MCP Server)で何ができるか」「どのようなツールが使えるか」を理解します。その上で、GetTablesでテーブル一覧を確認し、GetColumnsで必要なカラムを特定し、SQLを構築して目的のデータを取得する、という流れでタスクを遂行できるのです。
これは、コンテキストエンジニアリングの観点から見ると非常に効率的な設計です。AIエージェントは最初に「使い方ガイド」を受け取ることで、試行錯誤なく適切なツールを選択できます。無駄なコンテキストの消費を抑えつつ、的確なデータアクセスを実現できるわけです。
以上の機能を実際に試してみましょう。たとえば、「Google Analyticsのデータから今月のウェブサイトのパフォーマンスを分析して」という自然言語の指示に対して、AIは以下のようなプロセスでデータにアクセスします。
特定のMCP Serverごとの使い方ガイドを確認:どんなSQLクエリが使用できるか、GetTables など利用可能なツールの情報などが記載されているので、AIはどんなアクションを実行できるかすぐに理解できます。
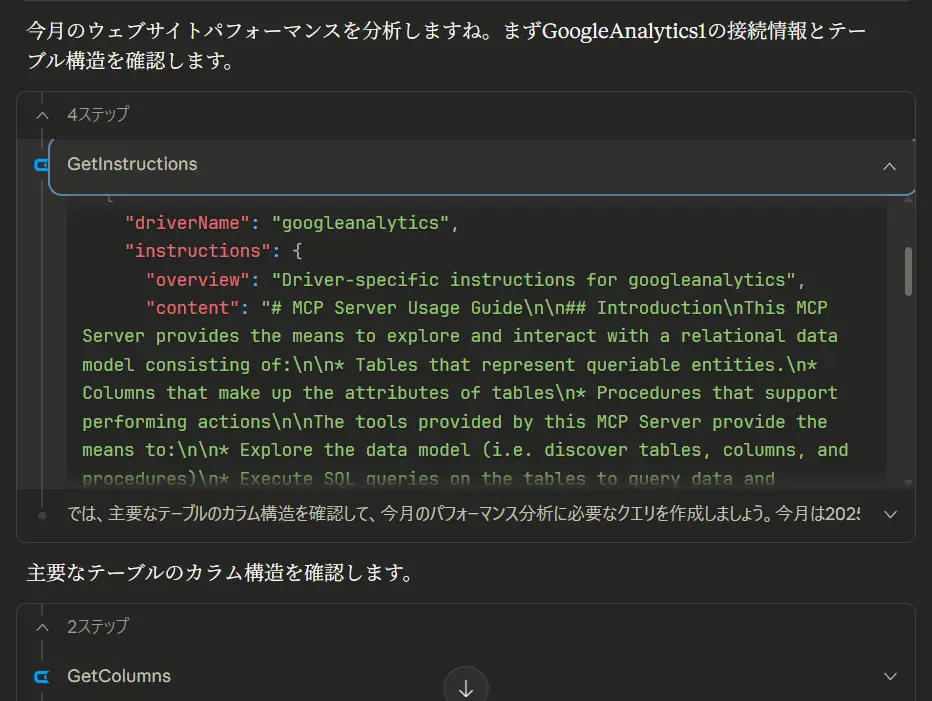
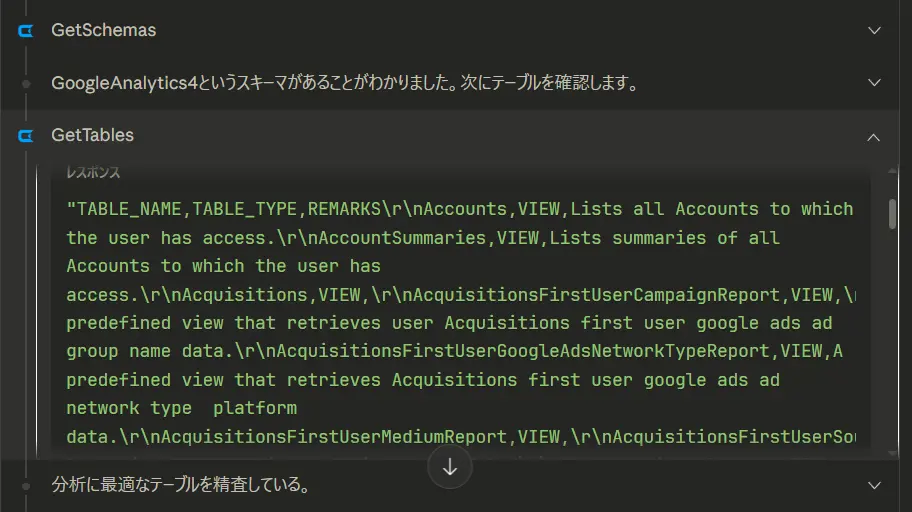
メタデータをもとに目的のテーブルを取得:GetTables でテーブルの一覧とそれぞれのテーブルの説明を確認できるので、AIは利用すべきテーブルをすぐに確認できます。
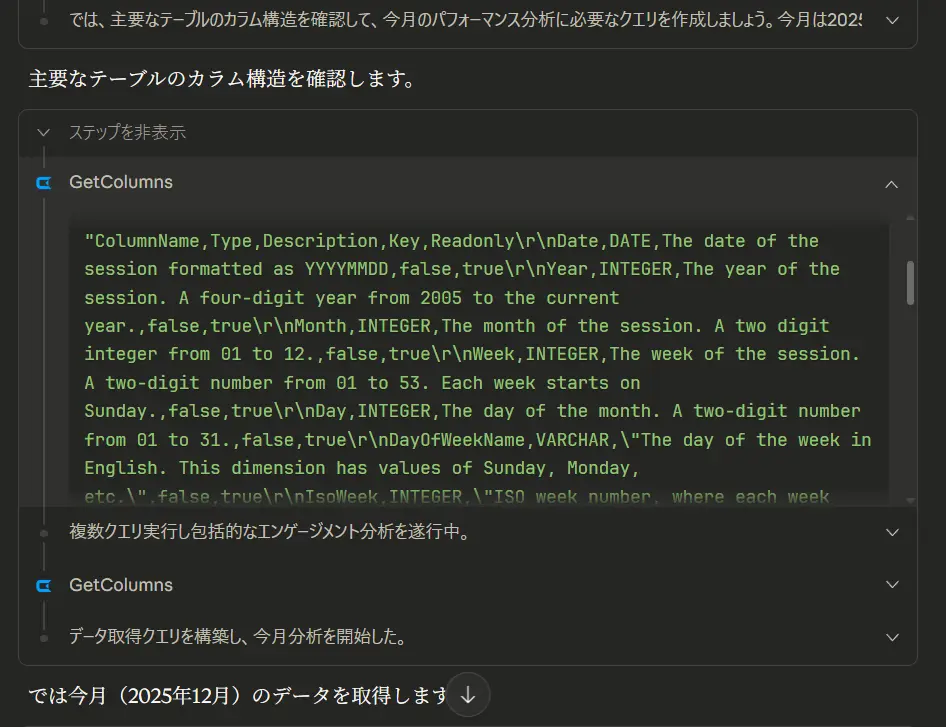
メタデータをもとに目的のカラムを取得:GetColumnsで特定のテーブルのカラム情報を取得します。テーブル同様メタデータが記載されているので、AIはタスクを達成するためにどのカラムを取得すればいいか理解できます。例えばセッション数であれば、Sessions,INTEGER,The number of sessions that began on the site or app.
SQLを使って目的のデータにアクセス:条件に合致するレコードを取得するクエリを実行します。
以上のプロセスを経て、しっかりプロンプトの内容に合った分析を一発で実施してくれました。

このプロセスを支えているのが、Connect AIが提供する豊富なメタデータです。テーブルやカラムの説明、データタイプ、主キー、外部キーなどの付属情報により、AIは必要な情報を効率的に探し出すことができます。
まとめ
AIエージェント時代において、コンテキストエンジニアリングは避けて通れない設計思想です。LLMの能力を最大限に引き出すためには、単にプロンプトを工夫するだけでなく、書き出し・選択・圧縮・分割の4つの柱を意識したシステム設計が求められます。コンテキストの劣化、汚染、混乱、衝突といった問題を回避し、AIが本来の能力を発揮できる環境を整えることが、企業のAI活用成功の鍵を握ります。
特に企業のデータ活用においては、「必要なデータを、必要なだけ取得する」仕組みが重要です。Connect AIは300以上のデータソースに対するSQLアクセス、豊富なメタデータの提供、そしてInstructionsによるデータソース固有の振る舞い定義により、AIフレンドリーなデータ環境の構築を支援します。
AIエージェントによるデータ活用をお考えの方は、ぜひCData Connect AIをお試しください。30日間の無料トライアルで、コンテキストを最適化したAI活用の可能性を体験いただけます。





