





Power View でのSpark のデータのインポートとビジュアライズ

Excel に組み込まれているODBC サポートを使用して、Spark のデータを使用したPower View レポートを素早く作成できます。この記事では、Data リボンからアクセスできるData Connection Wizard を使用して、Spark をPower View レポートにインポートする方法を説明します。
CData ODBC ドライバとは?
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
- Spark をはじめとする、CRM、MA、会計ツールなど多様なカテゴリの270種類以上のSaaS / オンプレミスデータソースに対応
- 多様なアプリケーション、ツールにSpark のデータを連携
- ノーコードでの手軽な接続設定
- 標準 SQL での柔軟なデータ読み込み・書き込み
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.Power View 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData ODBC ドライバのインストールとSpark への接続設定
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
未指定の場合は、初めにODBC DSN で接続プロパティを指定します。ドライバーのインストールの最後にアドミニストレーターが開きます。Microsoft ODBC Data Source Administrator を使用して、ODBC DSN を作成および構成できます。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
DSN を構成する際に、Max Rows プロパティを定めることも可能です。これによって返される行数が制限されるので、ビジュアライゼーション・レポートのデザイン時のパフォーマンスを向上させるのに役立ちます。
Data Connection Wizard で接続
以下のステップに従って、Excel のData Connection Wizard からDSN に接続します。
- [Data]タブで、[From Other Sources]->[From Data Connection Wizard]とクリックします。
- [Data Connection Wizard]で[ODBC DSN]オプションを選択します。
- リストから[ODBC DSN for SparkSQL]を選択します。
操作するテーブルを選択します。
複数のテーブルをインポートする場合は、[Connect to a specific table]オプションの選択を解除します。データソースに接続したら、複数のテーブルを選択できます。[Finish]をクリックして[Data Connection Wizard]を閉じた後、[Select Table]ダイアログで[Enable selection of multiple tables]オプションを選択します。
- [Import Data]ダイアログで、データのインポート先を選択します。例えば、[Table]オプションと[Existing worksheet]オプションを選択します。次に、結果を出力するワークシートのセルをクリックします。
- [Insert]->[Power View]とクリックして新しいPower View レポートを作成します。
テーブルの作成
テーブルは、チャートやその他のデータの表現の開始点です。テーブルを作成するには、フィールドリストでカラムを選択します。テーブル名とカラム名をビューにドラッグアンドドロップすることも可能です。
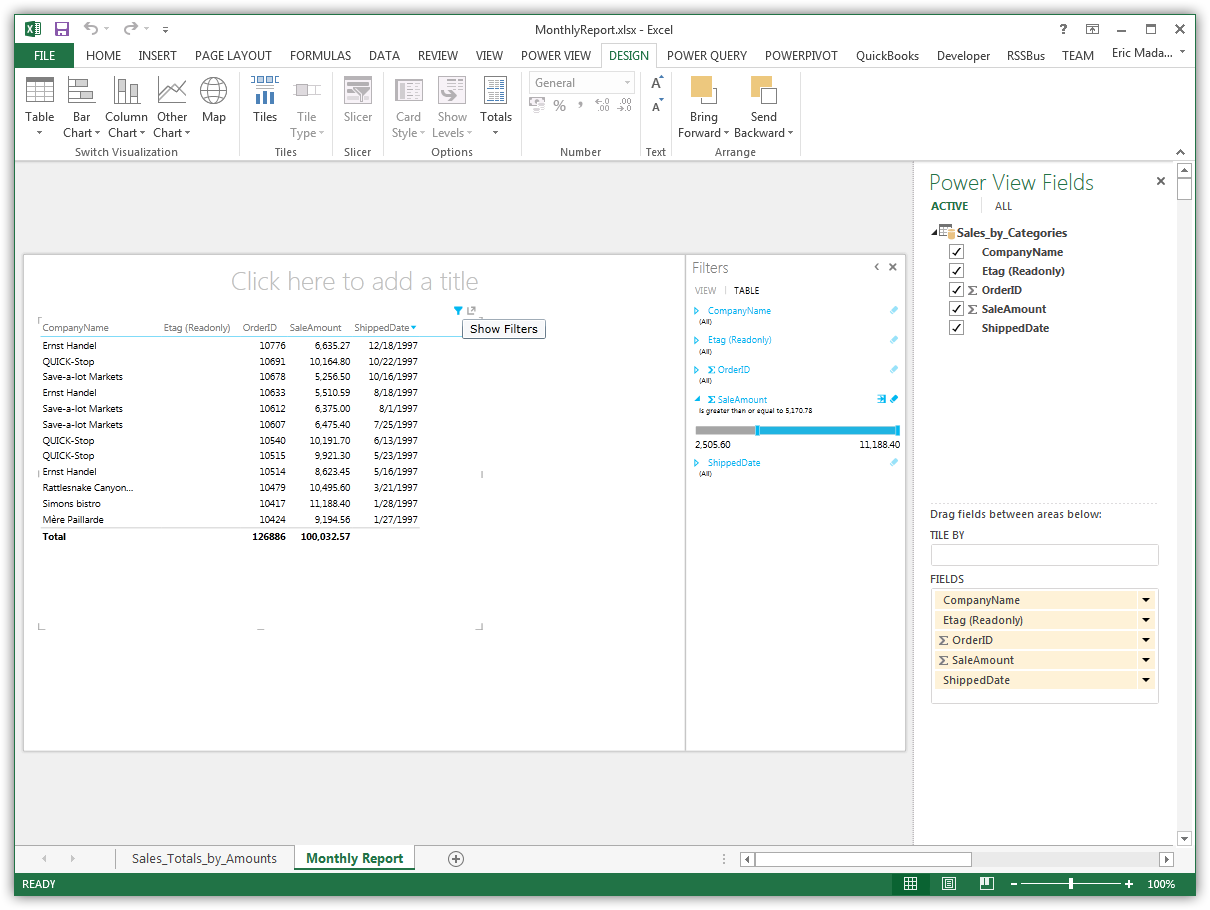
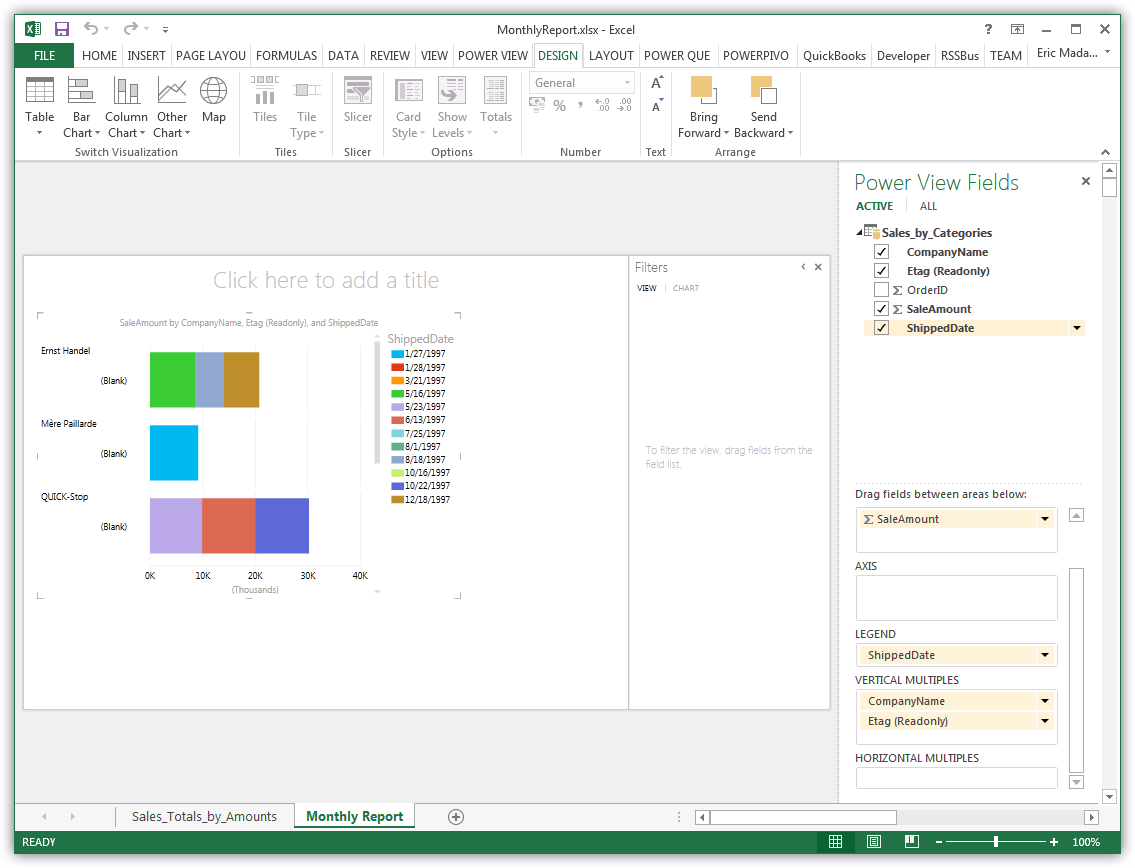
データのビジュアライゼーションを作成
[Design]タブで、テーブルをチャートやその他のビジュアライゼーションに変更できます。
Spark からPower View へのデータ連携には、ぜひCData ODBC ドライバをご利用ください
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。
はじめる準備はできましたか?
Apache Spark ODBC Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード詳細:
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。