





Informatica Cloud で Spark のデータ を連携

Informatica Cloud は、クラウド上で抽出、変換、ロード(ETL)タスクを実行できるツールです。Cloud Secure Agent と CData JDBC Driver for Apache Spark を組み合わせることで、Informatica Cloud から直接 Spark のデータ にリアルタイムでアクセスできます。本記事では、Cloud Secure Agent のダウンロードと登録、JDBC ドライバーを介した Spark への接続、そして Informatica Cloud のプロセスで使用可能なマッピングの作成方法をご紹介します。
Informatica Cloud Secure Agent
JDBC ドライバー経由で Spark のデータ に接続するには、Cloud Secure Agent をインストールします。
- Informatica Cloud の Administrator ページに移動します
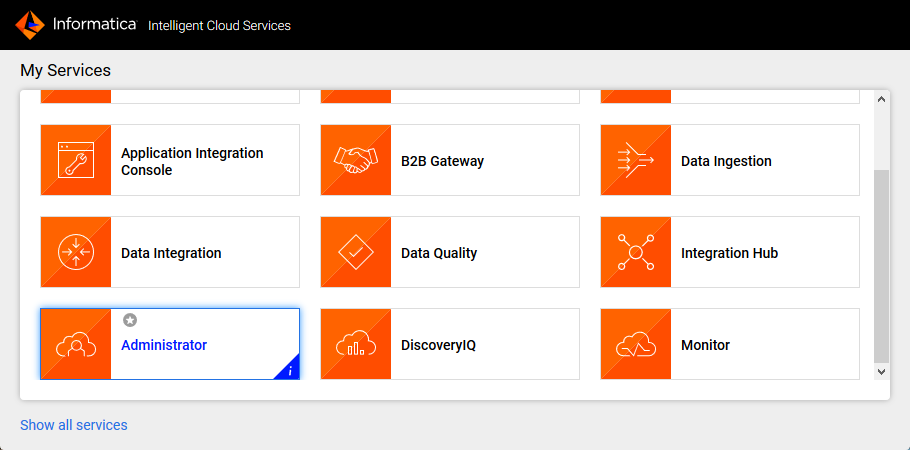
- Runtime Environments タブを選択します
- 「Download Secure Agent」をクリックします
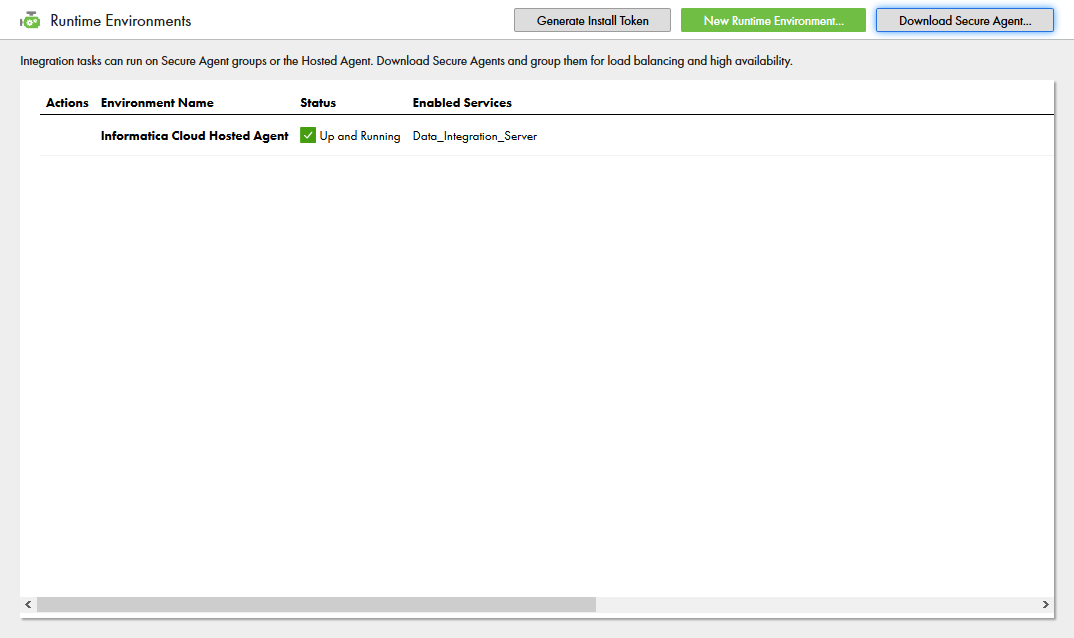
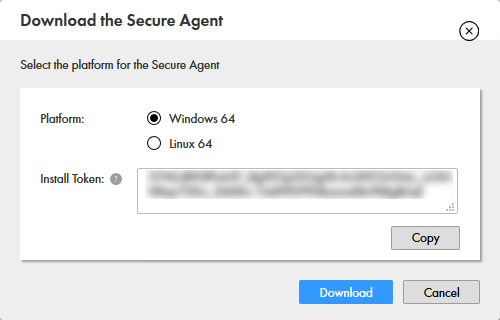
- Install Token をメモしておきます
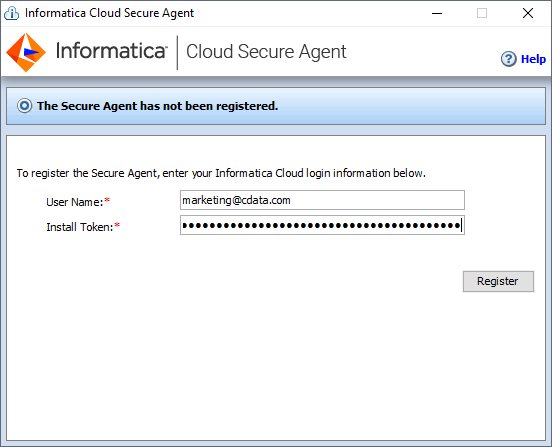
- クライアントマシンでインストーラを実行し、ユーザー名と Install Token を使って Cloud Secure Agent を登録します
NOTE: Cloud Secure Agent のすべてのサービスが起動するまでに、しばらく時間がかかる場合があります。
Spark JDBC Driver への接続
Cloud Secure Agent のインストールと起動が完了したら、JDBC ドライバーを介して Spark に接続する準備が整いました。
Secure Agent マシンへの JDBC ドライバーの追加
- Secure Agent マシンの以下のディレクトリに移動します:
%Secure Agent installation directory%/ext/connectors/thirdparty/
- 設定するマッピングの種類に応じて、フォルダを作成しドライバーの JAR ファイル(cdata.jdbc.sparksql.jar)を追加します。
マッピングの場合は、以下のフォルダを作成してドライバーの JAR ファイルを追加します:
informatica.jdbc_v2/common
アドバンスドモードのマッピングの場合は、以下のフォルダも作成してドライバーの JAR ファイルを追加します:
informatica.jdbc_v2/spark
- Secure Agent を再起動します。
Informatica Cloud での Spark への接続
ドライバーの JAR ファイルをインストールしたら、Informatica Cloud で Spark への接続を設定します。Connections タブをクリックし、New Connection をクリックして、以下のプロパティを入力します:- Connection Name: 接続に名前を付けます(例:CData Spark Connection)
- Type:「JDBC_V2」を選択します
- Runtime Environment: Secure Agent をインストールしたランタイム環境を選択します
- JDBC Driver Class Name: JDBC ドライバークラス名を入力します:cdata.jdbc.sparksql.SparkSQLDriver
- JDBC Connection URL: Spark の JDBC URL を設定します。URL は以下のようになります:
jdbc:sparksql:Server=127.0.0.1;
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
組み込みの接続文字列デザイナー
JDBC URL の作成には、Spark JDBC Driver に組み込まれている接続文字列デザイナーを使用できます。.jar ファイルをダブルクリックするか、コマンドラインから実行してください。
java -jar cdata.jdbc.sparksql.jar接続プロパティを入力し、接続文字列をクリップボードにコピーします。
")
- Username: プレースホルダー値を設定します(Spark はユーザー名を必要としないため)
- Password: プレースホルダー値を設定します(Spark はパスワードを必要としないため)
")
Spark のデータ のマッピングを作成
Spark への接続を設定したら、Informatica の任意のプロセスで Spark のデータ にアクセスできます。以下の手順では、Spark から別のデータターゲットへのマッピングを作成する方法を説明します。
- Data Integration ページに移動します
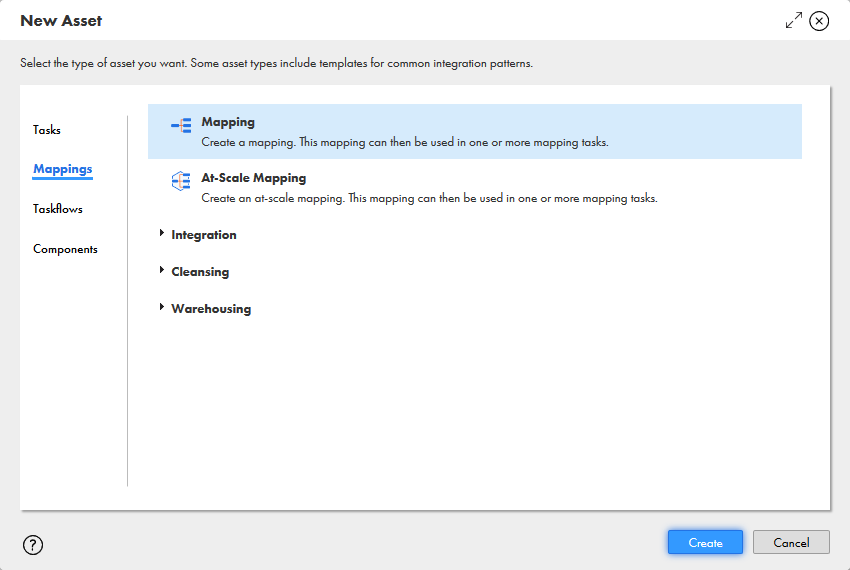
- New.. をクリックし、Mappings タブから Mapping を選択します
- Source Object をクリックし、Source タブで Connection を選択し、Source Type を設定します

- 「Select」をクリックして、マッピングするテーブルを選択します

- Fields タブで、マッピングする Spark テーブルのフィールドを選択します

- Target オブジェクトをクリックし、Target ソース、テーブル、フィールドを設定します。Field Mapping タブで、ソースフィールドをターゲットフィールドにマッピングします。

マッピングの設定が完了すると、Informatica Cloud でサポートされている任意の接続先と Spark のデータ のリアルタイム連携を開始できます。CData JDBC Driver for Apache Spark の30日間無償トライアルをダウンロードして、Informatica Cloud で Spark のデータ の活用を今すぐ始めましょう。
はじめる準備はできましたか?
Apache Spark Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード