





Google Data Fusion で Sage 300 に連携した ETL プロセスを作成

Google Data Fusion を使用すると、セルフサービス型のデータ連携を行い、異なるデータソースを統合できます。CData JDBC Driver for Sage 300 をアップロードすることで、Google Data Fusion のパイプライン内から Sage 300 のデータ にリアルタイムでアクセスできるようになります。CData JDBC Driver を使用すると、Sage 300 のデータ を Google Data Fusion でネイティブにサポートされている任意のデータソースにパイプできますが、この記事では、Sage 300 から Google BigQuery へデータをパイプする方法を説明します。
CData JDBC Driver for Sage 300 を Google Data Fusion にアップロード
CData JDBC Driver for Sage 300 を Google Data Fusion インスタンスにアップロードして、Sage 300 のデータ にリアルタイムでアクセスしましょう。Google Data Fusion では JDBC ドライバーの命名規則に制限があるため、JAR ファイルを driver-version.jar という形式に合わせてコピーまたはリネームしてください。例:cdatasage300-2020.jar
- Google Data Fusion インスタンスを開きます
- をクリックしてエンティティを追加し、ドライバーをアップロードします

- "Upload driver" タブで、リネームした JAR ファイルをドラッグまたは参照します。
- "Driver configuration" タブで以下を設定します:
- Name: ドライバーの名前(cdata.jdbc.sage300)を作成し、メモしておきます
- Class name: JDBC クラス名を設定します:(cdata.jdbc.sage300.Sage300Driver)
")
- "Finish" をクリックします
Google Data Fusion で Sage 300 のデータ に接続
JDBC Driver をアップロードしたら、Google Data Fusion のパイプラインで Sage 300 のデータ にリアルタイムでアクセスできます。
- Pipeline Studio に移動して、新しいパイプラインを作成します
- "Source" オプションから "Database" をクリックして、JDBC Driver 用のソースを追加します

- Database ソースの "Properties" をクリックしてプロパティを編集します
NOTE:Google Data Fusion で JDBC Driver を使用するには、ライセンス(製品版またはトライアル)とランタイムキー(RTK)が必要です。ライセンス(またはトライアル)の取得については、CData までお問い合わせください。
- Label を設定します
- Reference Name を将来の参照用の値に設定します(例:cdata-sage300)
- Plugin Type を "jdbc" に設定します
- Connection String を Sage 300 の JDBC URL に設定します。例:
jdbc:sage300:RTK=5246...;User=SAMPLE;Password=password;URL=http://127.0.0.1/Sage300WebApi/v1/-/;Company=SAMINC;Sage 300 には、Sage 300 Web API で通信するための初期設定が必要となるます。
- Sage 300 のユーザー向けのセキュリティグループを設定します。Sage 300 のユーザーに、Security Groups の下にあるbSage 300 Web API オプションへのアクセスを付与します(各モジュール毎に必要です)。
- /Online/Web と/Online/WebApi フォルダ内のweb.config ファイルを両方編集して、AllowWebApiAccessForAdmin のキーを true 設定します。webAPI アプリプールを再起動すると設定が反映されます。
- ユーザーアクセスを設定したら、https://server/Sage300WebApi/ をクリックして、web API へのアクセスを確認してください。
Basic 認証を使用してSage 300 へ認証します。
Basic 認証を使用して接続する
Sage 300 に認証するには、次のプロパティを入力してください。プロバイダーは、クッキーを使用してSage 300 が開いたセッションを再利用することに注意してください。 そのため、資格情報はセッションを開く最初のリクエストでのみ使用されます。その後は、Sage 300 が返すクッキーを認証に使用します。
- Url:Sage 300 をホストするサーバーのURL に設定します。Sage 300 Web API 用のURL を次のように作成してください。 {protocol}://{host-application-path}/v{version}/{tenant}/ 例えば、 http://localhost/Sage300WebApi/v1.0/-/ です。
- User:アカウントのユーザー名に設定します。
- Password:アカウントのパスワードに設定します。
ビルトイン接続文字列デザイナー
JDBC URL の作成には、Sage 300 JDBC Driver に組み込まれている接続文字列デザイナーを使用できます。JAR ファイルをダブルクリックするか、コマンドラインから JAR ファイルを実行してください。
java -jar cdata.jdbc.sage300.jar接続プロパティを入力し、接続文字列をクリップボードにコピーします。
")
- Import Query を Sage 300 から取得したいデータを抽出する SQL クエリに設定します。例:
SELECT * FROM OEInvoices

- "Sink" タブから、同期先シンクを追加します(この例では Google BigQuery を使用します)
- BigQuery シンクの "Properties" をクリックしてプロパティを編集します
- Label を設定します
- Reference Name を sage300-bigquery のような値に設定します
- Project ID を特定の Google BigQuery プロジェクト ID に設定します(またはデフォルトの "auto-detect" のままにします)
- Dataset を特定の Google BigQuery データセットに設定します
- Table を Sage 300 のデータ を挿入するテーブル名に設定します

Source と Sink を設定すると、Sage 300 のデータ を Google BigQuery にパイプする準備が整います。パイプラインを保存してデプロイしてください。パイプラインを実行すると、Google Data Fusion が Sage 300 からリアルタイムデータをリクエストし、Google BigQuery にインポートします。
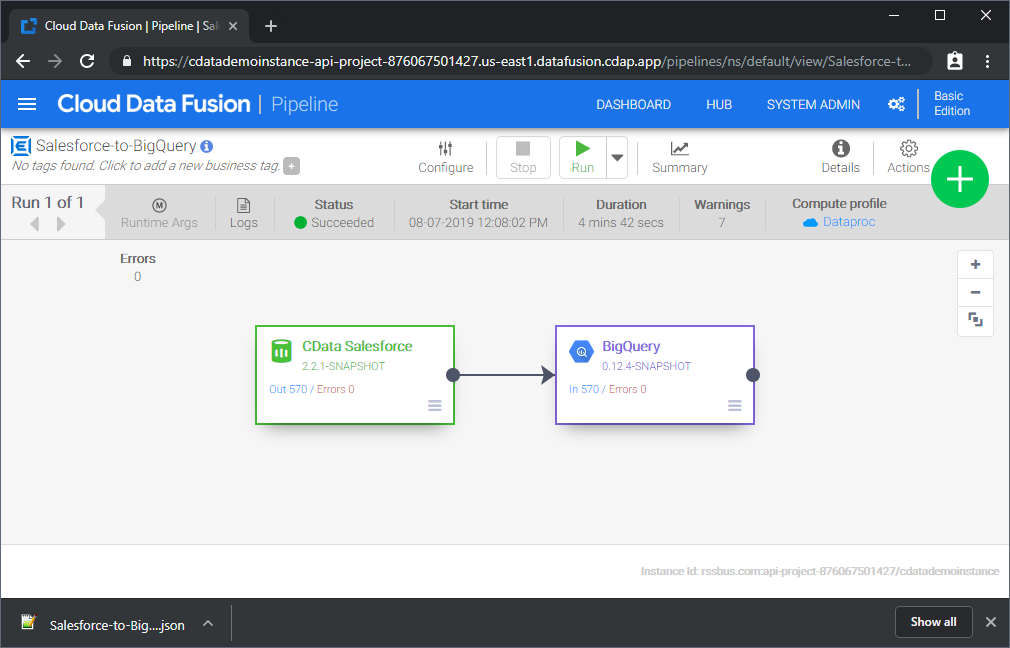
これはシンプルなパイプラインの例ですが、変換、分析、条件などを使用してより複雑な Sage 300 パイプラインを作成できます。CData JDBC Driver for Sage 300 の 30日間の無償トライアルをダウンロードして、今すぐ Google Data Fusion で Sage 300 のデータ をリアルタイムで活用しましょう。
はじめる準備はできましたか?
Sage 300 Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード