はじめに
この記事ではPythonで実装されたオープンソースのWebアプリケーションのフレームワークであるStreamlitで、CData ODBC Driverを扱う方法をご紹介します。
Streamlitとは
StreamlitはPythonで実装されたオープンソースのWebアプリケーションのフレームワークです。Streamlitを用いることで、機械学習やデータサイエンスのためのカスタムウェブアプリを簡単に作成・共有できます。
Streamlitの詳細についてはこちらのリンクを合わせて参照ください。
Streamlitでアプリ作成
CData ODBC Driverのインストール
まずはStreamlitから利用するCData ODBC Driverをインストールします。今回はCData ODBC Driver for Salesforceを利用します。
インストール後はODBC Data SourceからDSN構成の設定を行います。接続設定の詳細は割愛しますが、接続設定については製品ドキュメントをご確認ください。

Python環境の準備
詳細は割愛しますが、この記事では3.11.9のバージョンを利用しています。
必要なパッケージのインストール
Python環境の準備が出来たら、必要なパッケージをインストールします。
pip install streamlit pandas pyodbc matplotlib
Streamlitのアプリを作成
app.pyファイルを作成して、以下のコードを記述します。コードについて簡単に解説しますと、pyodbcよりCData ODBC Driver for Salesforceを利用して、Salesforceのデータにアクセスしています。
import streamlit as st
import pyodbc
import pandas as pd
# データベースに接続
def get_connection():
conn = pyodbc.connect('DSN=CData Salesforce Sys')
return conn
# データを取得
def load_data(query):
conn = get_connection()
cursor = conn.cursor()
cursor.execute(query)
columns = [column[0] for column in cursor.description]
data = cursor.fetchall()
df = pd.DataFrame.from_records(data, columns=columns)
cursor.close()
conn.close()
return df
# データを可視化
def visualize_data(df, query_name):
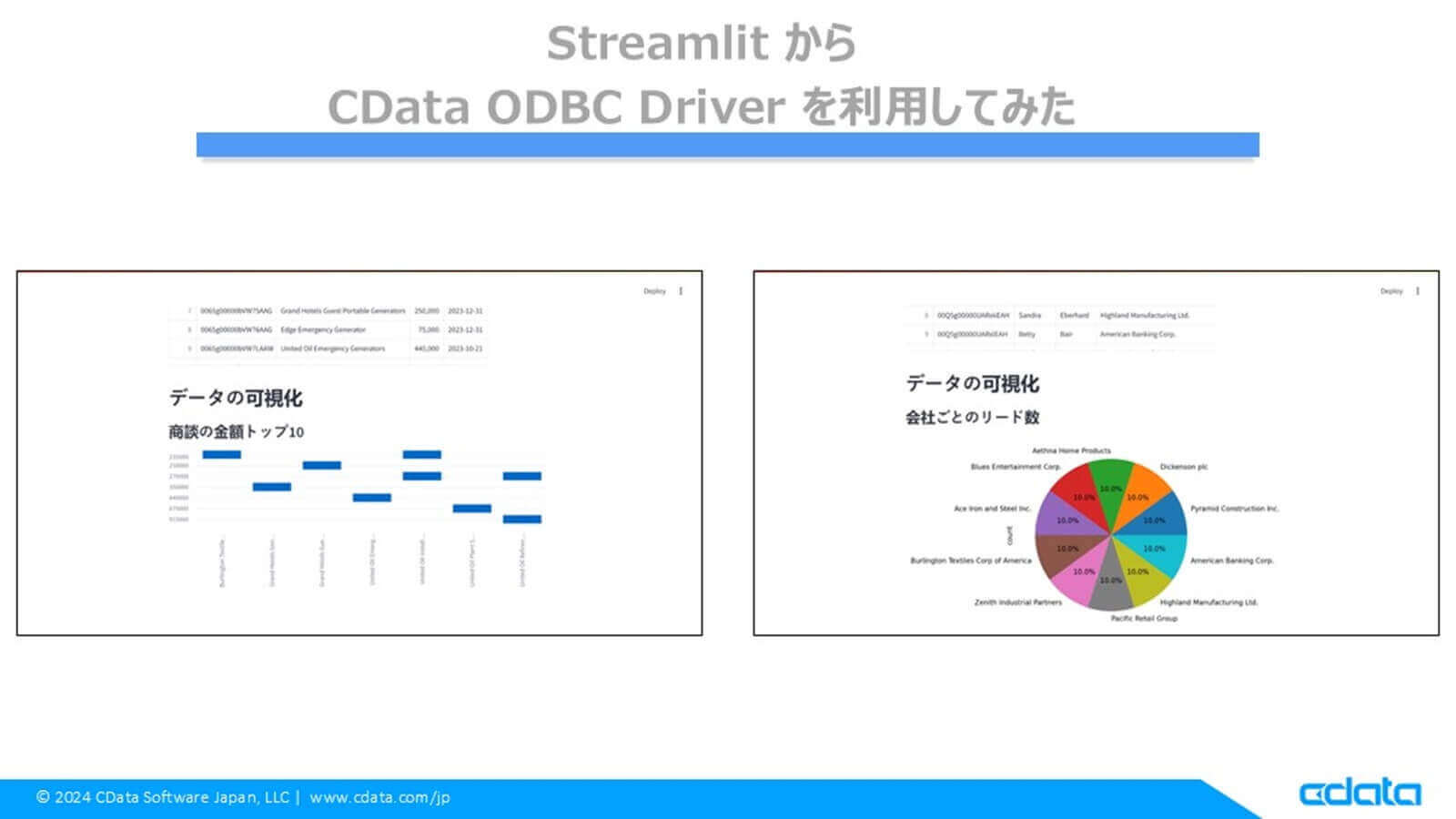
if query_name == "取引先(Account)一覧を取得":
# 業種ごとの取引先数を棒グラフで表示
industry_counts = df['Industry'].value_counts()
st.subheader("業種ごとの取引先数")
st.bar_chart(industry_counts)
elif query_name == "商談(Opportunity)の詳細":
# 商談の金額トップ10を棒グラフで表示
st.subheader("商談の金額トップ10")
df_sorted = df.dropna(subset=['Amount']).sort_values(
'Amount', ascending=False).head(10)
st.bar_chart(df_sorted.set_index('Name')['Amount'])
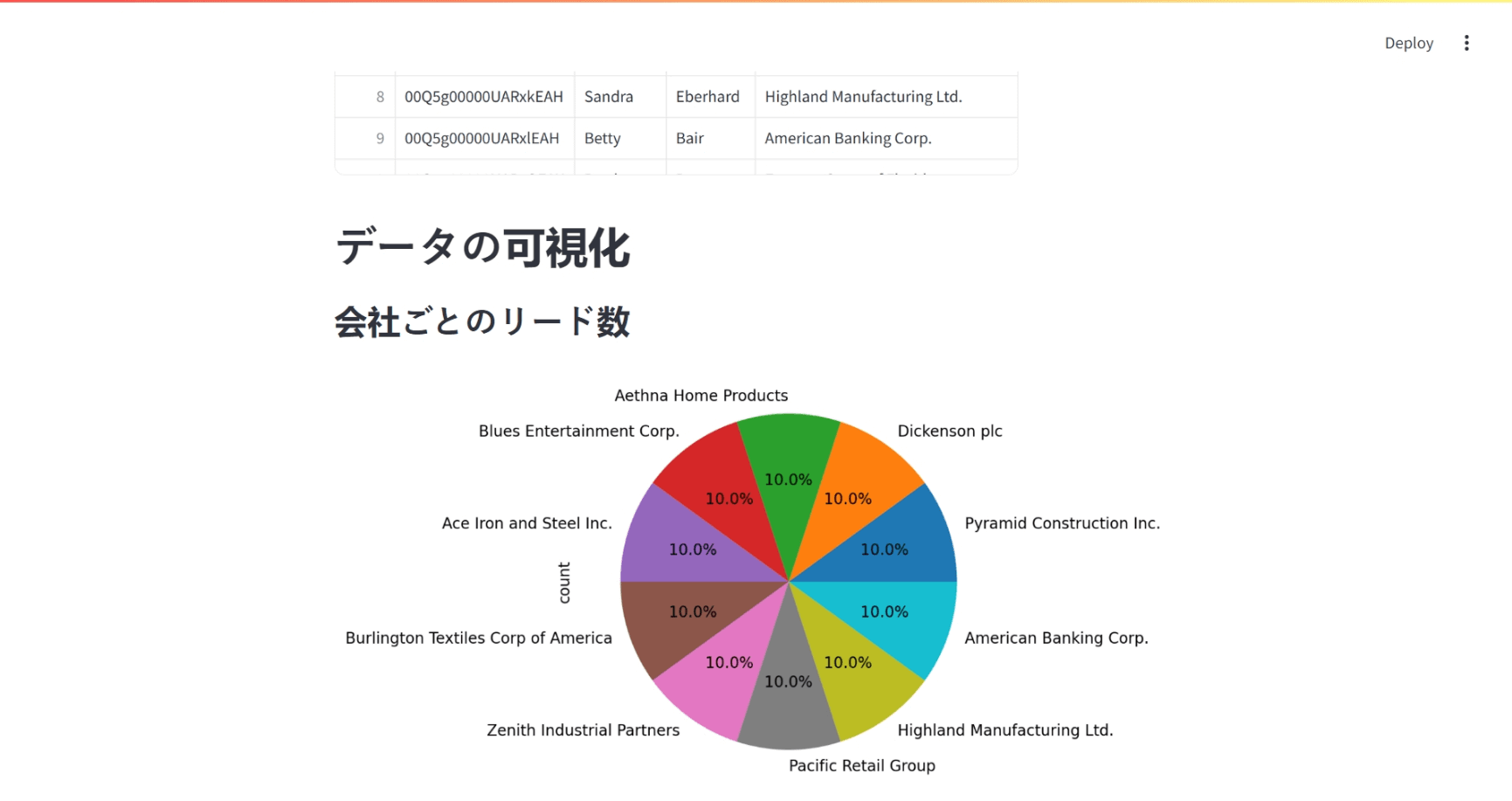
elif query_name == "リード(Lead)のリスト":
# 会社ごとのリード数を円グラフで表示
company_counts = df['Company'].value_counts().head(10)
st.subheader("会社ごとのリード数")
st.pyplot(company_counts.plot.pie(
autopct="%1.1f%%", figsize=(5, 5)).figure)
# Streamlitのアプリのメイン部分
def main():
st.title("Streamlitアプリ")
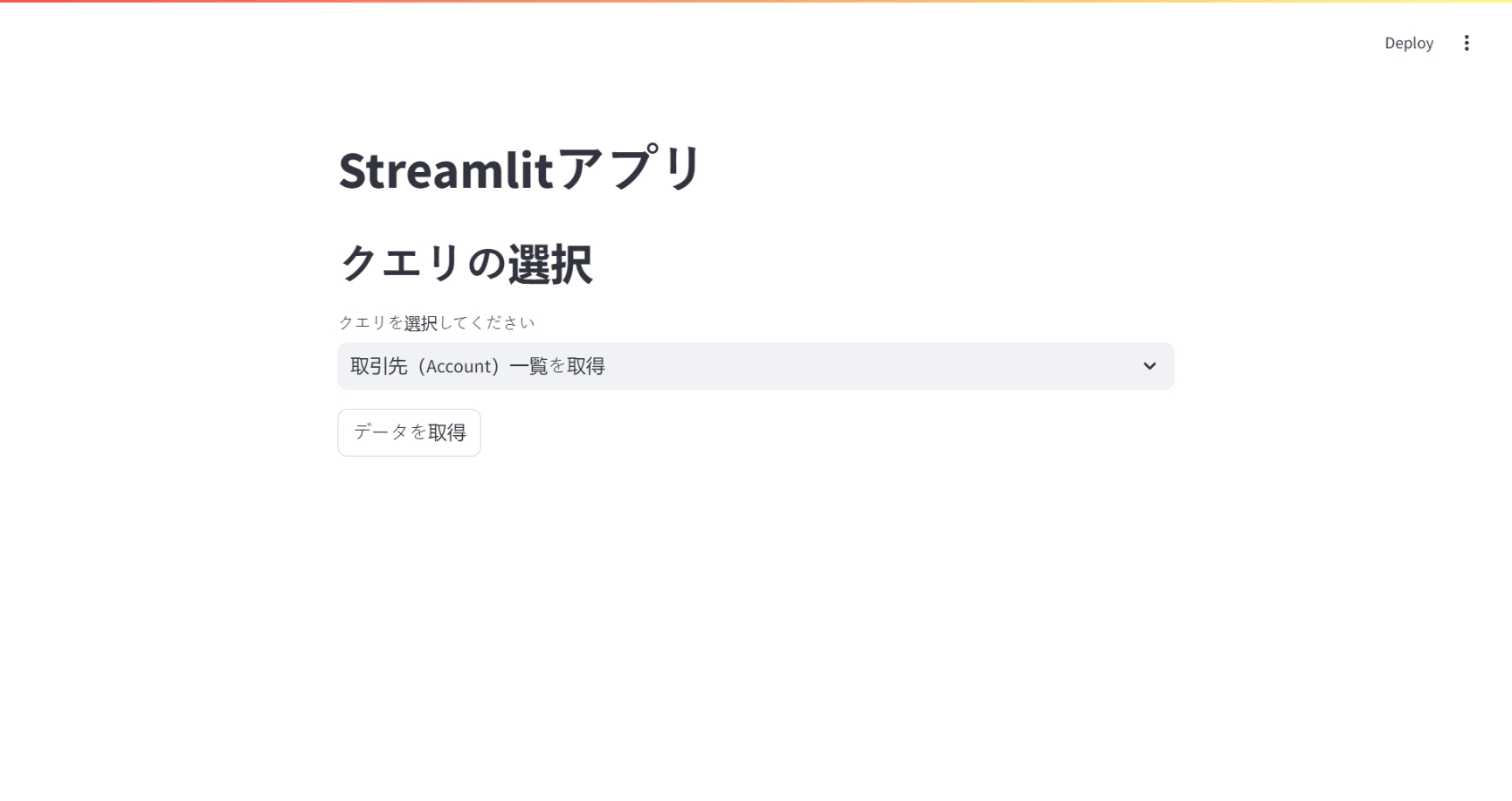
st.header("クエリの選択")
query_options = {
"取引先(Account)一覧を取得": "SELECT Id, Name, Industry FROM Account",
"商談(Opportunity)の詳細": "SELECT Id, Name, Amount, CloseDate FROM Opportunity",
"リード(Lead)のリスト": "SELECT Id, FirstName, LastName, Company FROM Lead",
}
query_name = st.selectbox("クエリを選択してください", list(query_options.keys()))
query = query_options[query_name]
if st.button("データを取得"):
try:
df = load_data(query)
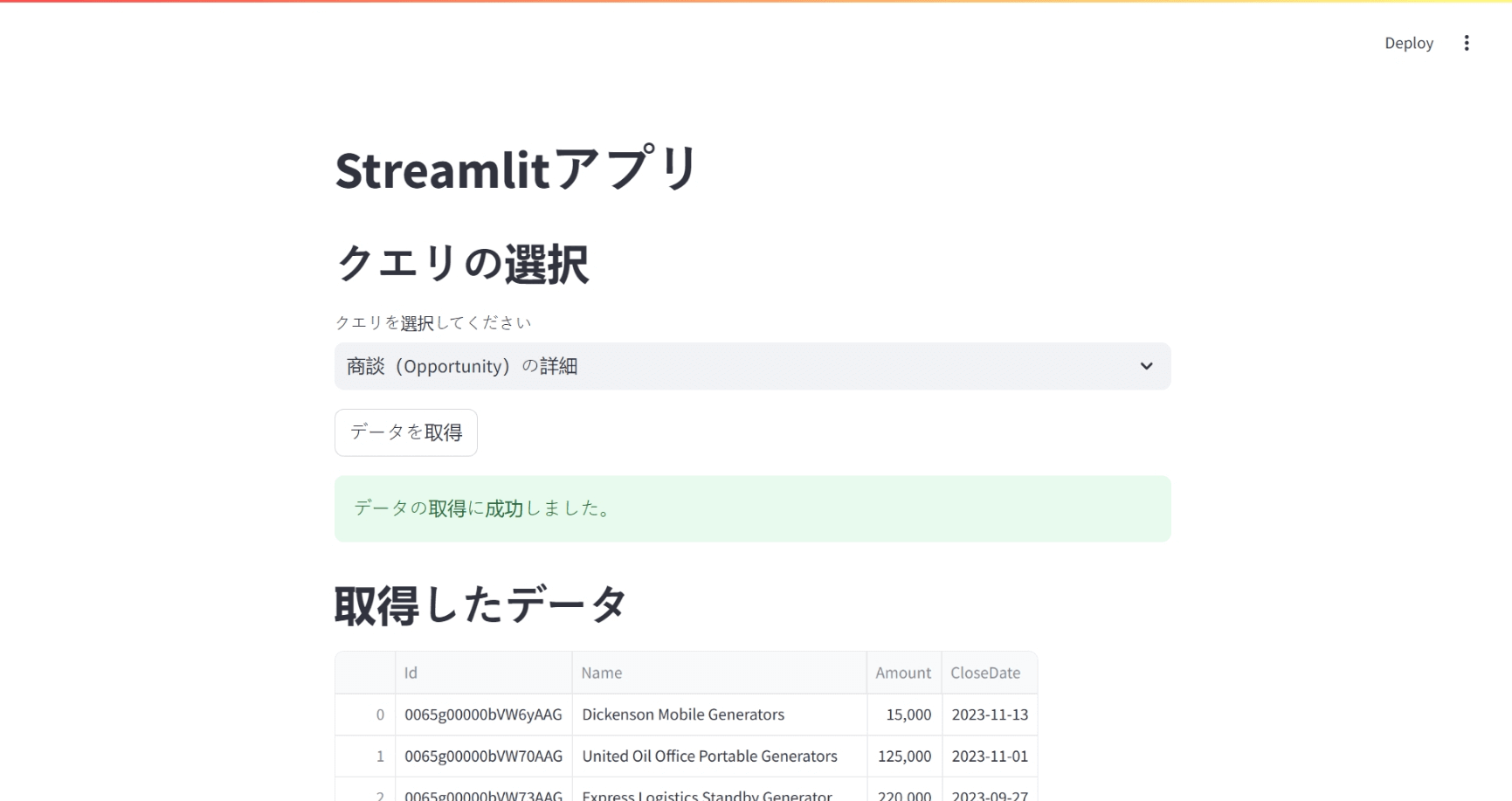
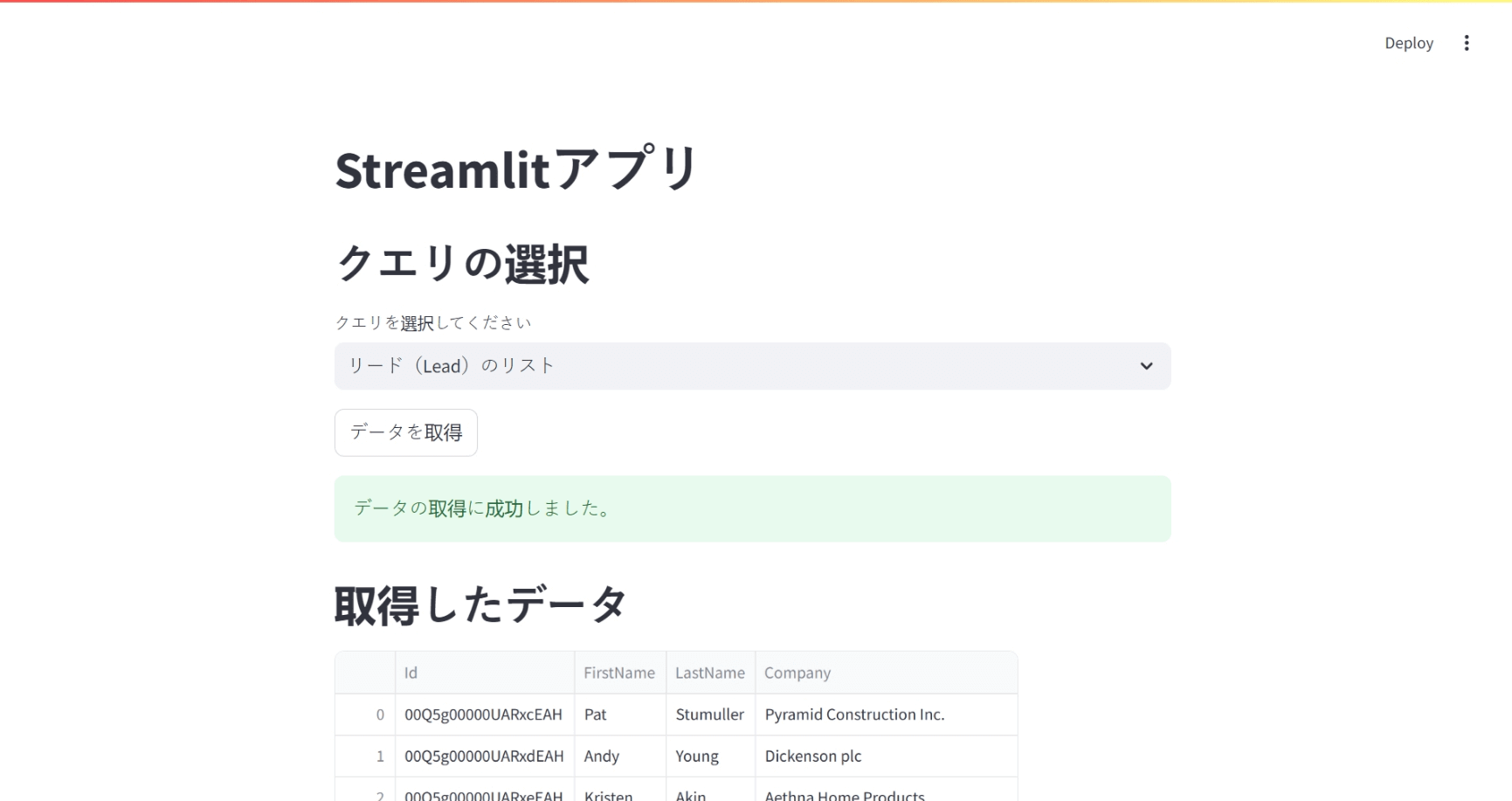
st.success("データの取得に成功しました。")
st.header("取得したデータ")
st.dataframe(df)
# 可視化オプションの提供
st.header("データの可視化")
visualize_data(df, query_name)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
if __name__ == "__main__":
main()
Streamlitの起動
以下のコマンドでStreamlitを起動すると自動でブラウザが立ち上がります。
streamlit run app.py
ドロップダウンリストからクエリを選択して、「データを取得」ボタンを押すと、クエリが実行され、取得されたデータが表示されます。

他のクエリを選択して、「データを取得」ボタンを再度押すと、別のデータが取得され、表示されなおします。
まとめ
簡単ではありますが、この記事ではPythonで実装されたオープンソースのWebアプリケーションのフレームワークであるStreamlitで、CData ODBC Driverを扱う方法をご紹介致しました。Streamlitでは簡単にWebアプリを作成することが出来ます。CData ODBC Driverを利用することで、StreamlitからSaaSなどのデータソースへ簡単に接続出来るようになります。
各コネクタは30日間の評価版が無料で利用できますので、Streamlitとクラウドサービスとのデータ連携を検討している方はぜひお試しください。





