





Zuora のデータをAUTORO(旧Robotic Crowd) で連携して利用する方法

AUTORO(旧Robotic Crowd) www.roboticcrowd.com/ はクラウド型(SaaS)のロボティック・プロセス・オートメーション(RPA)で、普段利用しているブラウザで業務フローを記録し、ワークフローを作成することができるサービスです。
RPAの機能としての使いやすさはもちろんのこと、クラウドベースの特性を生かして、各種ストレージ(Google DriveやBox等)サービスやExcel・Google Spreadsheetなどの表計算ソフトとも連携できるのが特徴です。また、HTTPリクエストのアクションを利用することで、様々なAPIとの連携も可能になっています。
この記事ではCData API Server とADO.NET Zuora Provider を使って、AUTORO(旧Robotic Crowd) でZuora のデータを操作できるようにします。
API Server の設定
以下のリンクからAPI Server の無償トライアルをスタートしたら、セキュアなZuora OData サービスを作成していきましょう。
Zuora への接続
Robotic Crowd からZuora のデータを操作するには、まずZuora への接続を作成・設定します。
- API Server にログインして、「Connections」をクリック、さらに「接続を追加」をクリックします。
- 「接続を追加」をクリックして、データソースがAPI Server に事前にインストールされている場合は、一覧から「Zuora」を選択します。
- 事前にインストールされていない場合は、コネクタを追加していきます。コネクタ追加の手順は以下の記事にまとめてありますので、ご確認ください。
CData コネクタの追加方法はこちら >> - それでは、Zuora への接続設定を行っていきましょう!
-
Zuora はユーザー認証にOAuth 標準を使用しています。OAuth 認証ついて詳しくは、オンラインヘルプドキュメントを参照してください。
Tenant プロパティの設定
プロバイダへの有効な接続を作成するには、アカウントの設定と合致するテナント値を1つ選択する必要があります。以下は、利用可能なオプションのリストです。- USProduction:リクエストはhttps://rest.zuora.com に送信されます。
- USAPISandbox:リクエストはhttps://rest.apisandbox.zuora.com に送信されます。
- USPerformanceTest:リクエストはhttps://rest.pt1.zuora.com に送信されます。
- EUProduction:リクエストはhttps://rest.eu.zuora.com に送信されます。
- EUSandbox:リクエストはhttps://rest.sandbox.eu.zuora.com に送信されます。
デフォルトではUSProduction テナントを使用します。
Zuora サービスの選択
データクエリとAQuA API の2つのZuora サービスを使用します。デフォルトでは、ZuoraService はAQuADataExport に設定されています。DataQuery
データクエリ機能は、非同期の読み取り専用SQL クエリを実行することで、Zuora テナントからのデータのエクスポートを実現します。 このサービスは、素早く軽量なSQL クエリでの使用を推奨します。制限
- フィルタ適用後の、テーブルごとの入力レコードの最大数: 1,000,000
- 出力レコードの最大数: 100,000
- テナントごとの、実行用に送信される同時クエリの最大数: 5
- テナントごとの、同時クエリの制限に達した後に実行用に送信され、キューに追加されるクエリの最大数: 10
- 1時間単位での、各クエリの最大処理時間: 1
- GB 単位での、各クエリに割り当てられるメモリの最大サイズ: 2
- Index Join を使用する際のインデックスの最大値。言い換えれば、Index Join を使用する際にWHERE 句で使われる一意の値に基づいた、左のテーブルから返されるレコードの最大数: 20.000
AQuADataExport
AQuA API のエクスポートは、すべてのオブジェクト(テーブル)のすべてのレコードをエクスポートするように設計されています。AQuA のクエリジョブには以下の制限があります。制限
- AQuA のジョブ内のクエリが8時間以上実行されている場合、ジョブは自動的に停止されます。
- 停止されたAQuA のジョブは3回再試行可能で、その後失敗として返されます。
- 接続情報の入力が完了したら、「保存およびテスト」をクリックします。
Zuora はユーザー認証にOAuth 標準を使用しています。OAuth 認証ついて詳しくは、オンラインヘルプドキュメントを参照してください。
Tenant プロパティの設定
プロバイダへの有効な接続を作成するには、アカウントの設定と合致するテナント値を1つ選択する必要があります。以下は、利用可能なオプションのリストです。
- USProduction:リクエストはhttps://rest.zuora.com に送信されます。
- USAPISandbox:リクエストはhttps://rest.apisandbox.zuora.com に送信されます。
- USPerformanceTest:リクエストはhttps://rest.pt1.zuora.com に送信されます。
- EUProduction:リクエストはhttps://rest.eu.zuora.com に送信されます。
- EUSandbox:リクエストはhttps://rest.sandbox.eu.zuora.com に送信されます。
デフォルトではUSProduction テナントを使用します。
Zuora サービスの選択
データクエリとAQuA API の2つのZuora サービスを使用します。デフォルトでは、ZuoraService はAQuADataExport に設定されています。DataQuery
データクエリ機能は、非同期の読み取り専用SQL クエリを実行することで、Zuora テナントからのデータのエクスポートを実現します。 このサービスは、素早く軽量なSQL クエリでの使用を推奨します。制限
- フィルタ適用後の、テーブルごとの入力レコードの最大数: 1,000,000
- 出力レコードの最大数: 100,000
- テナントごとの、実行用に送信される同時クエリの最大数: 5
- テナントごとの、同時クエリの制限に達した後に実行用に送信され、キューに追加されるクエリの最大数: 10
- 1時間単位での、各クエリの最大処理時間: 1
- GB 単位での、各クエリに割り当てられるメモリの最大サイズ: 2
- Index Join を使用する際のインデックスの最大値。言い換えれば、Index Join を使用する際にWHERE 句で使われる一意の値に基づいた、左のテーブルから返されるレコードの最大数: 20.000
AQuADataExport
AQuA API のエクスポートは、すべてのオブジェクト(テーブル)のすべてのレコードをエクスポートするように設計されています。AQuA のクエリジョブには以下の制限があります。制限
- AQuA のジョブ内のクエリが8時間以上実行されている場合、ジョブは自動的に停止されます。
- 停止されたAQuA のジョブは3回再試行可能で、その後失敗として返されます。
API Server のユーザー設定
次に、API Server 経由でZuora にアクセスするユーザーを作成します。「Users」ページでユーザーを追加・設定できます。やってみましょう。
- 「Users」ページで ユーザーを追加をクリックすると、「ユーザーを追加」ポップアップが開きます。
-
次に、「ロール」、「ユーザー名」、「権限」プロパティを設定し、「ユーザーを追加」をクリックします。

-
その後、ユーザーの認証トークンが生成されます。各ユーザーの認証トークンとその他の情報は「Users」ページで確認できます。

Zuora 用のAPI エンドポイントの作成
ユーザーを作成したら、Zuora のデータ用のAPI エンドポイントを作成していきます。
-
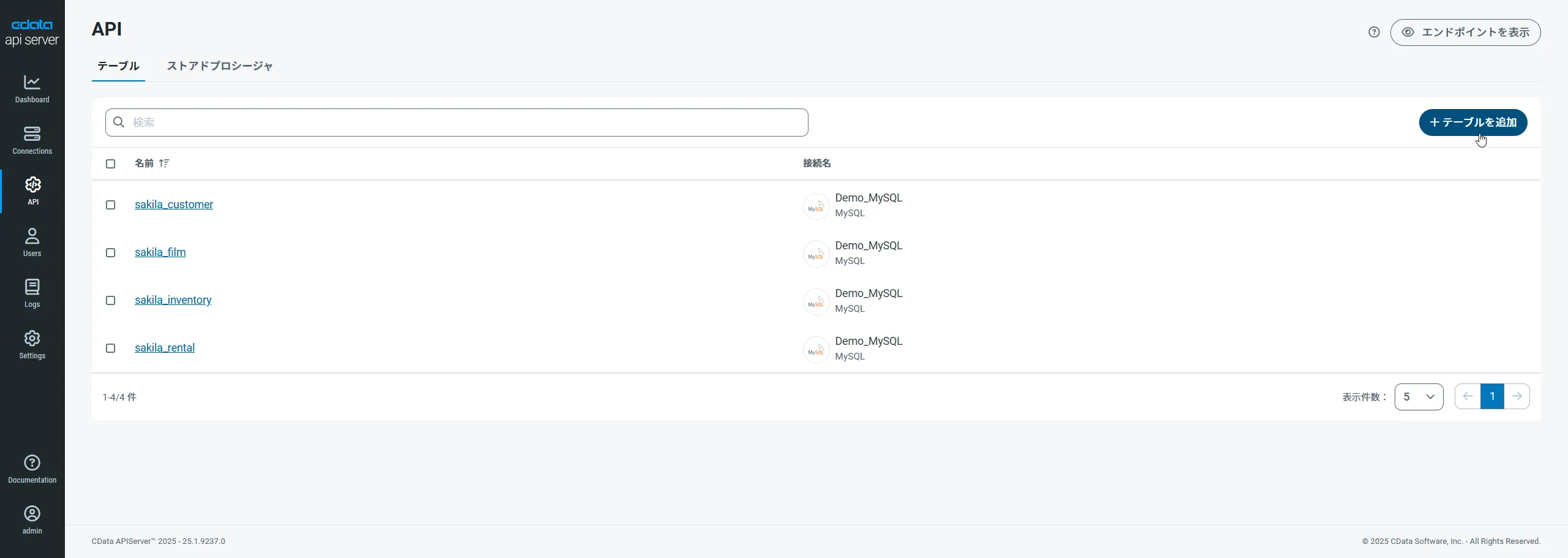
まず、「API」ページに移動し、
「 テーブルを追加」をクリックします。
-
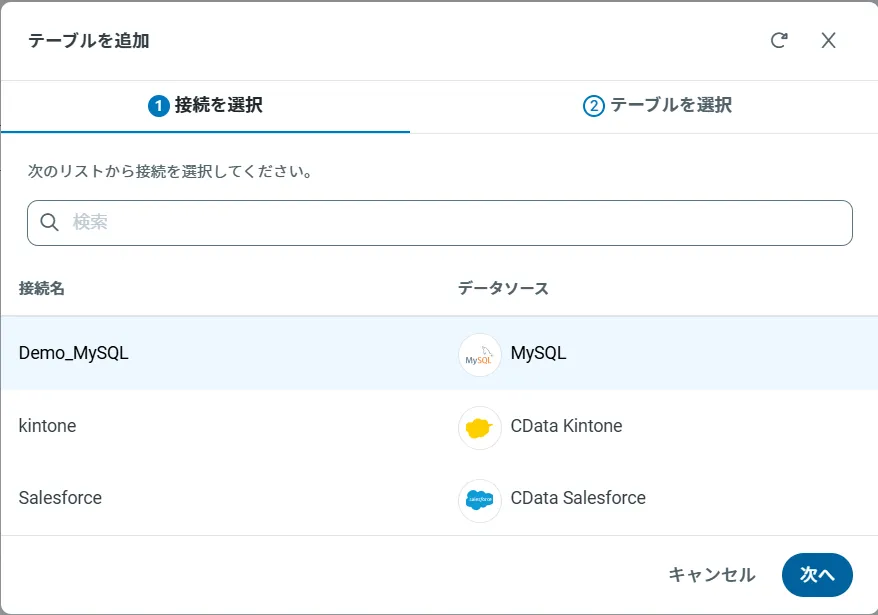
アクセスしたい接続を選択し、次へをクリックします。
-
接続を選択した状態で、各テーブルを選択して確認をクリックすることでエンドポイントを作成します。

OData のエンドポイントを取得
以上でZuora への接続を設定してユーザーを作成し、API Server でZuora データのAPI を追加しました。これで、OData 形式のZuora データをREST API で利用できます。API Server の「API」ページから、API のエンドポイントを表示およびコピーできます。

追加設定
AUTORO(旧Robotic Crowd) がクラウドサービスのため、API ServerはクラウドホスティングもしくはオンプレミスのDMZなどに配置して、AUTORO(旧Robotic Crowd) がアクセスできるように構成する必要があります。
API Server にはデフォルトでCloud Gatewayの機能も提供されているので、もしオンプレミスに配置する場合はこちらを使ってみてください。
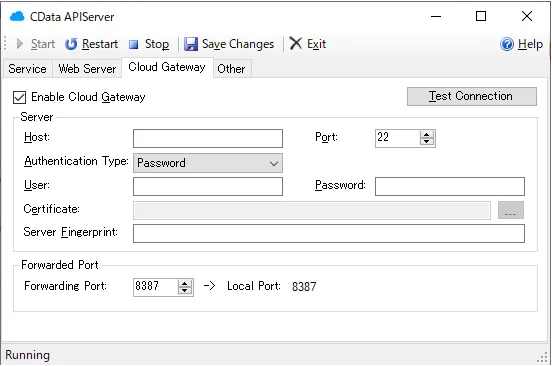
今回 AUTORO(旧Robotic Crowd) では「URL上のファイルを取得」というアクションでAPI Serverからデータを取得します。その際に、API Serverの認証はクエリパラメータによる認証方法を利用するので、「クエリ文字列パラメータとして認証トークンを使用する」の設定を有効化しておきます。なお、「HTTPリクエスト」のアクションを利用する場合は、この設定は不要です。CData API Server : Authentication
API エンドポイントができたので、確認します。「API」タブに移動すると、追加したリソースが表示されています。ここでリクエスト方法などを確認できます。
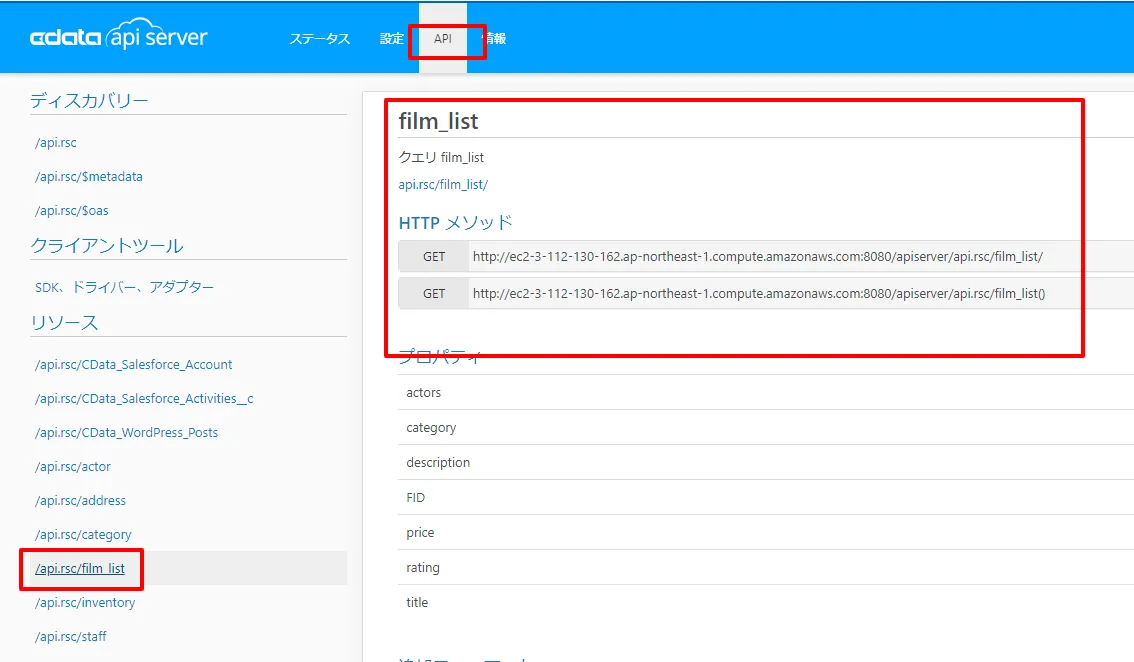
また、API Server はJSON以外にも様々なフォーマットでデータを取得できます。今回は最終的にCSVファイルをGoogle Driveにアップロードするため末尾に「?@format=csv」というパラメータを記載します。これによりCSV形式のファイルを取得できます。
オンプレミスDB やファイルからのAPI Server 使用(オプション)
オンプレミスRDB やExcel/CSV などのファイルのデータを使用する場合には、API Server のCloug Gateway / SSH ポートフォワーディングが便利です。是非、Cloud Gatway の設定方法 記事を参考にしてください。
AUTORO(旧Robotic Crowd) でZuora のデータをCSV として扱う方法
AUTORO(旧Robotic Crowd) ワークフローの作成
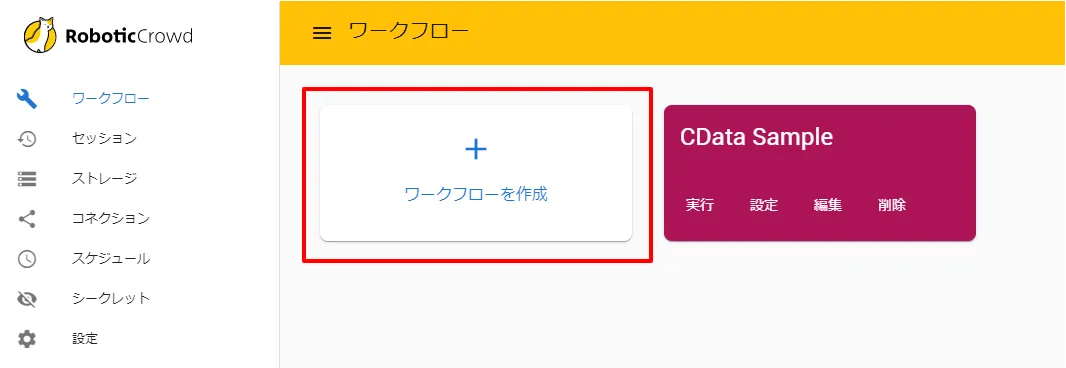
- それではワークフローを作成していきましょう。「ワークフロー」から「+ワークフローを作成」をクリックして、作業を開始します。
- 任意のワークフロー名と割当ロボットを選択し「作成」をクリックします。なお、今回は実行結果がわかりやすいように「デバッグ実行モード」をONにしています。
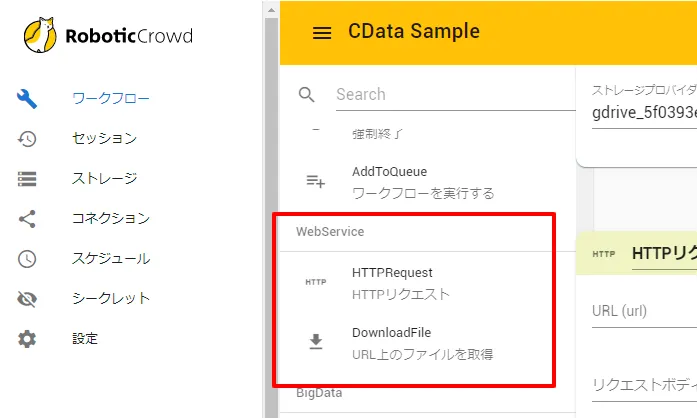
- まず、API Server経由でデータを取得するフローを構成します。 前述の通り、APIアクセス方法のアクション2種類あります。一つは「HTTPRequest」でJSONを取得したり、APIにデータを渡したりすることが可能です。 もう一つは「URL上のファイルを取得」でこれでURL先のファイルをダウンロードしてきて、処理することができます。
- CData API Serverは両方のアクションで利用が可能ですが、今回はCSVファイルを Google Driveにアップロードしたいので、「URL上のファイルを取得」を使用します。JSONなどを利用したい場合は「HTTPRequest」を利用してください。
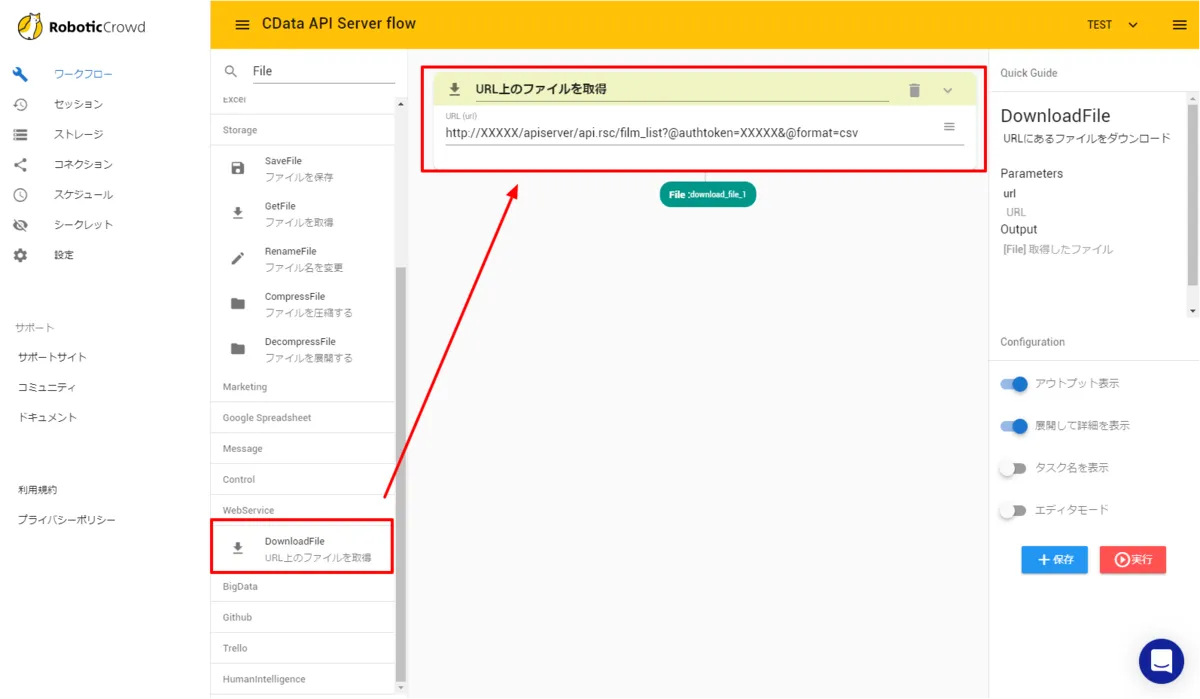
「URL上のファイルを取得」を配置し、接続先となるURLを入力します。対象のAPI ServerのURLにパラメータとして「@authoken」と「@format」をそれぞれ指定します。リソースはFilm_listとしました。
例:http://{API_SERVER_URL}/apiserver/api.rsc/film_list?@authtoken={USER_TOKEN}&@format=csv
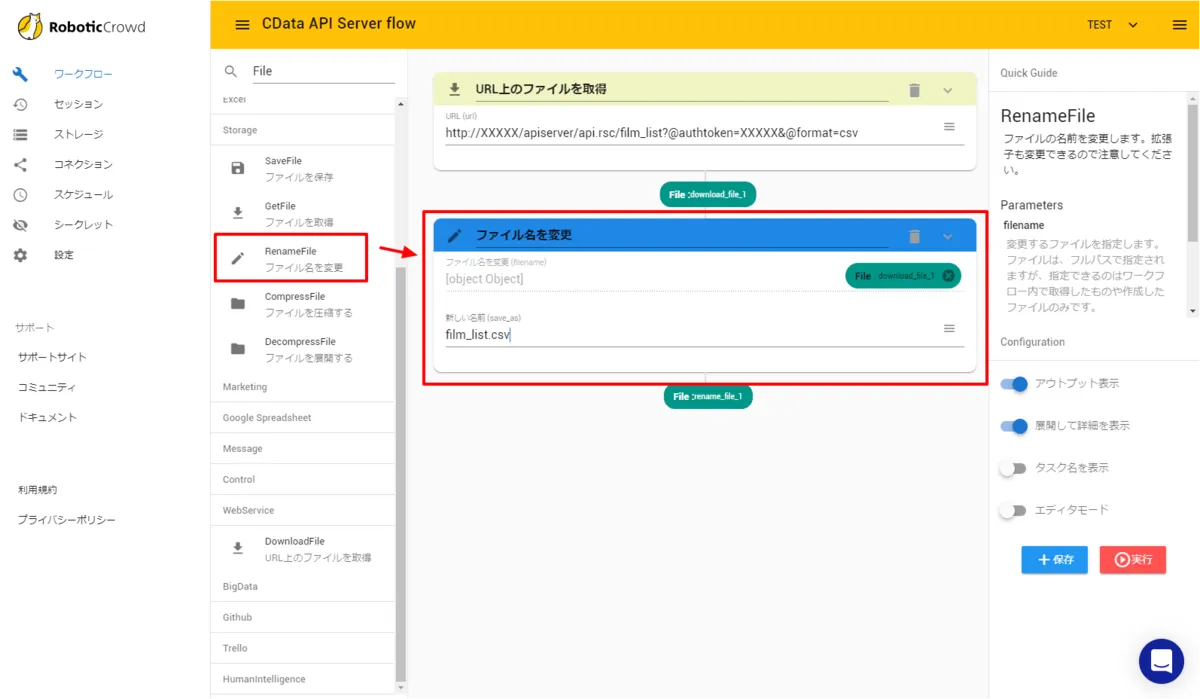
これによりCSVフォーマットでAUTORO(旧Robotic Crowd)にファイルをダウンロードできるようになります。 - ダウンロードしてきたCSVにファイル名を指定します。「RenameFile」のアクションを配置し、以下のように「film_list.csv」と入力しました。
- 最後に今回はGoogle Driveへファイルをアップロードします。「SavaFile」のアクションを配置し「ストレージプロバイダ」に別途接続したGoogle Driveの設定を入力し、アップロード先のフォルダを指定します。
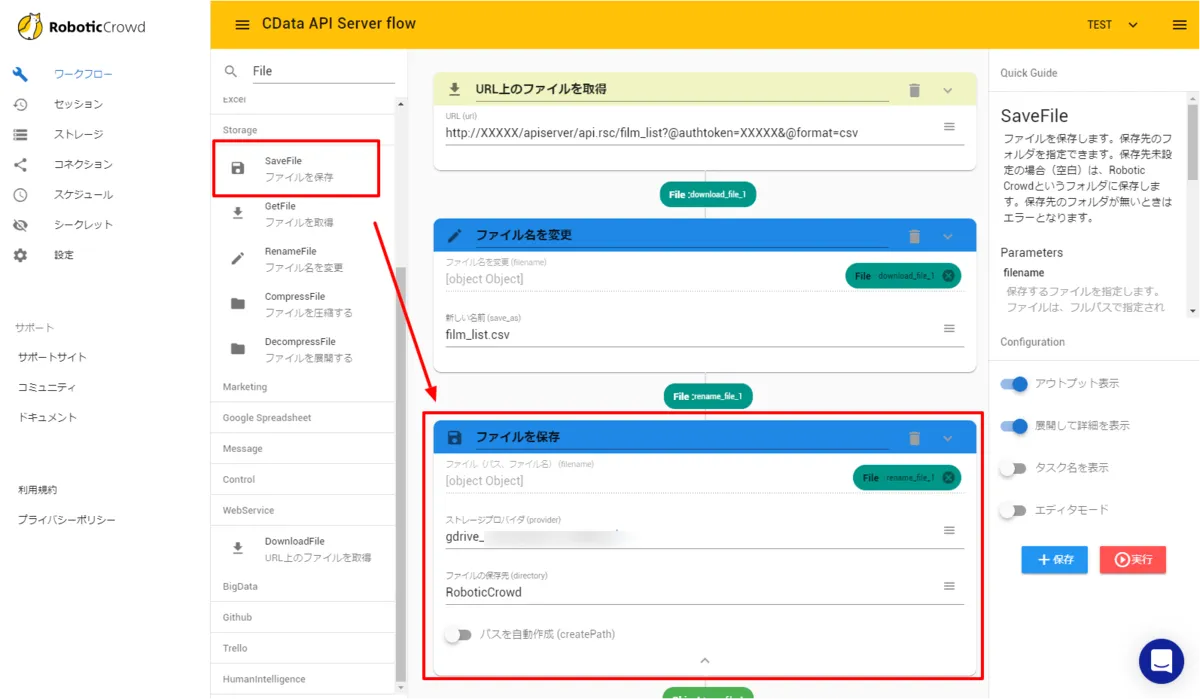
以上でワークフローの構成は完了です。あとは「保存」ボタンをクリックして「実行」してみましょう。
CData API Server の無償版およびトライアル
CData API Server は、無償版および30日の無償トライアルがあります。是非、API Server ページ から製品をダウンロードしてお試しください。