





Google Data Fusion で Teradata に連携した ETL プロセスを作成

Google Data Fusion を使用すると、セルフサービス型のデータ連携を行い、異なるデータソースを統合できます。CData JDBC Driver for Teradata をアップロードすることで、Google Data Fusion のパイプライン内から Teradata のデータ にリアルタイムでアクセスできるようになります。CData JDBC Driver を使用すると、Teradata のデータ を Google Data Fusion でネイティブにサポートされている任意のデータソースにパイプできますが、この記事では、Teradata から Google BigQuery へデータをパイプする方法を説明します。
CData JDBC Driver for Teradata を Google Data Fusion にアップロード
CData JDBC Driver for Teradata を Google Data Fusion インスタンスにアップロードして、Teradata のデータ にリアルタイムでアクセスしましょう。Google Data Fusion では JDBC ドライバーの命名規則に制限があるため、JAR ファイルを driver-version.jar という形式に合わせてコピーまたはリネームしてください。例:cdatateradata-2020.jar
- Google Data Fusion インスタンスを開きます
- をクリックしてエンティティを追加し、ドライバーをアップロードします

- "Upload driver" タブで、リネームした JAR ファイルをドラッグまたは参照します。
- "Driver configuration" タブで以下を設定します:
- Name: ドライバーの名前(cdata.jdbc.teradata)を作成し、メモしておきます
- Class name: JDBC クラス名を設定します:(cdata.jdbc.teradata.TeradataDriver)
")
- "Finish" をクリックします
Google Data Fusion で Teradata のデータ に接続
JDBC Driver をアップロードしたら、Google Data Fusion のパイプラインで Teradata のデータ にリアルタイムでアクセスできます。
- Pipeline Studio に移動して、新しいパイプラインを作成します
- "Source" オプションから "Database" をクリックして、JDBC Driver 用のソースを追加します

- Database ソースの "Properties" をクリックしてプロパティを編集します
NOTE:Google Data Fusion で JDBC Driver を使用するには、ライセンス(製品版またはトライアル)とランタイムキー(RTK)が必要です。ライセンス(またはトライアル)の取得については、CData までお問い合わせください。
- Label を設定します
- Reference Name を将来の参照用の値に設定します(例:cdata-teradata)
- Plugin Type を "jdbc" に設定します
- Connection String を Teradata の JDBC URL に設定します。例:
jdbc:teradata:RTK=5246...;User=myuser;Password=mypassword;Server=localhost;Database=mydatabase;Teradata に接続するには、次の認証情報を提供し、データベースサーバー名を指定します。
- User: Teradata ユーザーのユーザー名に設定。
- Password: Teradata ユーザーのパスワードに設定。
- DataSource: Teradata サーバー名、DBC 名、またはTDPID を指定。
- Port: サーバーが実行されているポートを指定。
- Database: データベース名を指定。指定されない場合は、CData 製品はデフォルトデータベースに接続されます。
ビルトイン接続文字列デザイナー
JDBC URL の作成には、Teradata JDBC Driver に組み込まれている接続文字列デザイナーを使用できます。JAR ファイルをダブルクリックするか、コマンドラインから JAR ファイルを実行してください。
java -jar cdata.jdbc.teradata.jar接続プロパティを入力し、接続文字列をクリップボードにコピーします。
")
- Import Query を Teradata から取得したいデータを抽出する SQL クエリに設定します。例:
SELECT * FROM NorthwindProducts

- "Sink" タブから、同期先シンクを追加します(この例では Google BigQuery を使用します)
- BigQuery シンクの "Properties" をクリックしてプロパティを編集します
- Label を設定します
- Reference Name を teradata-bigquery のような値に設定します
- Project ID を特定の Google BigQuery プロジェクト ID に設定します(またはデフォルトの "auto-detect" のままにします)
- Dataset を特定の Google BigQuery データセットに設定します
- Table を Teradata のデータ を挿入するテーブル名に設定します

Source と Sink を設定すると、Teradata のデータ を Google BigQuery にパイプする準備が整います。パイプラインを保存してデプロイしてください。パイプラインを実行すると、Google Data Fusion が Teradata からリアルタイムデータをリクエストし、Google BigQuery にインポートします。
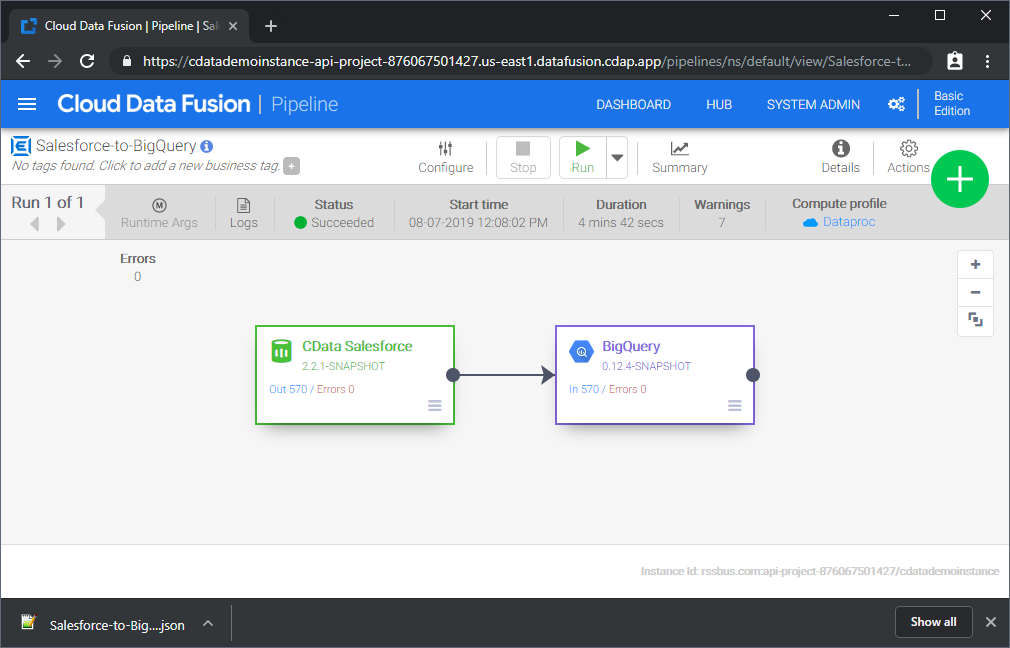
これはシンプルなパイプラインの例ですが、変換、分析、条件などを使用してより複雑な Teradata パイプラインを作成できます。CData JDBC Driver for Teradata の 30日間の無償トライアルをダウンロードして、今すぐ Google Data Fusion で Teradata のデータ をリアルタイムで活用しましょう。
はじめる準備はできましたか?
Teradata Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード