





SQL Server のデータをDatabricks にロードして分析処理を行う方法:CData JDBC Driver

Databricksは、ビッグデータの分析とAI を統合したクラウドベースのデータプラットフォームです。
通常Databricks では、Azure Blob Storage やデータレイクに存在しているCSV、JSON、Parquetなどのバイナリベースの構造データ、ないしSQL ServerやCosmos DBといったRDB・NoSQLサービスからデータを取り込んで、分析するというアプローチが多いかと思います。
しかしながら、今や分析対象となるデータソースはそういったバイナリデータやRDB・NoSQLのdataにとどまらず、SalesforceやDynamics 365といったクラウドサービス上にも数多く存在しています。そこで CData JDBC Driverを活用することにより、Databricks からシームレスにクラウドサービスのデータソースをロード、分析できるようになります。
この記事では、クラウドサービスのビッグデータ処理サービスである Databricks で CData JDBC Driverを利用してSQL Server のデータを扱う方法を紹介します。
Databricks に JDBC Driver for SQLをインストールする
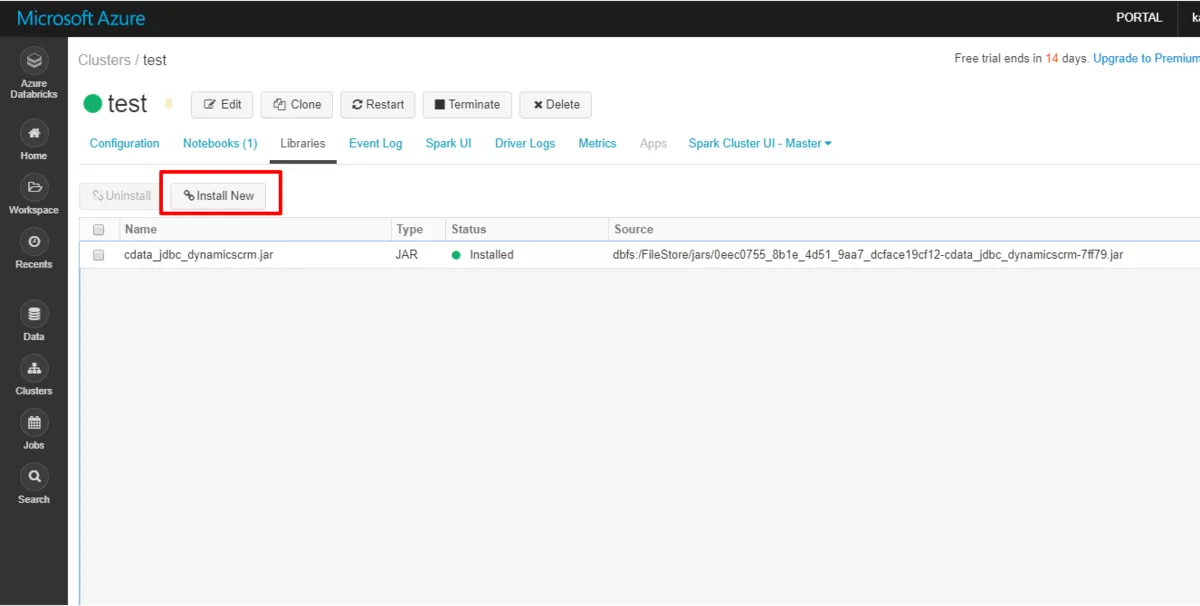
- Databricks の管理画面に移動し、対象のクラスターを選択します。
- 「Libraries」タブから「Install New」をクリックします。ここから接続に必要なJDBC jarファイルをアップロードします。
- CData JDBC ドライバのインストールディレクトリ(デフォルト:C:\Program Files\CData\CData JDBC Driver for SQL 2019J\lib)に配置されている「cdata.jdbc.sql.jar」ファイルをドラッグ・アンド・ドロップして、対象のクラスターにインストールします。

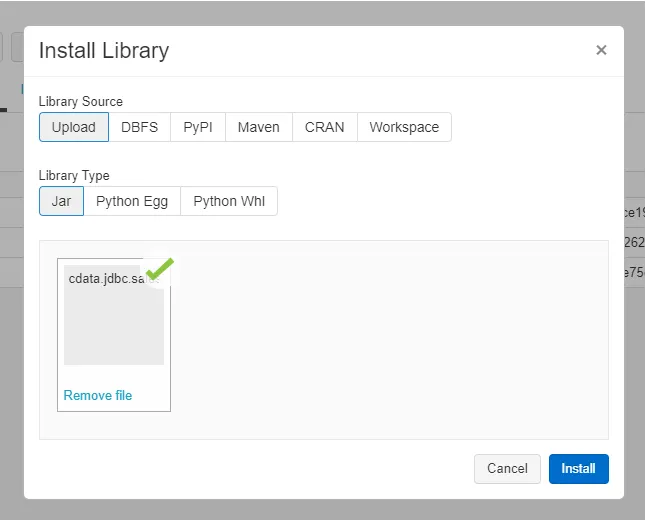
これでドライバーの配置などの準備は完了です。
Notebook で SQL Server のデータ データにアクセスする:Python
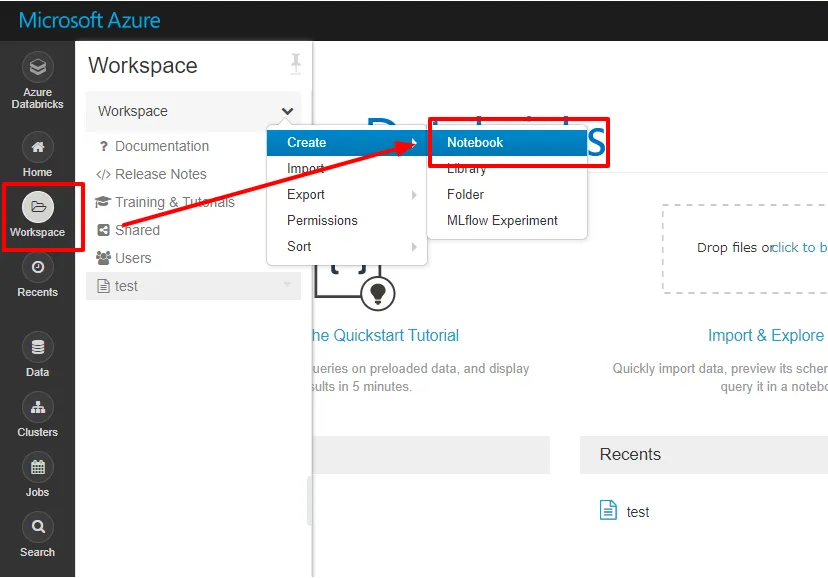
- それでは Notebook を立ち上げて、SQL Server のデータ データにアクセスしましょう。 今回は Python を使いますが、Scalaでも同様に実行可能です。
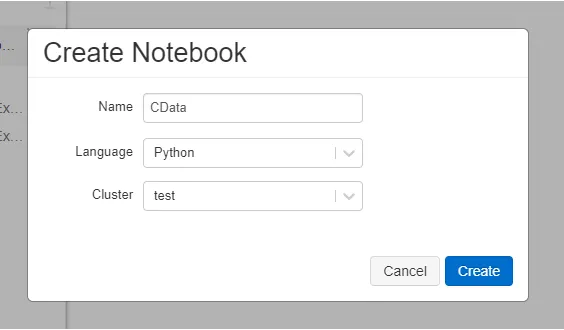
- LangauageはPythonを選択し、先程JDBCをインストールしたクラスターを選択します。
- Notebook が立ち上がったら、以下のコードをそれぞれ実行していきます。
- 最初に接続情報を定義します。 URLはSQL Server のデータ のログイン情報とセキュリティトークンを指定します。CData JDBC Driver用の特殊ライセンスをRTKとして指定します。RTK の入手方法については、CData サポートまでご連絡ください。

# Step 1: Connection Information
driver = "cdata.jdbc.sql.SQLDriver"
url = "jdbc:sql:User=myUser;Password=myPassword;Database=NorthWind;Server=myServer;Port=1433;"
table = "Orders"
# Step 2: Reading the data
remote_table = spark.read.format("jdbc")\
.option("driver", driver)\
.option("url", url)\
.option("dbtable", table)\
.load()
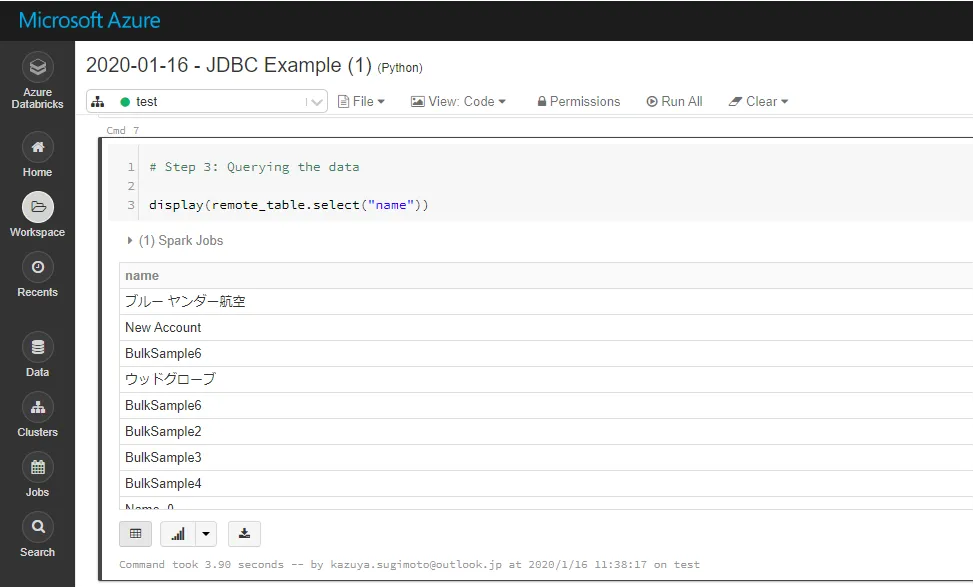
# Step 3: Querying the data
display(remote_table.select("name"))
# Step 4: (Optional) Create a view or table
remote_table.createOrReplaceTempView("SAMPLE_VIEW")
%sql
SELECT Name,AnnualRevenue FROM SAMPLE_VIEW Order by AnnualRevenue desc limit 5

なお、データフレームは対象のNotebook内だけのデータなので、他のユーザーと一緒に利用する場合はテーブルとして保存しておきましょう。
remote_table.write.format("parquet").saveAsTable("SAMPLE_TABLE")
このようにCData JDBC ドライバをアップロードすることで、簡単にDatabricks でSQL Server のデータ データをノーコードで連携し、分析に使うことが可能です。
是非、CData JDBC Driver for SQL 30日の無償評価版 をダウンロードして、お試しください。
はじめる準備はできましたか?
SQL Server Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード