





シーオーリポーツ 帳票クリエータでSpark のデータを利用した帳票を作成

シーオーリポーツ 帳票クリエータは株式会社エイチ・オー・エスが提供する帳票作成ツールです。GUI ベースで各種データソースと紐付いた帳票を作成することが可能です。
この記事では、シーオーリポーツ 帳票クリエータとCData ODBC ドライバを使って、シーオーリポーツ 帳票クリエータでSpark のデータを利用した帳票を作成する方法を紹介します。

CData ODBC ドライバとは?
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
- Spark をはじめとする、CRM、MA、会計ツールなど多様なカテゴリの270種類以上のSaaS / オンプレミスデータソースに対応
- 多様なアプリケーション、ツールにSpark のデータを連携
- ノーコードでの手軽な接続設定
- 標準 SQL での柔軟なデータ読み込み・書き込み
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.シーオーリポーツ側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData ODBC ドライバのインストールとSpark への接続設定
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
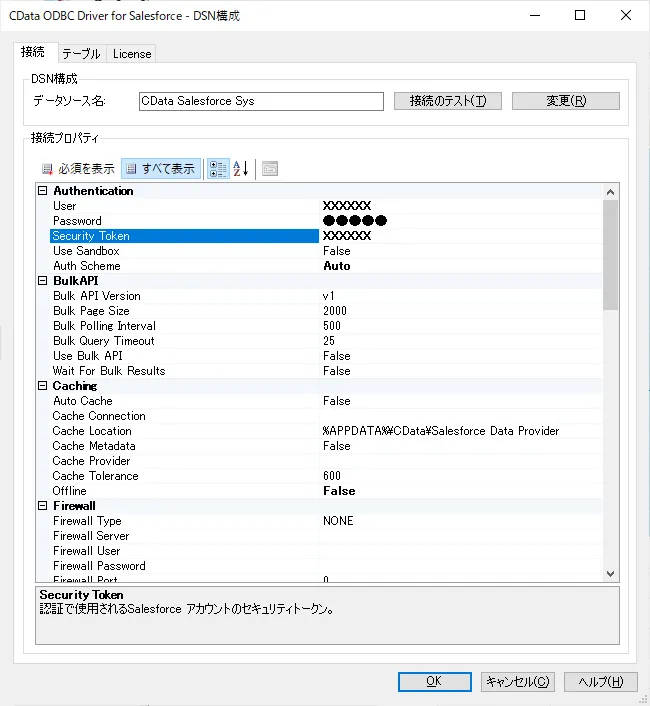
- ODBC DSN に必要な接続プロパティの値を入力します。 組み込みのMicrosoft ODBC データソースアドミニストレーターを使用してDSN を構成できます。 これは、ドライバのインストールじの最後のステップでも可能です。 Microsoft ODBC データソースアドミニストレータを使用してDSN を作成および設定する方法については、ヘルプドキュメントの「はじめに」の章を参照してください。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
- 入力後、接続テストが成功すれば設定は完了です。
フォームの作成
最初にデータをマッピングするためのベースとなるフォームを作成します。
- まず、帳票クリエータ フォームエディタを立ち上げます。
- 今回は単純に一覧を表示する帳票を作成するので、右ナビゲーションからリストフィールドをフォーム上に配置します。
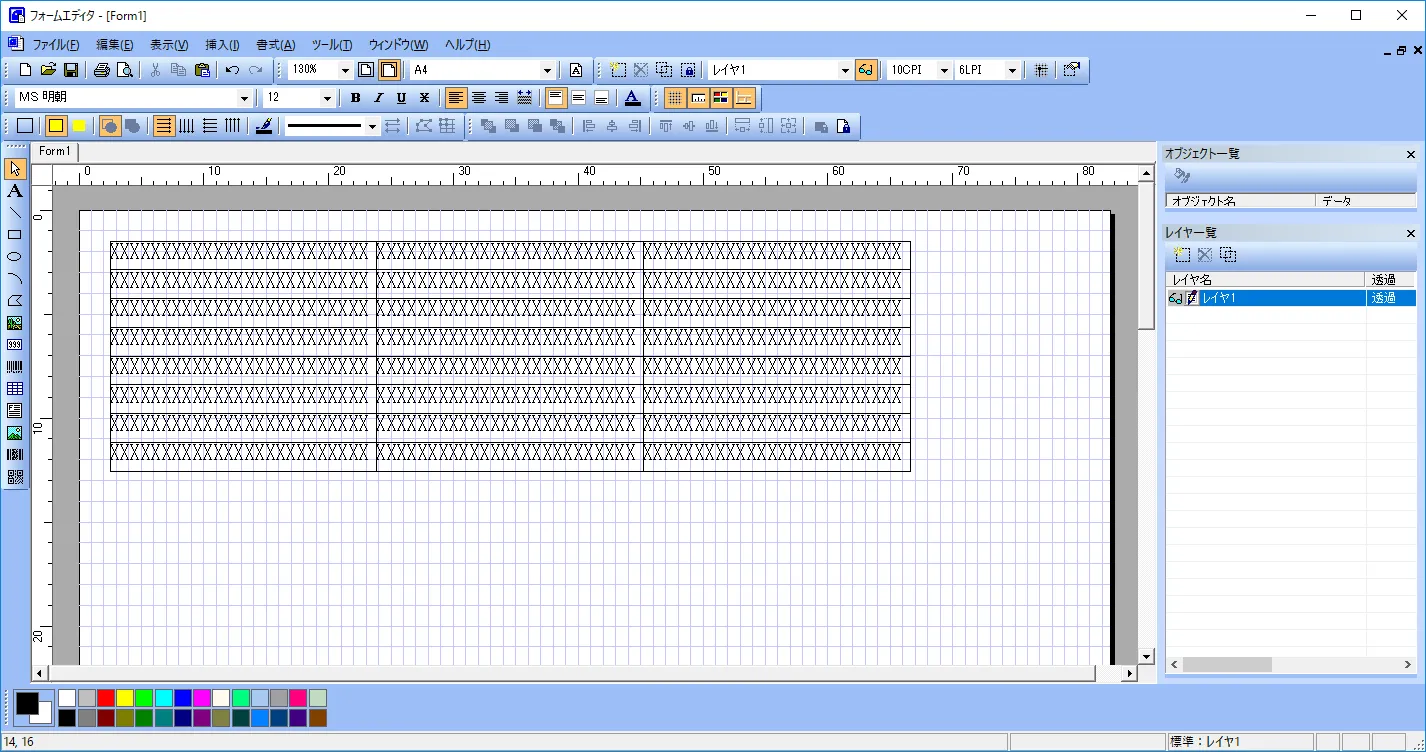
- 以下のようにフォームを作成後、保存を実行し、任意のフォルダにフォームを保存します。
マッピングの作成
次に帳票クリエータ マッピングツールを使って、事前に作成したフォームにSpark のデータをマッピングします。
- 帳票クリエータ マッピングツールを立ち上げます。
- マッピングツールの左上のリボンから「新規作成」をクリックします。
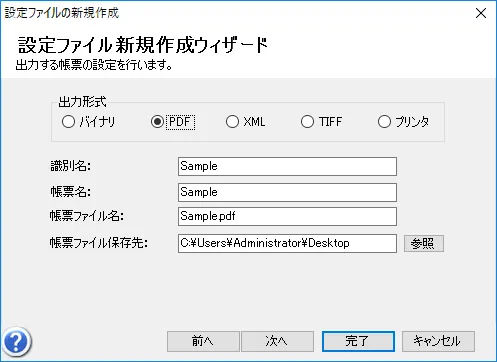
- 設定ファイル新規作成ウィザードが開始されるので、各種情報を任意の値で入力し、「参照」ボタンから先ほどのフォームを指定します。
- 次に任意の出力設定を入力し「完了」をクリックします。
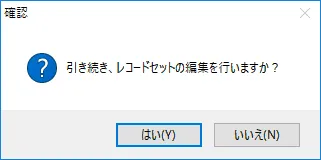
- 「引き続き、レコードセットの編集を行いますか?」というダイアログが表示されるので「はい」をクリックします。
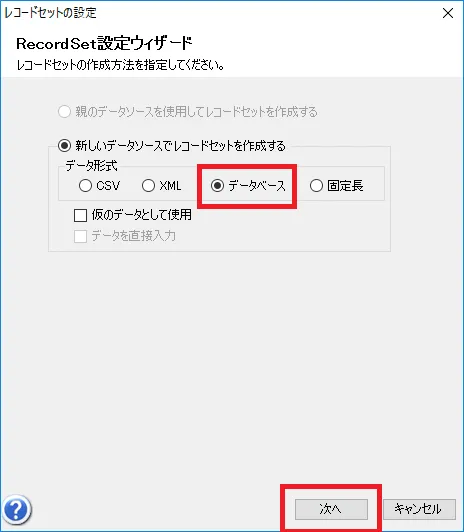
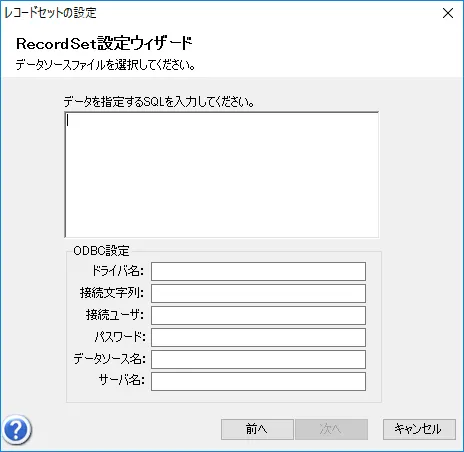
- このダイアログでCData ODBC ドライバからのデータ取得設定を行っていきます。「新しいデータソースでレコードセットを作成する」の中から「データベース」を選択し、「次へ」をクリックすると
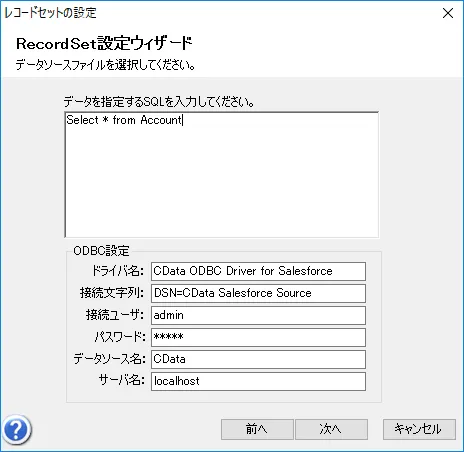
- データ取得実行時のSQL とODBC Datasource に接続するための各種プロパティ入力画面が表示されるので、下記のとおり入力を行います。
- 以下のような形で入力できればOKです。「次へ」をクリックします。
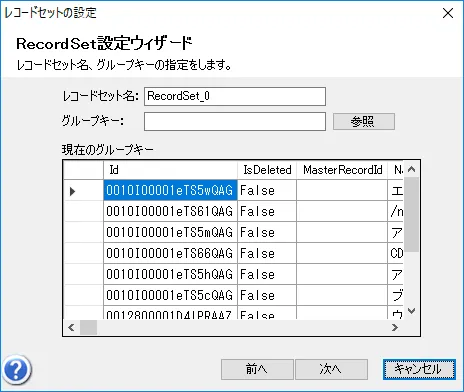
- この画面で先ほど入力したSQL を元にしたデータ取得結果のプレビューを確認できます。内容を確認し、問題がなければ「次へ」をクリックします。
- 以上でレコードセットの作成が完了します。
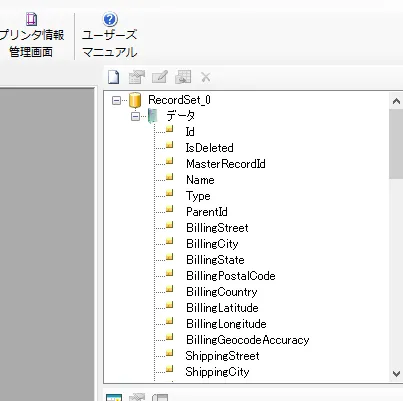
- 作成完了後、右ナビゲーションに作成されたレコードセットのカラム一覧が表示されます。
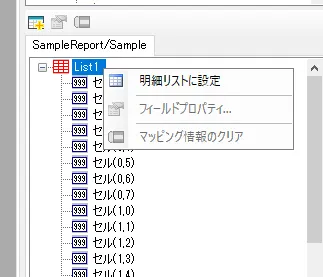
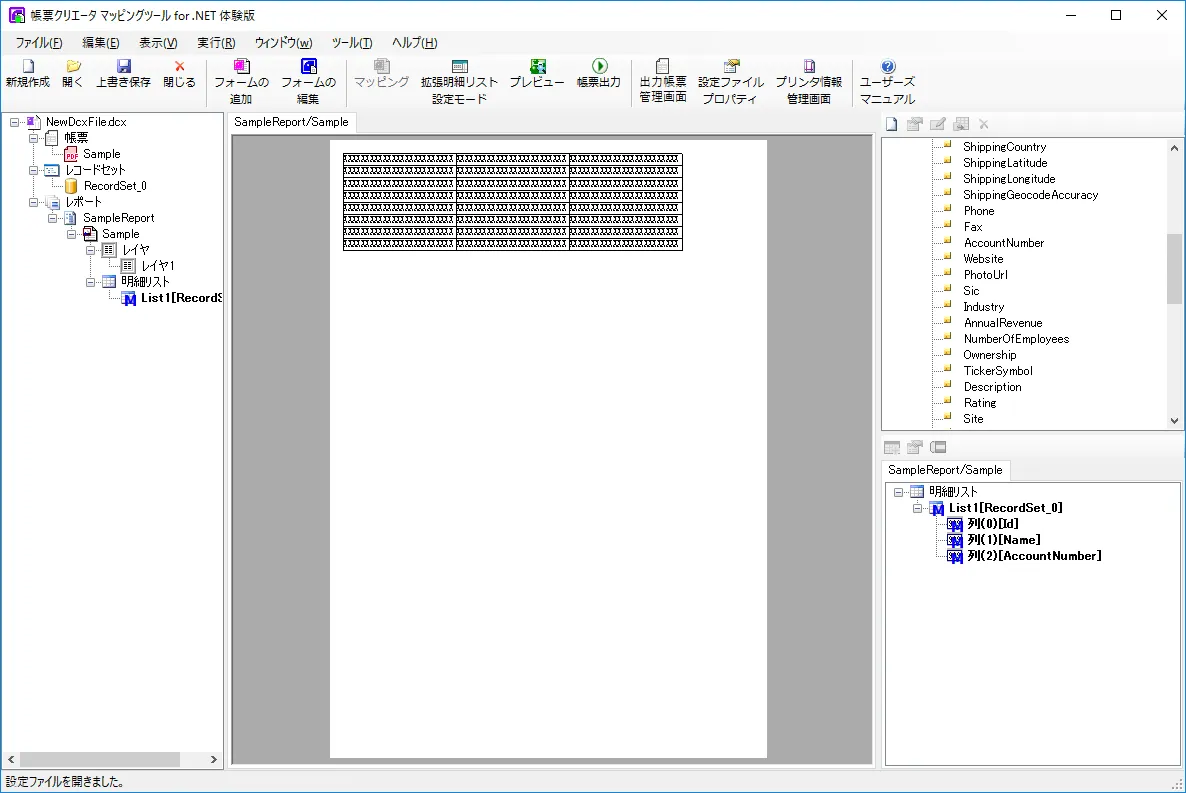
- それでは実際に各カラムをマッピングしていきたいと思います。なお、フォームで事前に作成していたリストはそのままだと各セルが独立してしまっているため、一覧表示を行う仕様になっていません。事前に対象のリストを選択し「明細リストに設定」を実行しておきましょう。
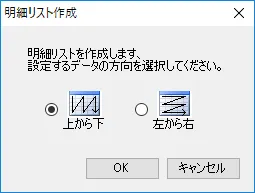
- 以下のように、「上から下」の明細リストとして設定します。
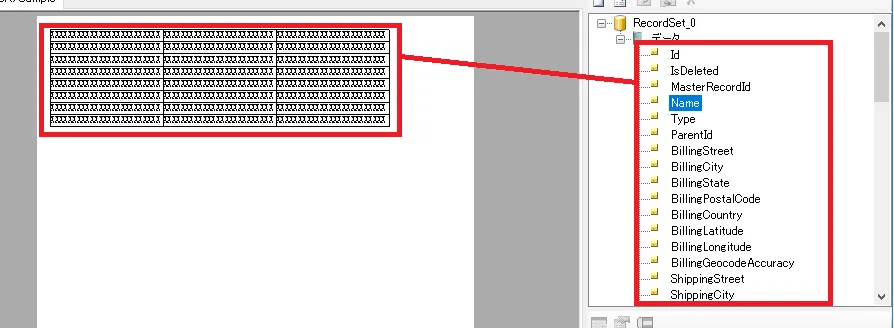
- 明細リストとして設定すると、各行に対してレコードセットをマッピングすることができるようになります。ドラッグアンドドロップで、レコードセットから各カラムを紐づけます。
- これでフォームとデータセットのマッピングが完了です。


プレビュー
それでは実際にどのように表示されるかプレビューを実行してみます。
- リボンから「プレビュー」をクリックします。
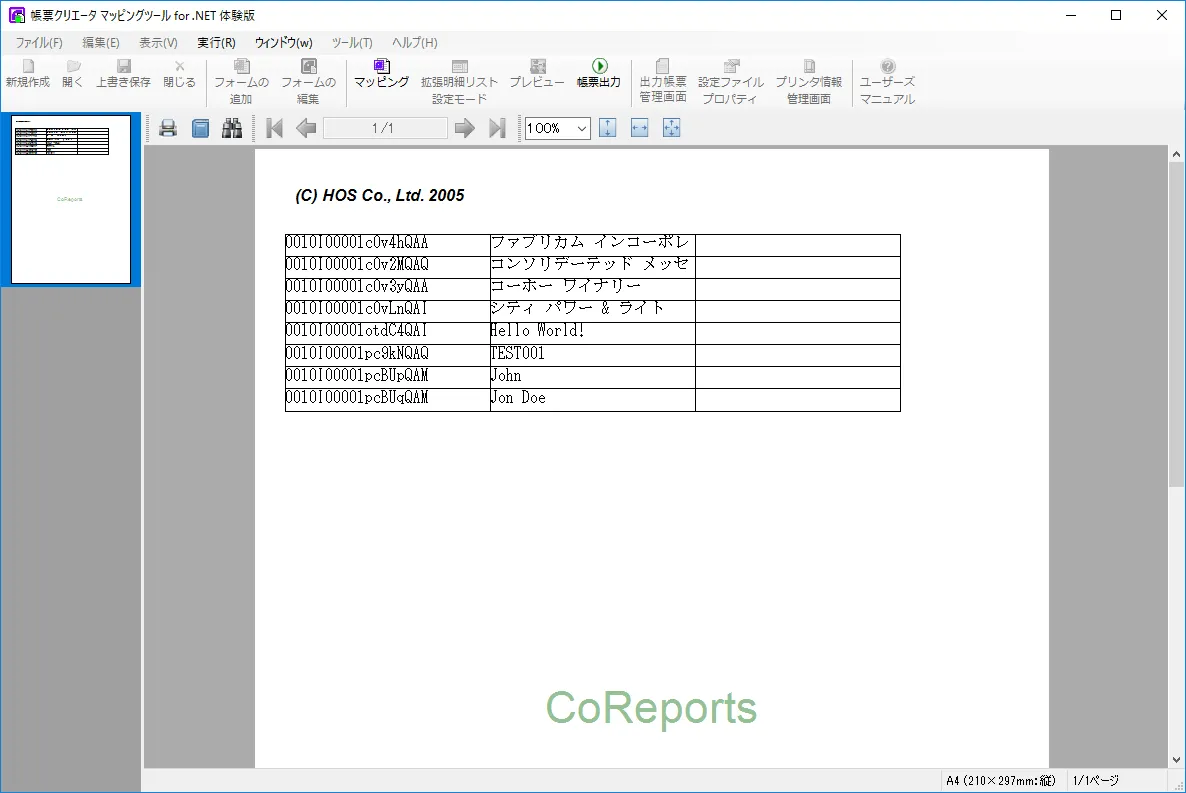
- 以下のようにプレビュー画面に切り替わり、Spark からデータが取得できていることが確認できました。
おわりに
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをシーオーリポーツからコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。
はじめる準備はできましたか?
Apache Spark ODBC Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード詳細:
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。