





Cognos BI でSpark のデータを使ってデータビジュアライゼーションを作成

CData ODBC Driver for SparkSQL を使って、Spark のデータをドラッグアンドドロップ スタイルのCognos Report Studio に連携できます。この記事では、データビジュアライゼーションをSQL を書かずに作成するグラフィカルアプローチと、Spark がサポートする任意のSQL クエリを実行する方法の両方について説明します。
CData ODBC ドライバとは?
CData ODBC ドライバは、以下のような特徴を持った製品です。
- Spark をはじめとする、CRM、MA、会計ツールなど多様なカテゴリの270種類以上のSaaS / オンプレデータソースに対応
- 多様なアプリケーション、ツールにSpark のデータを連携
- ノーコードでの手軽な接続設定
- 標準SQL での柔軟なデータ読み込み・書き込み
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.Cognos BI 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData ODBC ドライバのインストールとSpark への接続設定
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
下記の手順に従って、[Cognos Administration]ツールのライブ Spark に接続を確立します。この接続はCognos BI 全体で使えます。このドライバーを使って、すべてのユーザーは一貫したデータおよびメタデータ:リアルタイムSpark を利用できます。
-
接続プロパティの指定がまだの場合は、ODBC DSN (データソース名)で行います。Microsoft ODBC データソースアドミニストレーターを使ってODBC DSN を作成および設定できます。
64ビット版のマシンからCognos を実行している場合は、32ビット版ODBC データソースアドミニストレーターを起動する必要があります。以下のコマンドで開くことができます:
C:\Windows\sysWOW64\odbcad32.exe
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
Microsoft ODBC データソースアドミニストレーターで必要なプロパティを設定する方法は、ヘルプドキュメントの「はじめに」をご参照ください。
-
[Cognos Administration]を開いて新しいデータソースを追加します。[Data Source Connections]をクリックして[ODBC]オプションを選択したら、システム DSN とユーザーフレンドリーな名前を入力します。[Retrieve Objects]をクリックして CData Spark データベースオブジェクトを選択します。
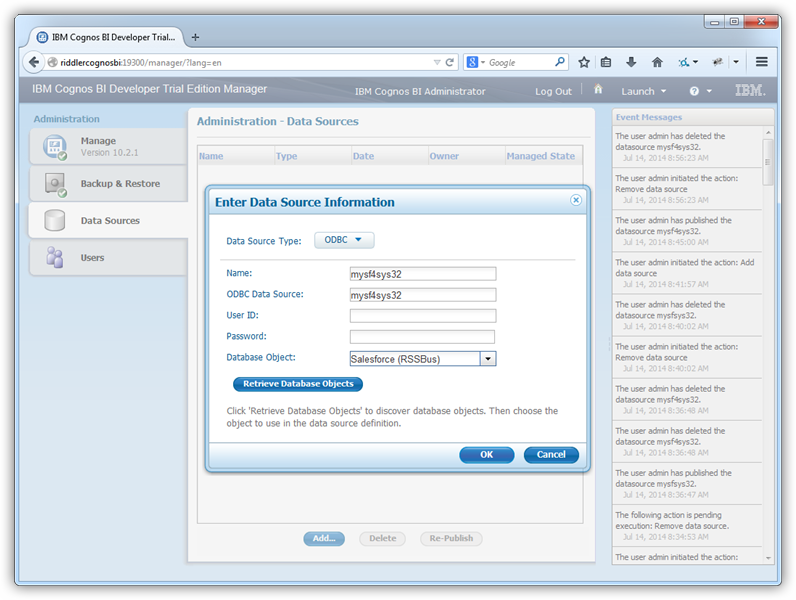
データビジュアライゼーションをレポートに追加
これで、[Source Explorer]からレポートオブジェクトにカラムをドラッグアンドドロップしてCognos Report Studio のSpark のデータ にレポートを作成できます。以下では、最新データを表示するチャートを持つシンプルなレポートを作成する方法を説明します。
レポートをビルドすると、Cognos Report Studio はSQL クエリを生成して実行をドライバーに依存します。ドライバーはクエリをSpark API へのリクエストに変換します。ドライバーはリアルタイムSpark へのクエリの実行を基になるAPI に依存します。
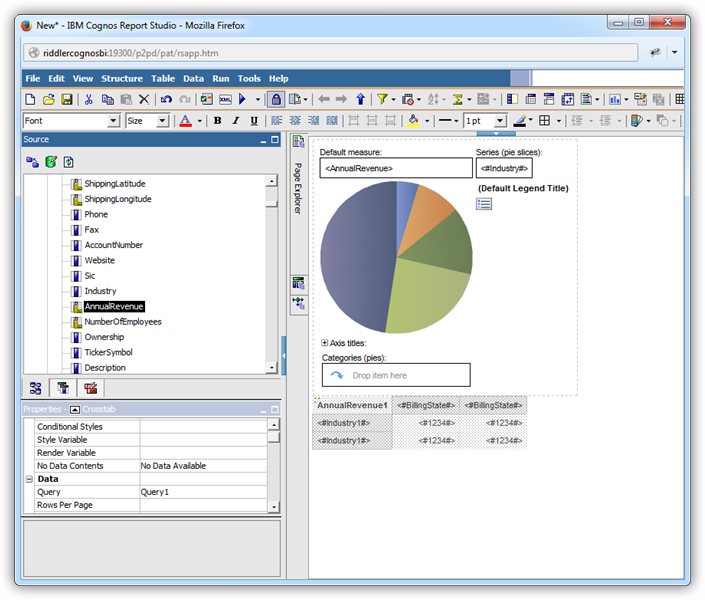
アグリゲートに基づきチャートを作成
[Source Explorer]からオブジェクトのdimentions にカラムをドラッグアンドドロップするだけで、Cognos レポートオブジェクトとしてSpark のデータを使うことができます。チャートのSeries dimension のカラムは自動的にグループ化されます。
さらにCognos は、measure dimesion のロジカルなデフォルトアグリゲート関数をデータタイプに基づいて設定します。この例では、デフォルトをオーバーライドしています。[Data Items]タブの Balance カラムをクリックしてAggregate Function プロパティを Not Applicableに設定します。Rollup Aggregate Function プロパティは Automatic に設定する必要があります。
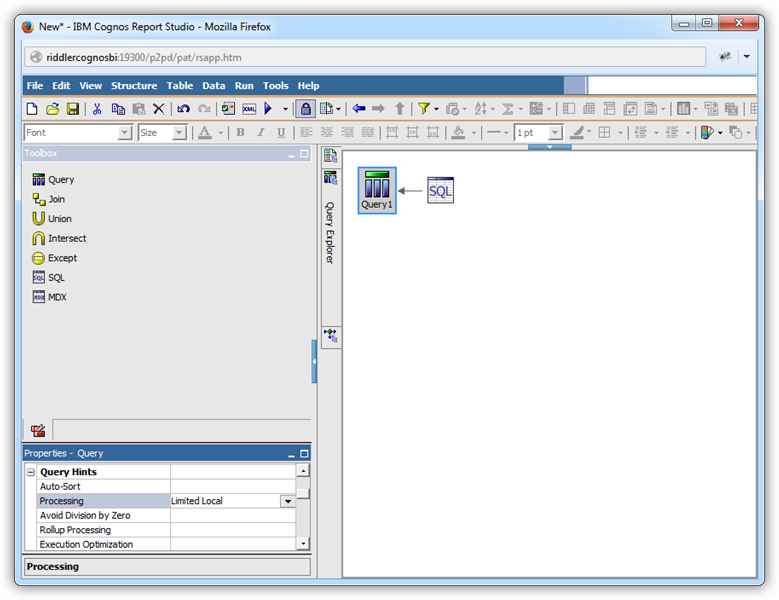
Query オブジェクトをSQL に変換
必要なクエリを把握している、あるいは生成されたクエリを調整したい場合は、query オブジェクトをSQL ステートメントに変換します。クエリがSQL に変換されると、UI コントロールはquery オブジェクトで利用できなくなります。下記の手順に従って、ユーザー定義のSQL でチャートを埋めます。
Cognos はユーザー定義クエリの実行をドライバーに依存します。ドライバーのSQL エンジンを使うと、キャッシュデータのコピーがないためクエリは常に最新の結果を返します。
- [Query Explorer]の上にカーソルを置き、[Queries]フォルダをクリックしてレポートにquery オブジェクトを表示します。
-
自動生成されたクエリを編集したい場合は、Generated SQL プロパティにあるquery オブジェクトのボタンをクリックします。ダイアログが表示されたら、[Convert]をクリックします。
新たにSQL ステートメントを入力したい場合は、query オブジェクトと一緒にSQL オブジェクトをドロップします。
- SQL オブジェクトのプロパティを編集:SQL プロパティでSpark のデータソースを選択してSQL Syntax プロパティをNative に設定します。
SQL プロパティのボタンをクリックし、ダイアログが表示されたらSQL クエリを入力します。この例では以下のクエリを使います:
SELECT City, Balance FROM Customers
query オブジェクトのプロパティを編集:Processing プロパティを[Limited Local]に設定します。この値はquery オブジェクトをSQL に変換するために必要です。
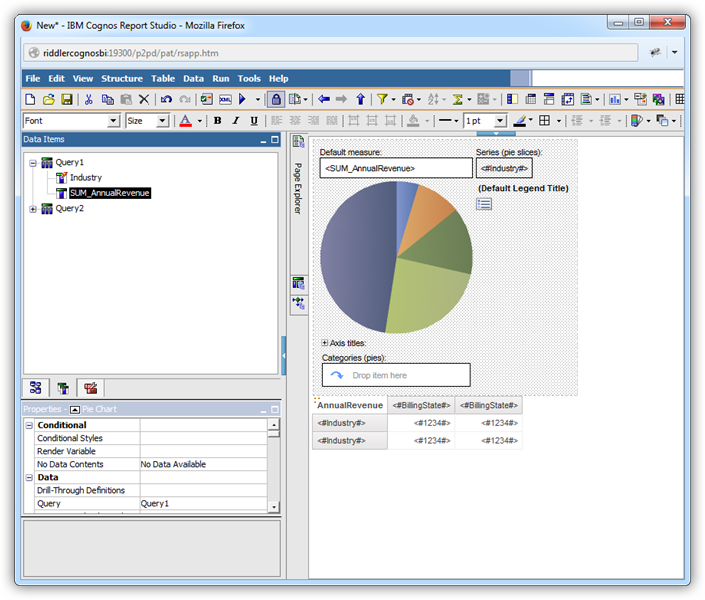
クエリ結果をチャートで使用
これで[Data Items]タブのオブジェクトとしてSQL クエリ結果にアクセスできるようになりました。下記の手順に従って、クエリ結果を使ってチャートを作成します;例えば、Customers テーブルからBalance を各City へ。
- [Page Explorer] 上にカーソルを置きpage オブジェクトをクリックしてページに戻ります。
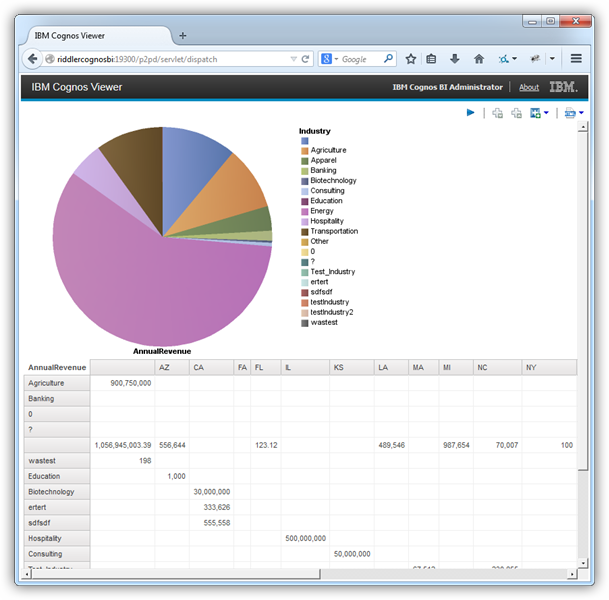
- 円グラフをツールボックスからワークスペース上にドラッグします。
- チャートのプロパティで、Query プロパティに先ほど作成したクエリの名前を設定します。
- [Data Items]タブをクリックしてカラムをx およびy 軸上にドラッグします。この例ではCity カラムをSeries (pie slices) ボックスに、Balance カラムをDefault Measure ボックスにドラッグします。
-
Default Measure (Balance 値) のデフォルトのプロパティを編集します:[Aggregate Function]ボックスで "Not Applicable" オプションを選択します。
レポートを実行してクエリ結果を追加します。
はじめる準備はできましたか?
Apache Spark ODBC Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード詳細:
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。