





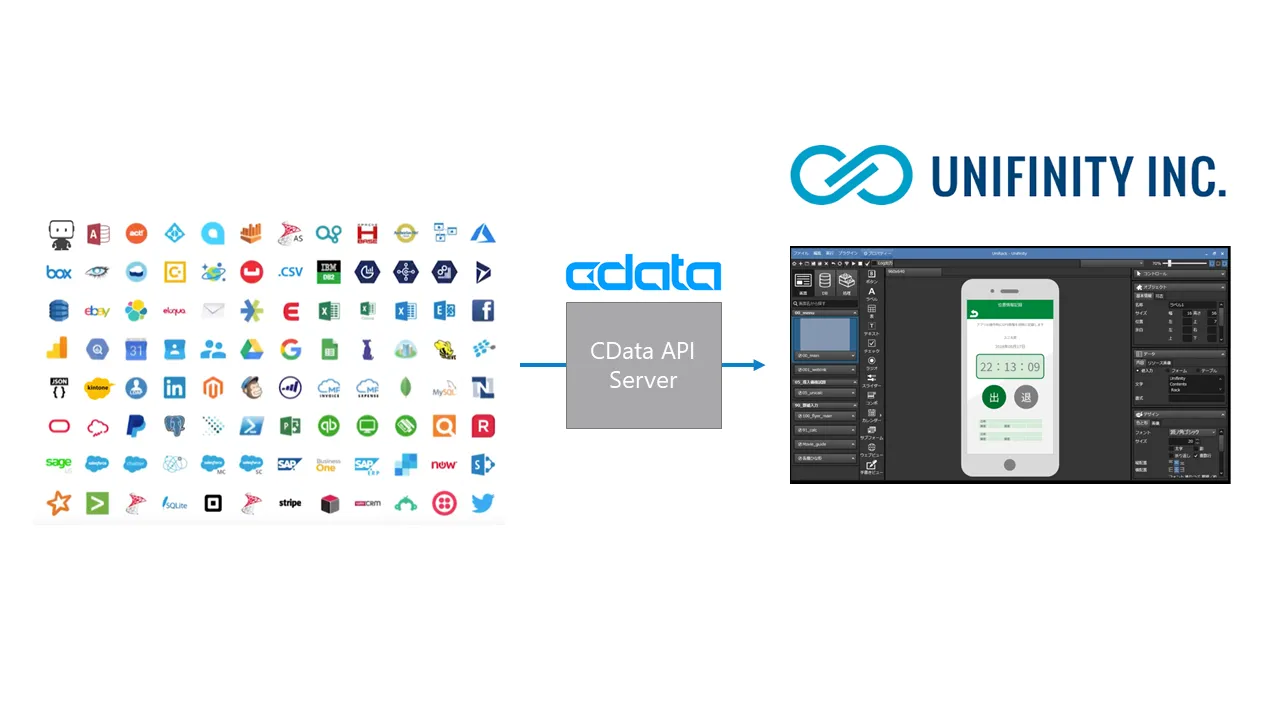
Spark のデータをモバイル開発のUnifinity で利用する方法

Unifinity は、iOS / Android / Windows のマルチOS 向けのモバイルアプリ開発が可能なプラットフォームです。Unifinity Studio という専用のツールで、UIをベースにアプリ画面をデザインしたり、DB・APIなどと連動した処理・ロジックを作成することができます。Unifinity では、REST API への接続ができるため、CData の製品を組み合わせることで対応データソースを増やすことができます。この記事では CData API Server と ADO.NET Provider for Spark を使って、Unifinity でSpark にデータ連携するモバイルアプリを開発する方法を説明します。
API Server の設定
以下のリンクからAPI Server の無償トライアルをスタートしたら、セキュアなSpark OData サービスを作成していきましょう。
Spark への接続
Unifinity からSpark のデータを操作するには、まずSpark への接続を作成・設定します。
- API Server にログインして、「Connections」をクリック、さらに「接続を追加」をクリックします。
- 「接続を追加」をクリックして、データソースがAPI Server に事前にインストールされている場合は、一覧から「Spark」を選択します。
- 事前にインストールされていない場合は、コネクタを追加していきます。コネクタ追加の手順は以下の記事にまとめてありますので、ご確認ください。
CData コネクタの追加方法はこちら >> - それでは、Spark への接続設定を行っていきましょう!
-
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
- 接続情報の入力が完了したら、「保存およびテスト」をクリックします。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
API Server のユーザー設定
次に、API Server 経由でSpark にアクセスするユーザーを作成します。「Users」ページでユーザーを追加・設定できます。やってみましょう。
- 「Users」ページで ユーザーを追加をクリックすると、「ユーザーを追加」ポップアップが開きます。
-
次に、「ロール」、「ユーザー名」、「権限」プロパティを設定し、「ユーザーを追加」をクリックします。

-
その後、ユーザーの認証トークンが生成されます。各ユーザーの認証トークンとその他の情報は「Users」ページで確認できます。

Spark 用のAPI エンドポイントの作成
ユーザーを作成したら、Spark のデータ用のAPI エンドポイントを作成していきます。
-
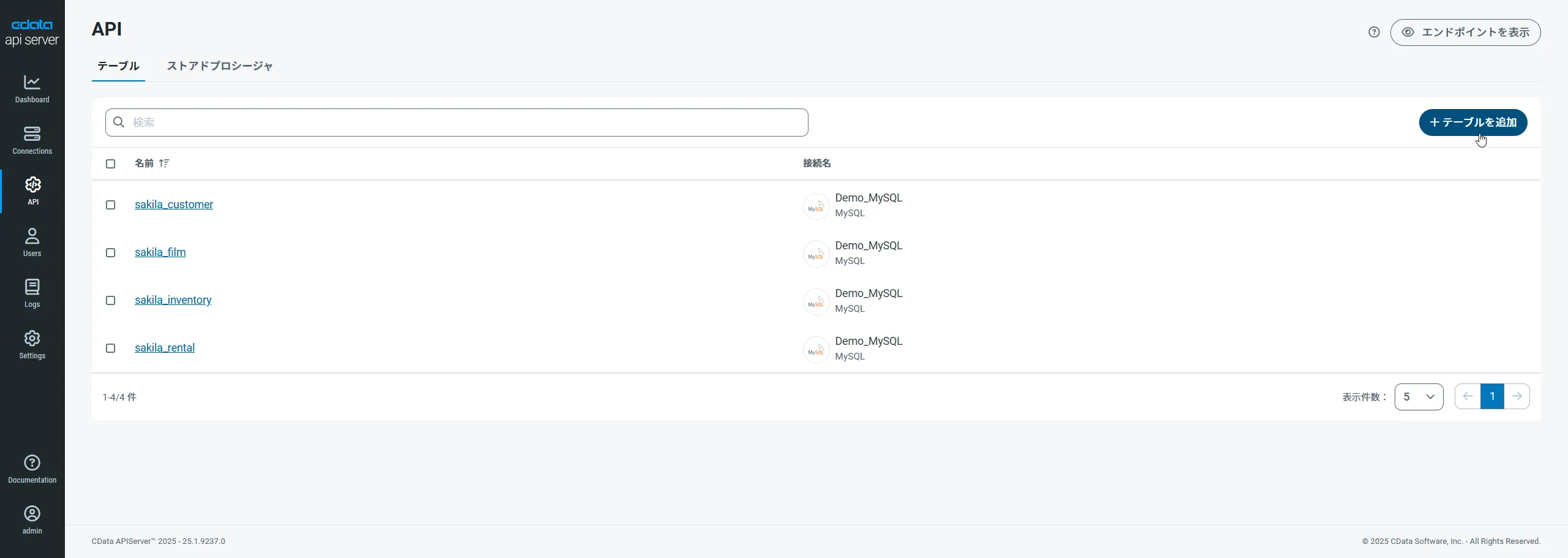
まず、「API」ページに移動し、
「 テーブルを追加」をクリックします。
-
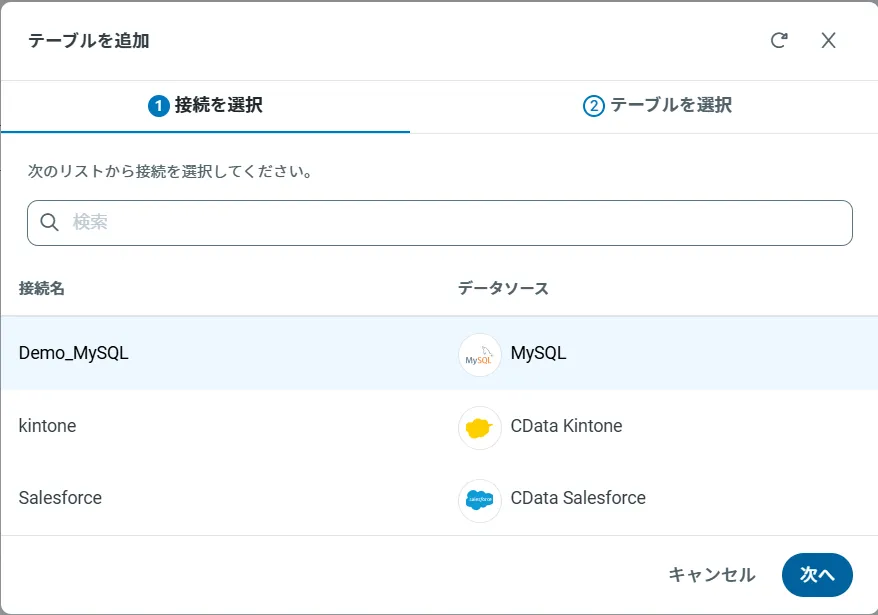
アクセスしたい接続を選択し、次へをクリックします。
-
接続を選択した状態で、各テーブルを選択して確認をクリックすることでエンドポイントを作成します。

OData のエンドポイントを取得
以上でSpark への接続を設定してユーザーを作成し、API Server でSpark データのAPI を追加しました。これで、OData 形式のSpark データをREST API で利用できます。API Server の「API」ページから、API のエンドポイントを表示およびコピーできます。

オンプレミスDB やファイルからのAPI Server 使用(オプション)
オンプレミスRDB やExcel/CSV などのファイルのデータを使用する場合には、API Server のCloug Gateway / SSH ポートフォワーディングが便利です。是非、Cloud Gatway の設定方法 記事を参考にしてください。
Unifinity でSpark のREST サービスに接続
Unifinity プロジェクトの作成
Unifinity から APIServer への接続設定をしていきます。
- Unifinity Studioを立ち上げてます。
- 新しくプロジェクトを作成します。今回は「inquiriesProject」としました。
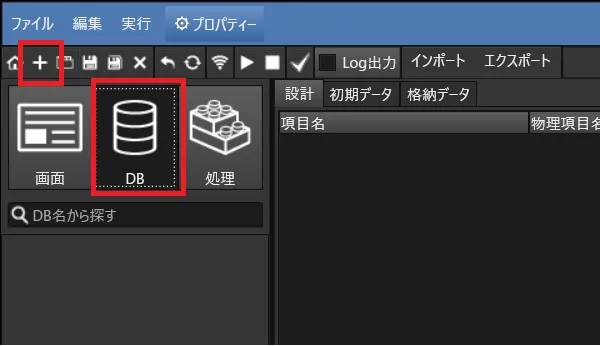
- 次に画面を作る前に、データを格納するためのDBを作ってしまいます。 DBタブを選んで、「+」ボタンでDBを追加します。名前は「inquiries」です。
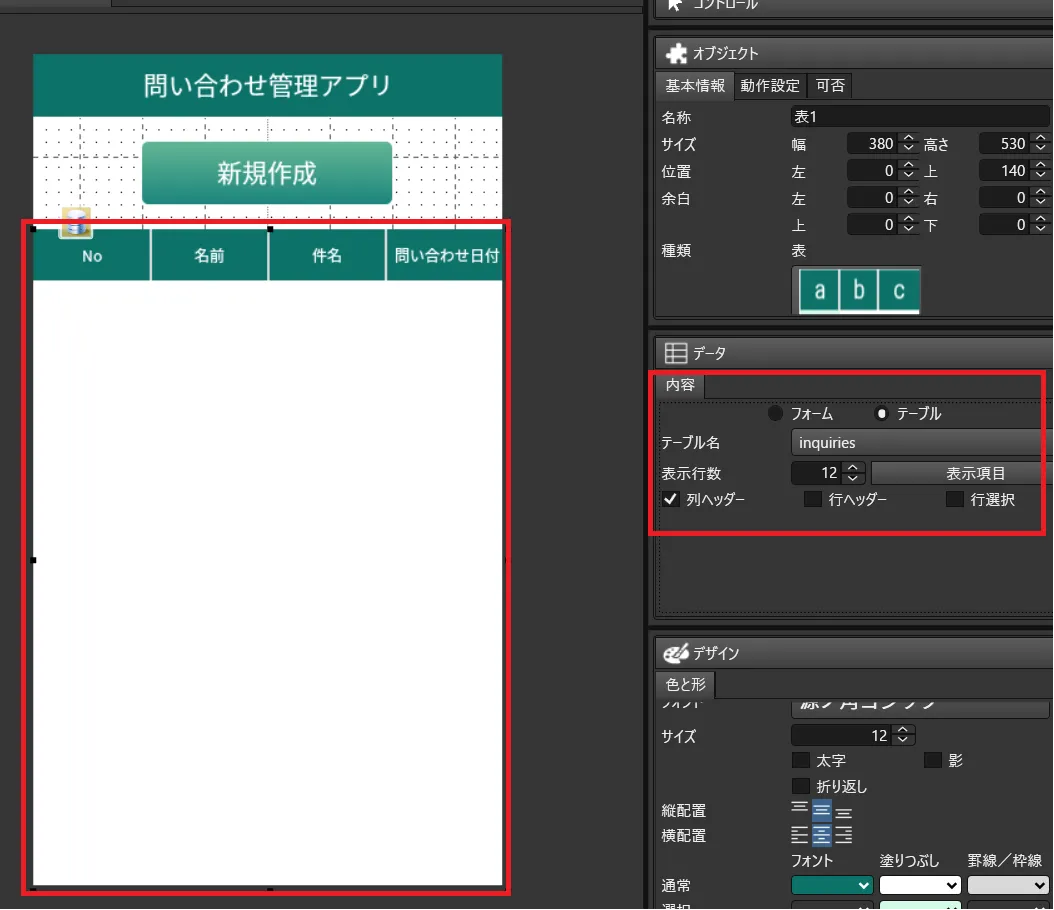
- 画面を作成します。一覧画面に表示している「表」は先程作成したDBの「inquiries」と紐付けています。
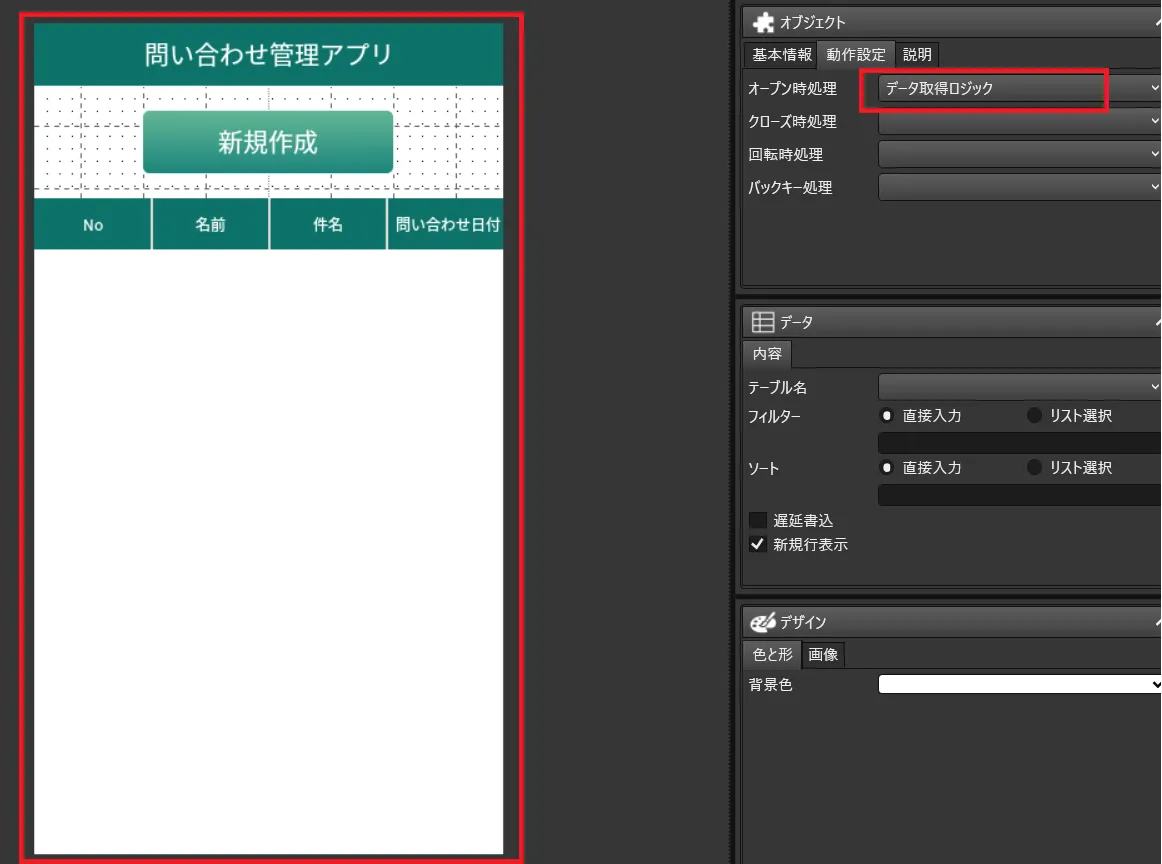
- 画面本体のオープン時の処理として後ほど解説するデータ取得ロジックを指定しています。これによって、表にデータが表示されるようになります。
- アプリの要となるロジック部分を構成します。
- 一覧画面を表示するための「データ取得ロジック」を作成します。登録・更新のロジック作成も可能です。
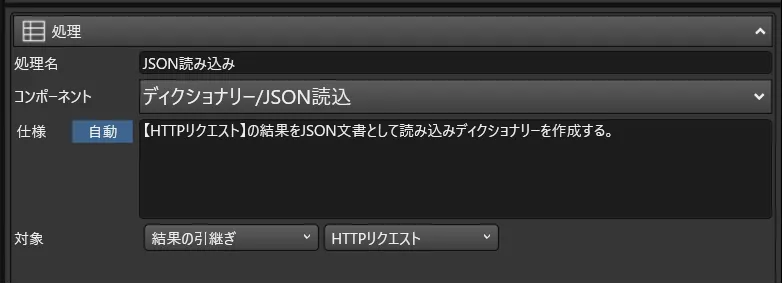
- データ取得ロジックは以下のような処理で構成されています。Cdata API Serverにリクエストを送り、そのデータをデータベースに書き込むことで一覧表示を実現しています。
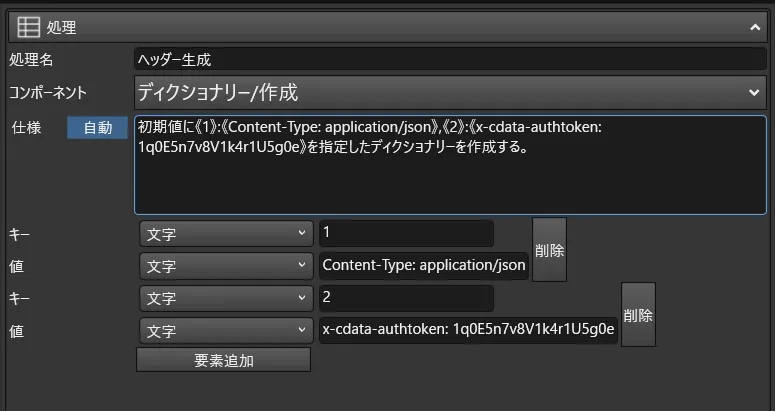
- API Serverへのリクエストには、ヘッダーで認証情報を指定する必要があります。そのため、ディクショナリー作成コンポーネントを使って、ContentTypeとともに、「x-cdata-authtoken」というプロパティで先程API Serverのユーザー作成画面で構成したToken情報を設定するようにします。
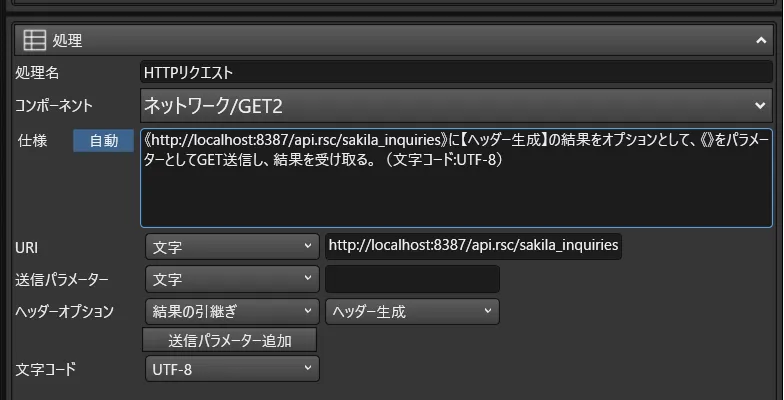
- HTTPリクエストには「ネットワーク/GET2」のコンポーネントを使用し、URIにAPI Serverのinquiriesリソースエンドポイント「例:http://localhost:8387/api.rsc/sakila_inquiries」を指定し、ヘッダーオプションに先程作成したディクショナリを指定します。
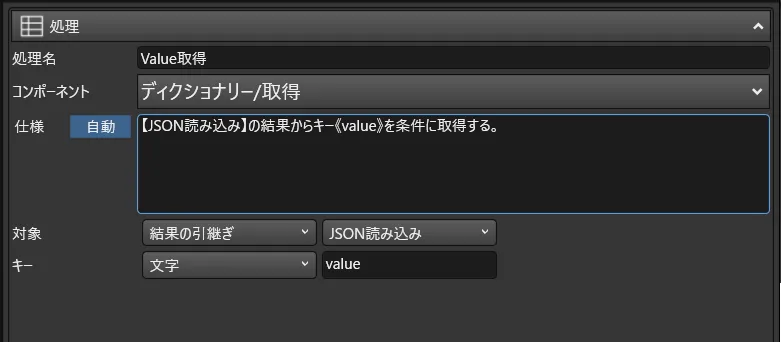
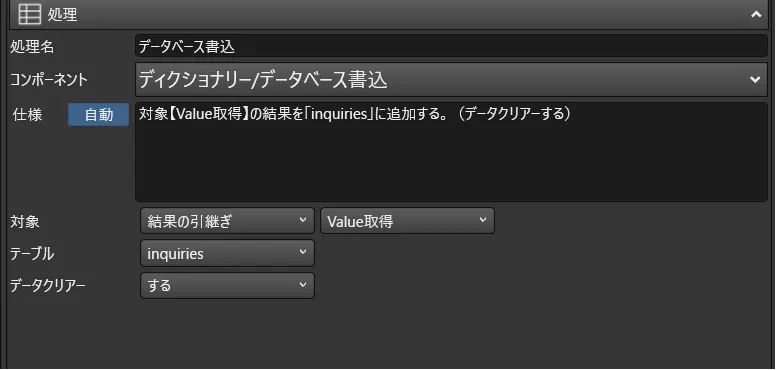
- あとはJSON構造をディクショナリに格納し、配列構造を持っている「value」の部分を読み込んだ上で、データベースに書き込みます。
- データベースに書き込む際には、予めデータクリアーをするように指定しておきます。

このように Spark 内のデータを簡単にUnifinity で作成するモバイルアプリで使用することができるようになります。
CData API Server の無償版およびトライアル
CData API Server は、無償版および30日の無償トライアルがあります。是非、API Server ページ から製品をダウンロードしてお試しください。