





CData API Server を介してPower BI でリアルタイムSpark のデータの可視化を作成

Power BI を使えば、データを美しいビジュアルに可視化したり、重要な情報を整理してダッシュボード化できます。CData API Server と組み合わせることで、可視化やダッシュボードなどのためにSpark のデータを使用できます。この記事では、CData API Server を使用してSpark の仮想データベースを作成し、Spark のデータを使ったレポートをPower BI で作成する方法を説明します。
API Server の設定
以下のリンクからAPI Server の無償トライアルをスタートしたら、セキュアなSpark OData サービスを作成していきましょう。
Spark への接続
Power BI からSpark のデータを操作するには、まずSpark への接続を作成・設定します。
- API Server にログインして、「Connections」をクリックします。

- 「接続を追加」をクリックして、データソースがAPI Server に事前にインストールされている場合は、一覧から「Spark」を選択します。
- 事前にインストールされていない場合は、「インストール済み」のチェックマークを外します。その後、一覧から「Spark」を検索して「コネクタをインストール」をクリックしてください。

- インストールできたら、接続設定を行っていきましょう!

-
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
- 接続情報の入力が完了したら、「保存およびテスト」をクリックします。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
API Server のユーザー設定
次に、API Server 経由でSpark にアクセスするユーザーを作成します。「Users」ページでユーザーを追加・設定できます。やってみましょう。
- 「Users」ページで ユーザーを追加をクリックすると、「ユーザーを追加」ポップアップが開きます。
-
次に、「ロール」、「ユーザー名」、「権限」プロパティを設定し、「ユーザーを追加」をクリックします。

-
その後、ユーザーの認証トークンが生成されます。各ユーザーの認証トークンとその他の情報は「Users」ページで確認できます。

Spark 用のAPI エンドポイントの作成
ユーザーを作成したら、Spark のデータ用のAPI エンドポイントを作成していきます。
-
まず、「API」ページに移動し、
「 テーブルを追加」をクリックします。

-
アクセスしたい接続を選択し、次へをクリックします。

-
接続を選択した状態で、各テーブルを選択して確認をクリックすることでエンドポイントを作成します。

OData のエンドポイントを取得
以上でSpark への接続を設定してユーザーを作成し、API Server でSpark データのAPI を追加しました。これで、OData 形式のSpark データをREST API で利用できます。API Server の「API」ページから、API のエンドポイントを表示およびコピーできます。

Power BI からSpark のデータを取得
以下のステップを実行して、Power BI から作成したOData エンドポイントに接続します。
-
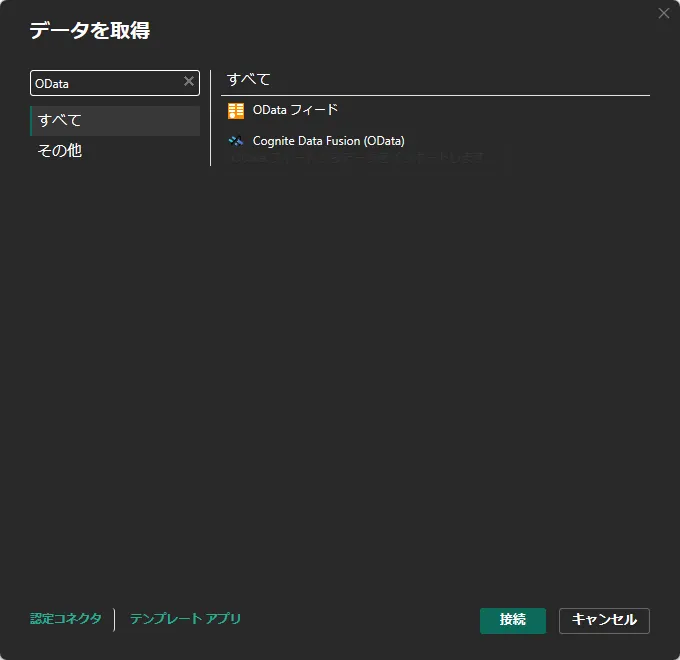
「Power BI Desktop」を開いて「データを取得」画面を表示します。検索ボックスに「odata」と入力すると「OData フィード」が表示されるので、これを選択して「接続」をクリックします。
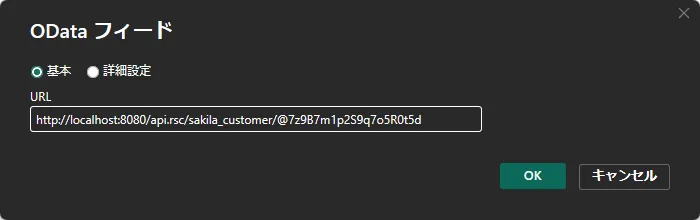
「OData フィード」の接続画面で、先ほど作成したテーブルのエンドポイントに認証トークンを付加したURLを指定します。以下の形式です。
https:///api.rsc//@/接続できるテーブルは、API Server のhttps://<ホスティング先>/api.rstで確認できます。
Spark のデータの可視化を作成
Power BI にデータを接続したら、「フィールド」ペインのフィールドをキャンバスにドラッグすることで、レポートビューにデータを可視化できます。図表の種類と、ビジュアライズするディメンションおよびメジャーを選択します。

「更新」をクリックしてデータの変更をレポートに同期します。
データアプリケーションからSpark のデータへのSQL アクセス
以上で、CData API Server を使用してPower BI からSpark のデータに接続できるようになりました。これで、Spark のデータを複製することなく多くのデータをインポートしたり、新しい可視化やレポートを作成することができます。
オンプレミスのBI やレポート、ETL、その他のデータアプリケーションから、250を超えるSaaS、ビッグデータ、NoSQL データソース(Spark を含む)への直接のSQL データにアクセスするには、CData API Server のページにアクセスして無料トライアルをダウンロードしてください。