





Power Automate の自動タスクで CData API Server およびSpark ADO.NET Provider を使う

Power Automate (旧Microsoft Flow) は、オンプレやクラウドの複数のシステムからのデータを含むタスクを自動化することができます。CData API Server を使用すると、ユーザーはPower Automate のSpark トリガーに基づくアクションのネイティブな作成が可能になります。API Server は、Power Automate などのSaaS アプリケーションを、OData やSwagger などのデータアクセス標準を通じてSpark とシームレスに統合できます。この記事では、Power Automate のウィザードとSpark API Server を使い、検索条件に一致するエンティティであるトリガーを作成し、結果に基づいて電子メールを送信する方法を示します。
API Server の設定
以下のリンクからAPI Server の無償トライアルをスタートしたら、セキュアなSpark OpenAPI サービスを作成していきましょう。
Spark への接続
Power Automate からSpark のデータを操作するには、まずSpark への接続を作成・設定します。
- API Server にログインして、「Connections」をクリック、さらに「接続を追加」をクリックします。
- 「接続を追加」をクリックして、データソースがAPI Server に事前にインストールされている場合は、一覧から「Spark」を選択します。
- 事前にインストールされていない場合は、コネクタを追加していきます。コネクタ追加の手順は以下の記事にまとめてありますので、ご確認ください。
CData コネクタの追加方法はこちら >> - それでは、Spark への接続設定を行っていきましょう!
-
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
- 接続情報の入力が完了したら、「保存およびテスト」をクリックします。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
API Server のユーザー設定
次に、API Server 経由でSpark にアクセスするユーザーを作成します。「Users」ページでユーザーを追加・設定できます。やってみましょう。
- 「Users」ページで ユーザーを追加をクリックすると、「ユーザーを追加」ポップアップが開きます。
-
次に、「ロール」、「ユーザー名」、「権限」プロパティを設定し、「ユーザーを追加」をクリックします。

-
その後、ユーザーの認証トークンが生成されます。各ユーザーの認証トークンとその他の情報は「Users」ページで確認できます。

Spark 用のAPI エンドポイントの作成
ユーザーを作成したら、Spark のデータ用のAPI エンドポイントを作成していきます。
-
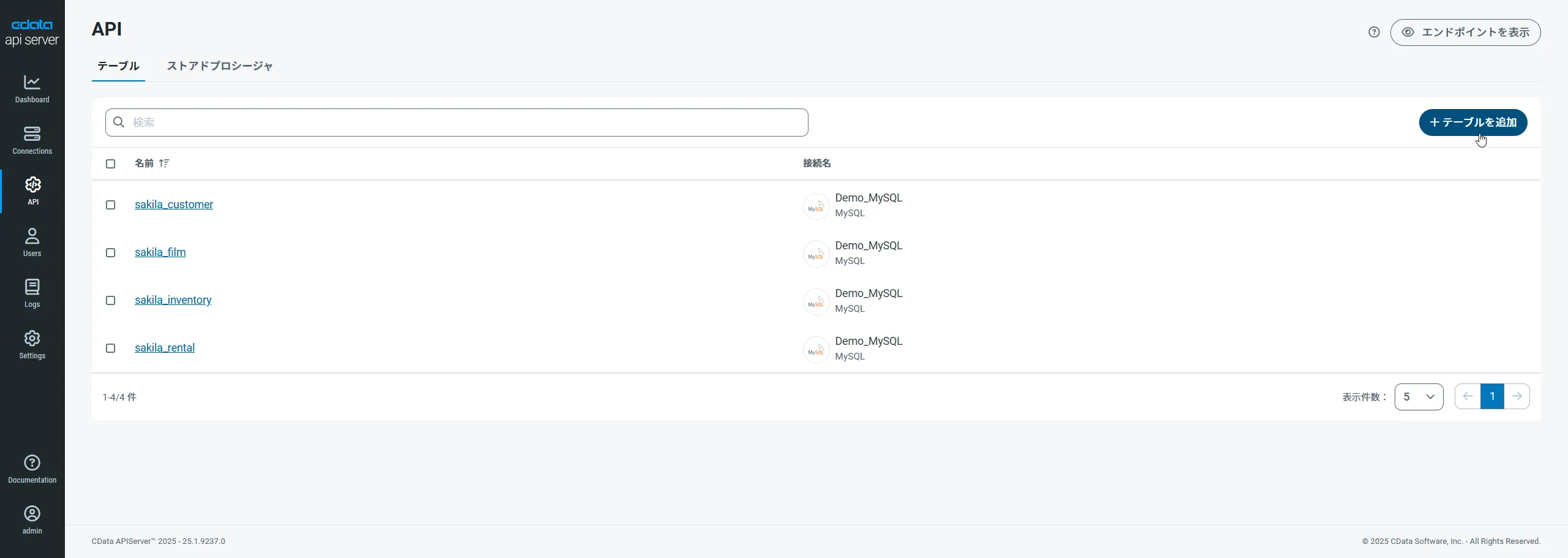
まず、「API」ページに移動し、
「 テーブルを追加」をクリックします。
-
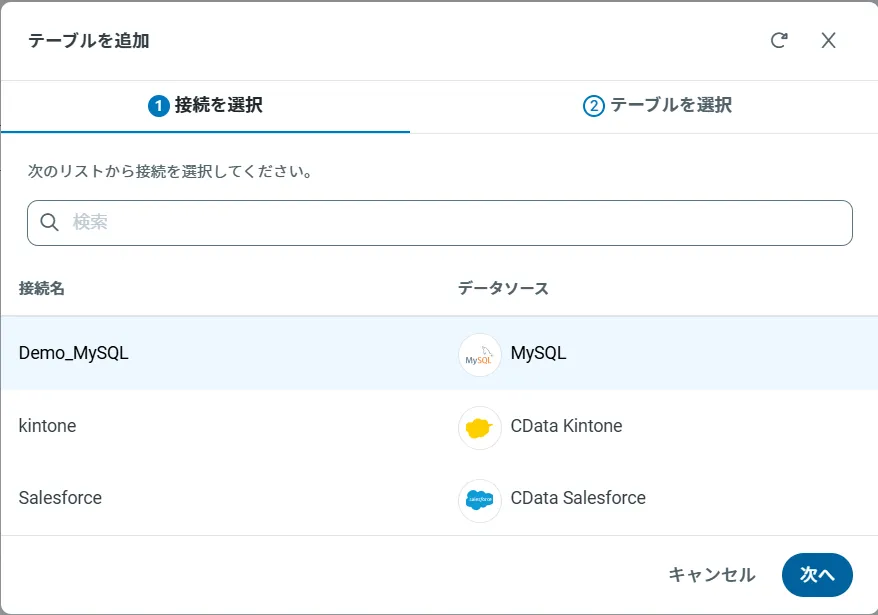
アクセスしたい接続を選択し、次へをクリックします。
-
接続を選択した状態で、各テーブルを選択して確認をクリックすることでエンドポイントを作成します。

OpenAPI のエンドポイントを取得
以上でSpark への接続を設定してユーザーを作成し、API Server でSpark データのAPI を追加しました。これで、OpenAPI 形式のSpark データをREST API で利用できます。API Server の「API」ページから、API のエンドポイントを表示およびコピーできます。

SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
また、CORS を有効にし、[Settings]->[Server]ページで次のセクションを定義する必要があります。[*]なしですべてのドメインを許可するオプションを選択することもできます。
- Access-Control-Allow-Origin:[*]の値に設定するか、接続を許可するドメインを指定します。
- Access-Control-Allow-Methods:値を[GET,PUT,POST,OPTIONS]に設定します。
- Access-Control-Allow-Headers:[x-ms-client-request-id, authorization, content-type]に設定します。
簡単にするために、API ユーザーの認証トークンをURL で渡すことができます。データディレクトリにあるsettings.cfg ファイルの[Application]セクションに設定を追加する必要があります。Windows でこれは、アプリケーションルートのapp_data サブフォルダにあたります。Java エディションでは、データディレクトリの場所はオペレーティングシステムによって異なります。
- Windows:C:\ProgramData\CData
- Unix or Mac OS X: ~/cdata
[Application] AllowAuthtokenInURL = true
Spark のデータをPower Automate に追加する
組み込みのHTTP + Swagger コネクタを使用し、ウィザードを使用してSpark プロセスフローを設計できます。
- [Power Automate]で、[My Flows]->[Create from Blank]をクリックします。
- [Recurrence]アクションを選択し、電子メールを送信する時間間隔を選択します。この記事では、[1日]にします。
- Swagger を検索してHTTP + Swagger アクションを追加します。
- Swagger メタデータドキュメントのURL を入力します。
https://MySite:MyPort/api.rsc/@MyAuthtoken/$oas
- [Return Customers]操作を選択します。
Spark を取得するためのOData クエリを作成します。この記事では、$filter ボックスで次のOData フィルタ形式を定義します。
Country eq 'US'
サポートされているOData のフィルタリングと例の詳細については、API Server のヘルプドキュメントを参照してください。

アクションをトリガー
これで、プロセスフローでCustomers エンティティを操作できます。以下のステップに従って、自動メールを送信します。
- メール送信アクションであるSMTP を追加します。
- SMTP サーバーのアドレスと資格情報を入力し、接続に名前を付けます。サーバーでサポートされている場合には、必ず暗号化を有効にしてください。
- メッセージのヘッダーと本文を入力します。これらのボックスにSpark カラムを追加できます。

おわりに
この記事では、CData API Server を使用して、Power Automate からSpark データにアクセスする方法を説明しました。これにより、ビジネスプロセスを自動化し、効率を向上させることができます。API Server の設定やユーザー管理、OpenAPI エンドポイントの作成など、さまざまなステップを経て、最終的にPower Automate でのデータ操作が可能になります。