





コラボフローのクラウド申請フォームでSpark のデータをLookup 参照する

コラボフロー(www.collabo-style.co.jp/ )は誰でも簡単に作れるクラウドベースのワークフローサービスです。コラボフローでは、申請フォームにJavaScriptを組み込むことで、外部のREST APIをコールして入力補完や連携を行うことができる機能を提供しています。この記事では、Spark のデータをCData API Server 経由でコラボフローの申請書入力画面から参照できるようにします。このLookup 参照により、申請フォームの入力を便利にすることができます。
API Server の設定
以下のリンクからAPI Server の無償トライアルをスタートしたら、セキュアなSpark OData サービスを作成していきましょう。
Spark への接続
コラボフロー からSpark のデータを操作するには、まずSpark への接続を作成・設定します。
- API Server にログインして、「Connections」をクリック、さらに「接続を追加」をクリックします。
- 「接続を追加」をクリックして、データソースがAPI Server に事前にインストールされている場合は、一覧から「Spark」を選択します。
- 事前にインストールされていない場合は、コネクタを追加していきます。コネクタ追加の手順は以下の記事にまとめてありますので、ご確認ください。
CData コネクタの追加方法はこちら >> - それでは、Spark への接続設定を行っていきましょう!
-
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
- 接続情報の入力が完了したら、「保存およびテスト」をクリックします。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
API Server のユーザー設定
次に、API Server 経由でSpark にアクセスするユーザーを作成します。「Users」ページでユーザーを追加・設定できます。やってみましょう。
- 「Users」ページで ユーザーを追加をクリックすると、「ユーザーを追加」ポップアップが開きます。
-
次に、「ロール」、「ユーザー名」、「権限」プロパティを設定し、「ユーザーを追加」をクリックします。

-
その後、ユーザーの認証トークンが生成されます。各ユーザーの認証トークンとその他の情報は「Users」ページで確認できます。

Spark 用のAPI エンドポイントの作成
ユーザーを作成したら、Spark のデータ用のAPI エンドポイントを作成していきます。
-
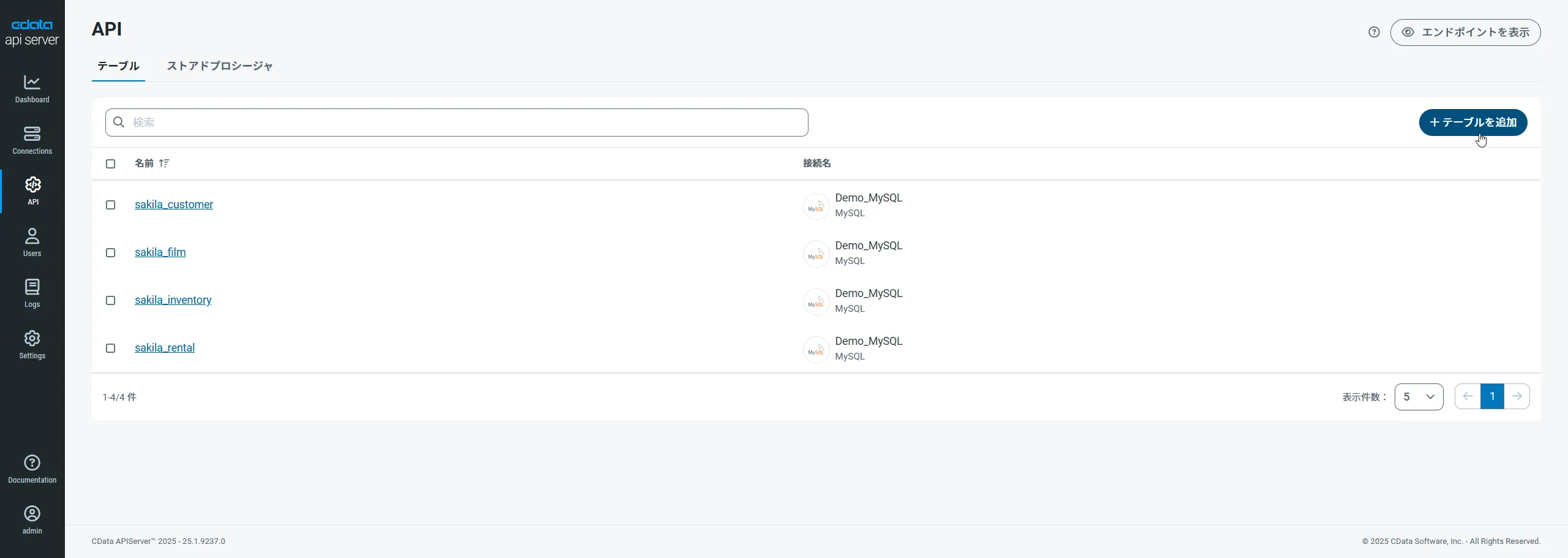
まず、「API」ページに移動し、
「 テーブルを追加」をクリックします。
-
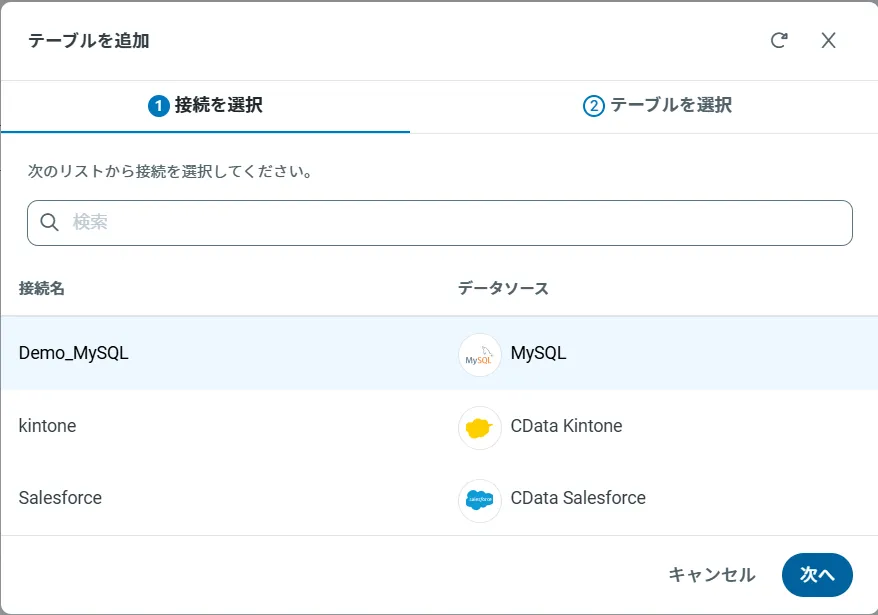
アクセスしたい接続を選択し、次へをクリックします。
-
接続を選択した状態で、各テーブルを選択して確認をクリックすることでエンドポイントを作成します。

OData のエンドポイントを取得
以上でSpark への接続を設定してユーザーを作成し、API Server でSpark データのAPI を追加しました。これで、OData 形式のSpark データをREST API で利用できます。API Server の「API」ページから、API のエンドポイントを表示およびコピーできます。

コラボフローで、Spark のデータに連携する
コラボフローからAPI Server に連携するためのJavaScript の準備
コラボフロー上で使用するAPI Server との接続用JavaScriptを準備します。
(function () {
'use strict';
// Setting Propeties
const AutocompleteSetting =
{
// Autocomplete target field for Collaboflow
InputName: 'fid0',
// Collaboflow item detils line number
ListRowNumber : 15,
// Autocomplete tartget field for API Server
ApiListupFiledColumn : 'sparksql_column',
// Key Column Name for API Server resource
ApiListupKeyColumn : 'sparksql_keycolumn',
// Mapping between Collaboflow field and API Server column
Mappings: [
{
PartsName: 'fid1', // Collabo flow field name
APIName: 'sparksql_column1' // API Server column name
},
{
PartsName: 'fid2',
APIName: 'sparksql_column2'
},
{
PartsName: 'fid3',
APIName: 'sparksql_column3'
},
{
PartsName: 'fid4',
APIName: 'sparksql_column4'
}
]
};
const CDataAPIServerSetting = {
// API Server URL
ApiServerUrl : 'http://XXXXXX',
// API Server Resource Name
ApiServerResourceName : 'sparksql_table',
// API Server Key
Headers : { Authorization: 'Basic YOUR_BASIC_AUTHENTICATION' },
// General Properties
ParseType : 'json',
get BaseUrl() {
return CDataAPIServerSetting.ApiServerUrl + '/api.rsc/' + CDataAPIServerSetting.ApiServerResourceName
}
}
let results = [];
let records = [];
// Set autocomplete processing for target input field
collaboflow.events.on('request.input.show', function (data) {
for (let index = 1; index < AutocompleteSetting.ListRowNumber; index++) {
$('#' + AutocompleteSetting.InputName + '_' + index).autocomplete({
source: AutocompleteDelegete,
autoFocus: true,
delay: 500,
minLength: 2
});
}
});
// This function get details from API Server, Then set values at each input fields based on mappings object.
collaboflow.events.on('request.input.' + AutocompleteSetting.InputName + '.change', function (eventData) {
debugger;
let tartgetParts = eventData.parts.tbl_1.value[eventData.row_index - 1];
let keyId = tartgetParts[AutocompleteSetting.InputName].value.split(':')[1\;
let record = records.find(x => x[AutocompleteSetting.ApiListupKeyColumn] == keyId);
if (!record)
return;
AutocompleteSetting.Mappings.forEach(x => tartgetParts[x.PartsName].value = '');
AutocompleteSetting.Mappings.forEach(x => tartgetParts[x.PartsName].value = record[x.APIName]);
});
function AutocompleteDelegete(req, res) {
let topParam = '&$top=10'
let queryParam = '$filter=contains(' + AutocompleteSetting.ApiListupFiledColumn + ',\'' + encodeURIComponent(req.term) + '\')';
collaboflow.proxy.get(
CDataAPIServerSetting.BaseUrl + '?' +
queryParam +
topParam,
CDataAPIServerSetting.Headers,
CDataAPIServerSetting.ParseType).then(function (response) {
results = [];
records = [];
if (response.body.value.length == 0) {
results.push('No Results')
res(results);
return;
}
records = response.body.value;
records.forEach(x => results.push(x[AutocompleteSetting.ApiListupFiledColumn] + ':' + x[AutocompleteSetting.ApiListupKeyColumn]));
res(results);
}).catch(function (error) {
alert(error);
});
}
})();
- 「CDataAPIServerSetting」のそれぞれのプロパティには構成したSSH ServerのURLとAPI Serverの認証情報をそれぞれ設定してください。
- 「AutocompleteSetting」はどのフィールドでオートコンプリートを動作させるか? といった設定と、APIのプロパティとのマッピングを行います。
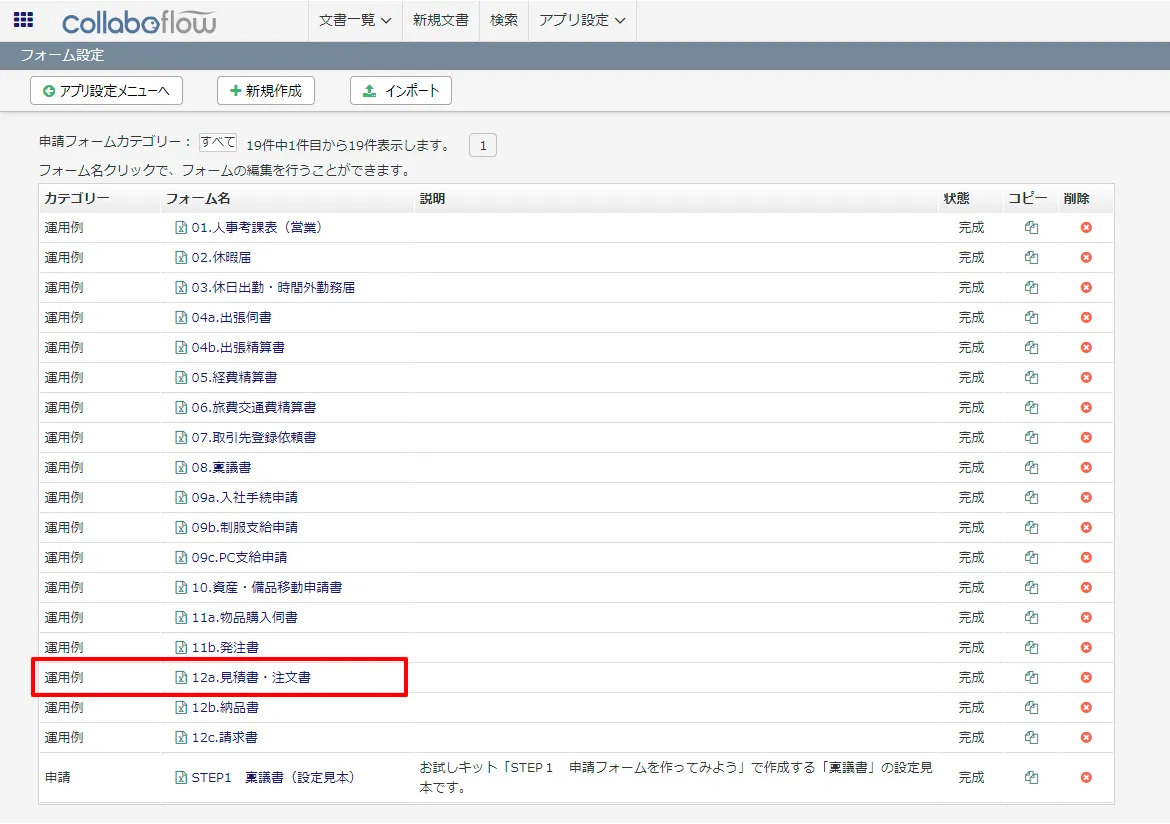
- 今回はCollaboflowのデフォルトテンプレートで提供されている「12a.見積書・注文書」で利用しますので、デフォルトでは商品名のフィールドを、ProductテーブルのNameと紐付けて、Autocompleteを行うように構成しています。値が決定されたら、KeyとなるProductIDを元に「型番、標準単価、仕入単価、御提供単価」をそれぞれAPIから取得した値で自動補完するようになっています。
コラボフロー側でJavaScriptを登録
JavaScriptを作成したら、後はコラボフローにアップするだけです。
- コラボフローにログインし「アプリ設定」→「フォーム設定」に移動します。
- フォーム一覧から使用するフォームを選択します。
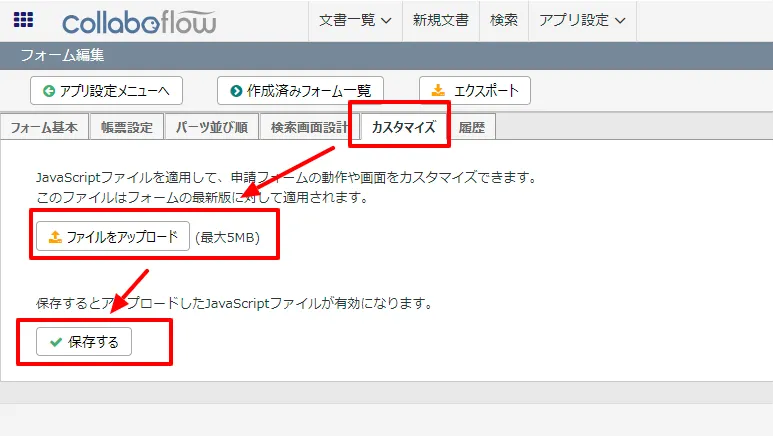
- フォーム編集画面に移動後、「カスタマイズ」タブをクリックし、ファイルをアップロードから作成したJSファイルをアップロードし、保存します。
- これでAPI Server 経由でSpark のデータを取得し、自動入力補完する機能がコラボフローの申請フォームに追加できました。
まとめと30日の無償評価版のご案内
このように Spark 内のデータをコラボフローで利用することができるようになります。CData API Server は、30日の無償評価版があります。是非、お試しいただき、コラボフローからのデータ参照を体感ください。