





クラウドRPA BizteX Connect で使えるSpark のデータ連携用のバックエンドAPI をノーコードで開発

CData API Server を使って、BizteX Connect から Spark に接続してデータを取得する方法を説明します。
API Server の設定
以下のリンクからAPI Server の無償トライアルをスタートしたら、セキュアなSpark OData サービスを作成していきましょう。
Spark への接続
BizteX Connect からSpark のデータを操作するには、まずSpark への接続を作成・設定します。
- API Server にログインして、「Connections」をクリック、さらに「接続を追加」をクリックします。
- 「接続を追加」をクリックして、データソースがAPI Server に事前にインストールされている場合は、一覧から「Spark」を選択します。
- 事前にインストールされていない場合は、コネクタを追加していきます。コネクタ追加の手順は以下の記事にまとめてありますので、ご確認ください。
CData コネクタの追加方法はこちら >> - それでは、Spark への接続設定を行っていきましょう!
-
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
- 接続情報の入力が完了したら、「保存およびテスト」をクリックします。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
API Server のユーザー設定
次に、API Server 経由でSpark にアクセスするユーザーを作成します。「Users」ページでユーザーを追加・設定できます。やってみましょう。
- 「Users」ページで ユーザーを追加をクリックすると、「ユーザーを追加」ポップアップが開きます。
-
次に、「ロール」、「ユーザー名」、「権限」プロパティを設定し、「ユーザーを追加」をクリックします。

-
その後、ユーザーの認証トークンが生成されます。各ユーザーの認証トークンとその他の情報は「Users」ページで確認できます。

Spark 用のAPI エンドポイントの作成
ユーザーを作成したら、Spark のデータ用のAPI エンドポイントを作成していきます。
-
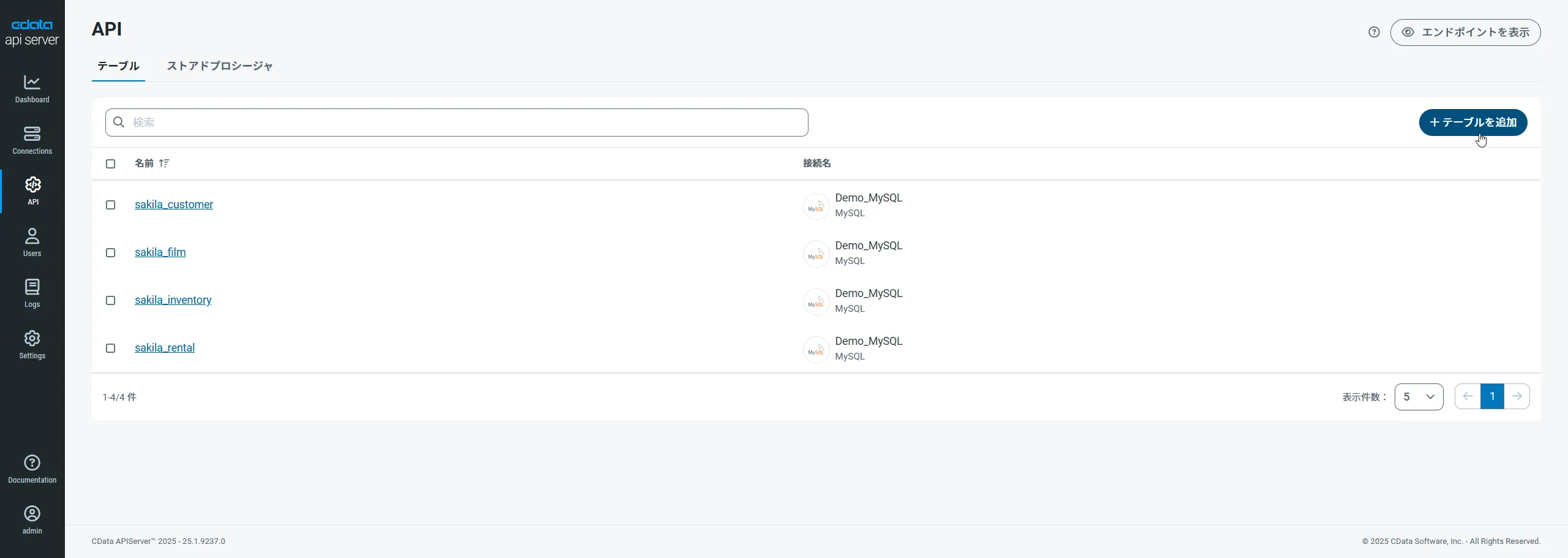
まず、「API」ページに移動し、
「 テーブルを追加」をクリックします。
-
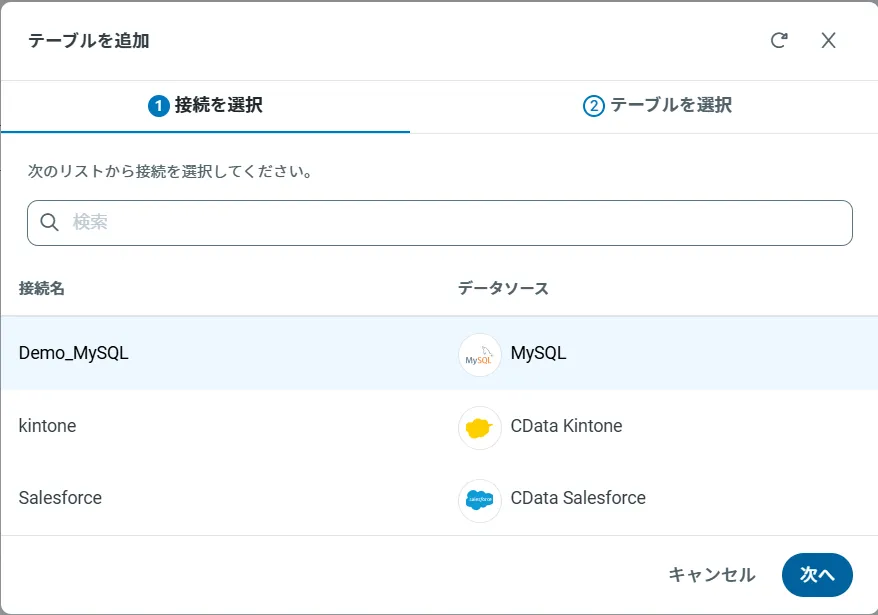
アクセスしたい接続を選択し、次へをクリックします。
-
接続を選択した状態で、各テーブルを選択して確認をクリックすることでエンドポイントを作成します。

OData のエンドポイントを取得
以上でSpark への接続を設定してユーザーを作成し、API Server でSpark データのAPI を追加しました。これで、OData 形式のSpark データをREST API で利用できます。API Server の「API」ページから、API のエンドポイントを表示およびコピーできます。

オンプレミスDB やファイルからのAPI Server 使用(オプション)
オンプレミスRDB やExcel/CSV などのファイルのデータを使用する場合には、API Server のCloug Gateway / SSH ポートフォワーディングが便利です。Cloud Gatway の設定方法 記事を参考にしてください。
プロジェクト・シナリオの作成
API Server 側の準備が完了したら、早速BizteX Connect 側でプロジェクト・シナリオの作成を開始します。
- まずはプロジェクトとシナリオ(フロー)を作成します。シナリオ(フロー)はプロジェクト単位でまとめて管理できるようです。
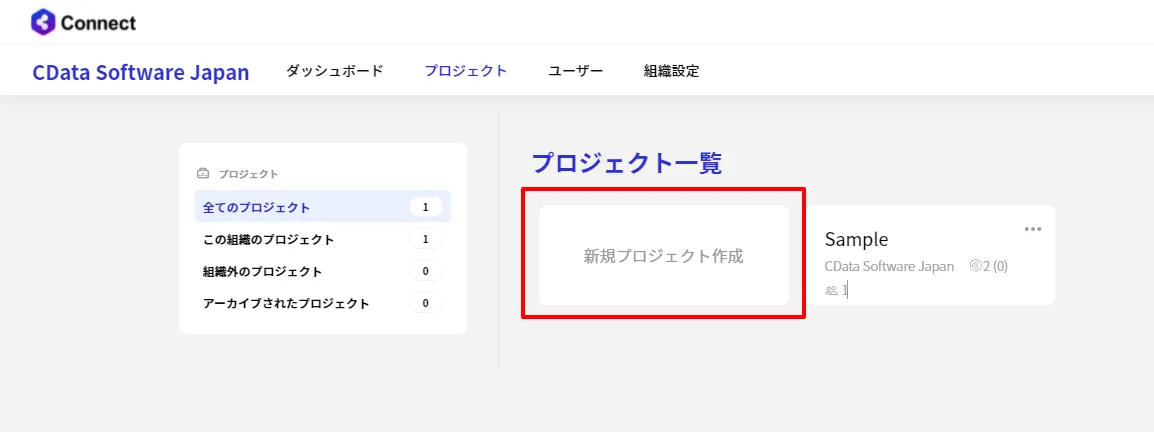
- 「新規プロジェクト作成」をクリック
- 任意の名称でプロジェクトを作成します。
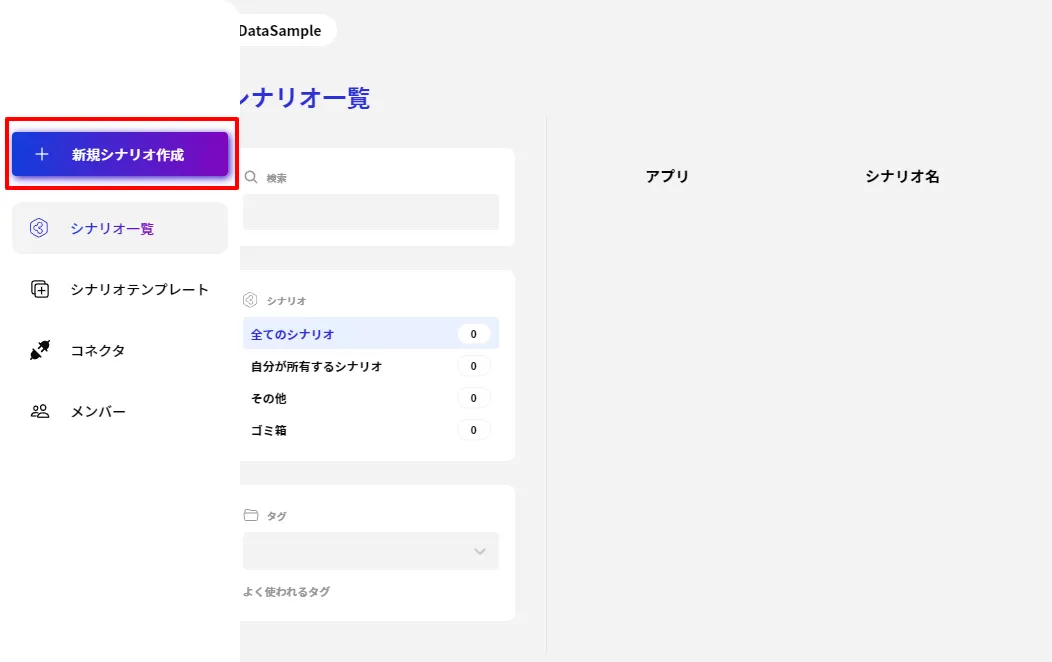
- その後「+新規シナリオ作成」をクリックして、kintone データ連携シナリオの作成を進めていきます。
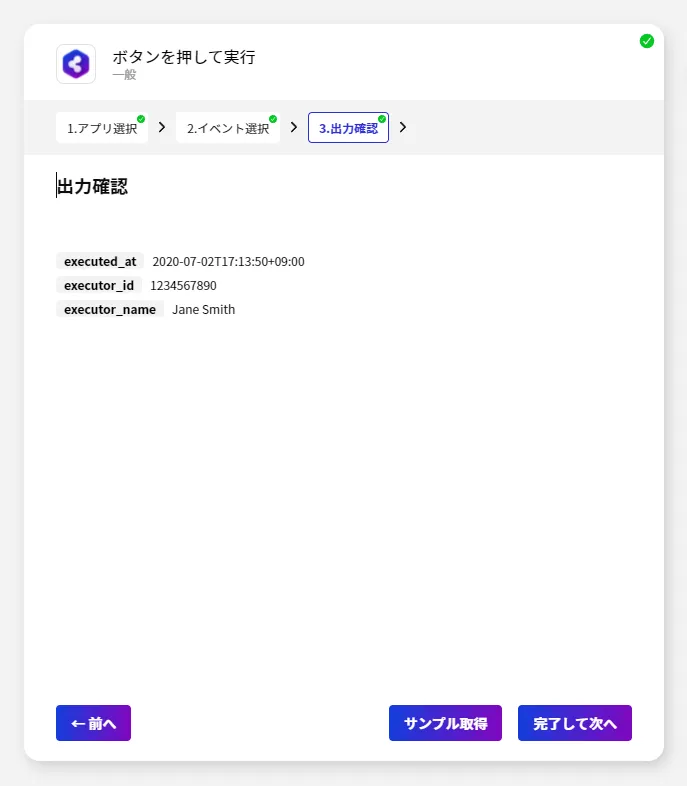
起動イベントの設定
シナリオの作成で一番最初に設定することが、起動イベントの構成です。BizteX Connect ではさまざまな起動イベントが存在しますが、今回は検証用途として「手動」実行にしてみました。
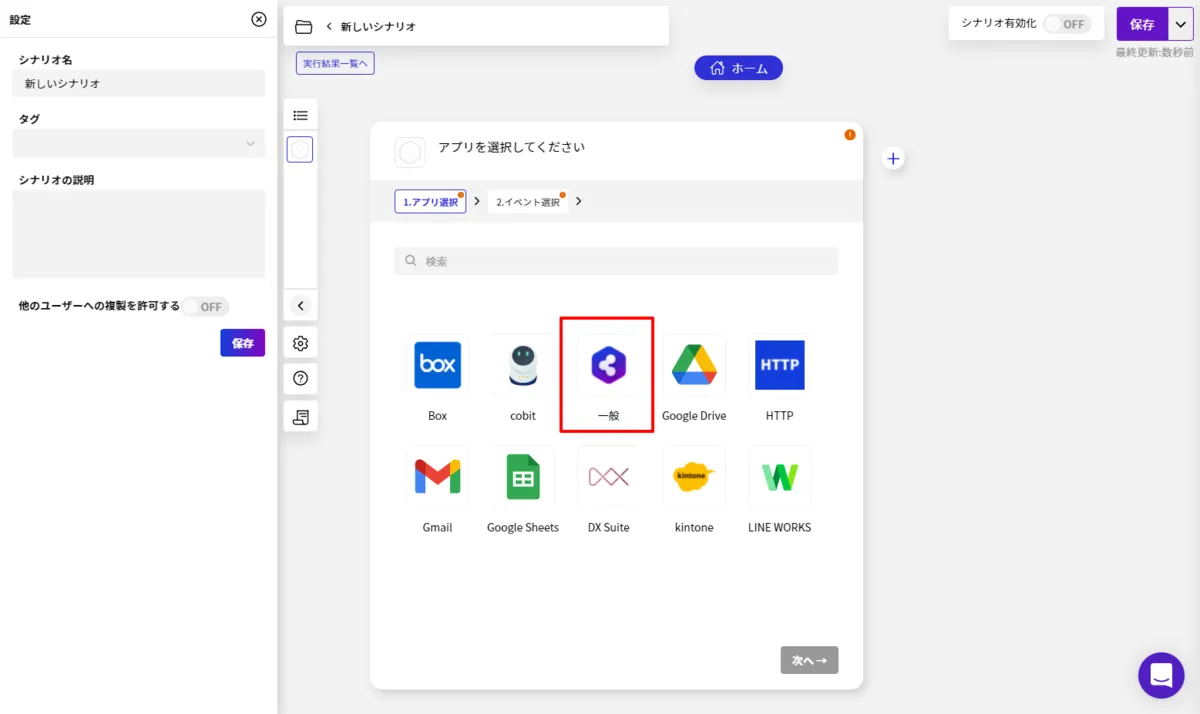
- 「アプリ選択」の一覧から「一般」を選択し
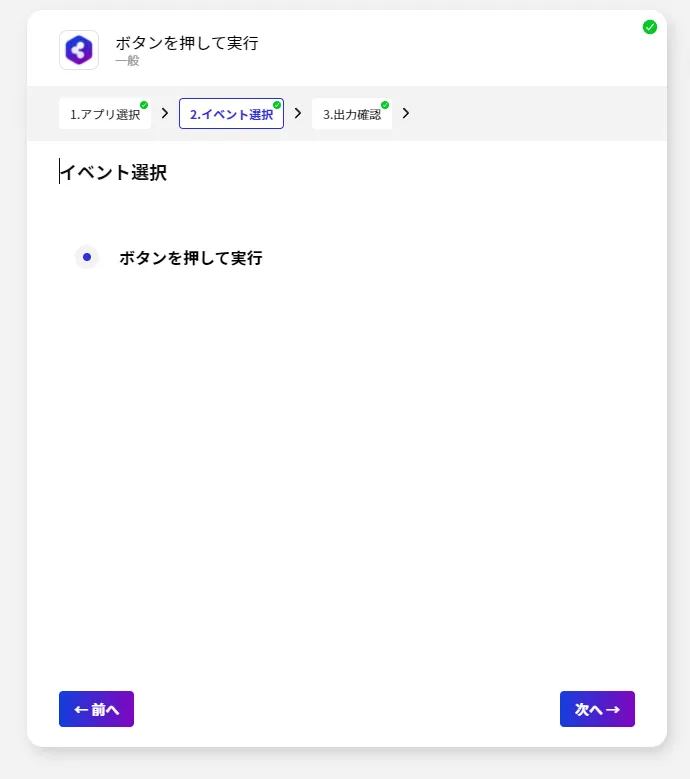
- 「ボタンを押して実行」を選択します。
- それぞれのイベントでは出力データが変数として格納されます。内容を確認して「完了して次へ」をクリックしましょう。
HTTP コネクタの構成
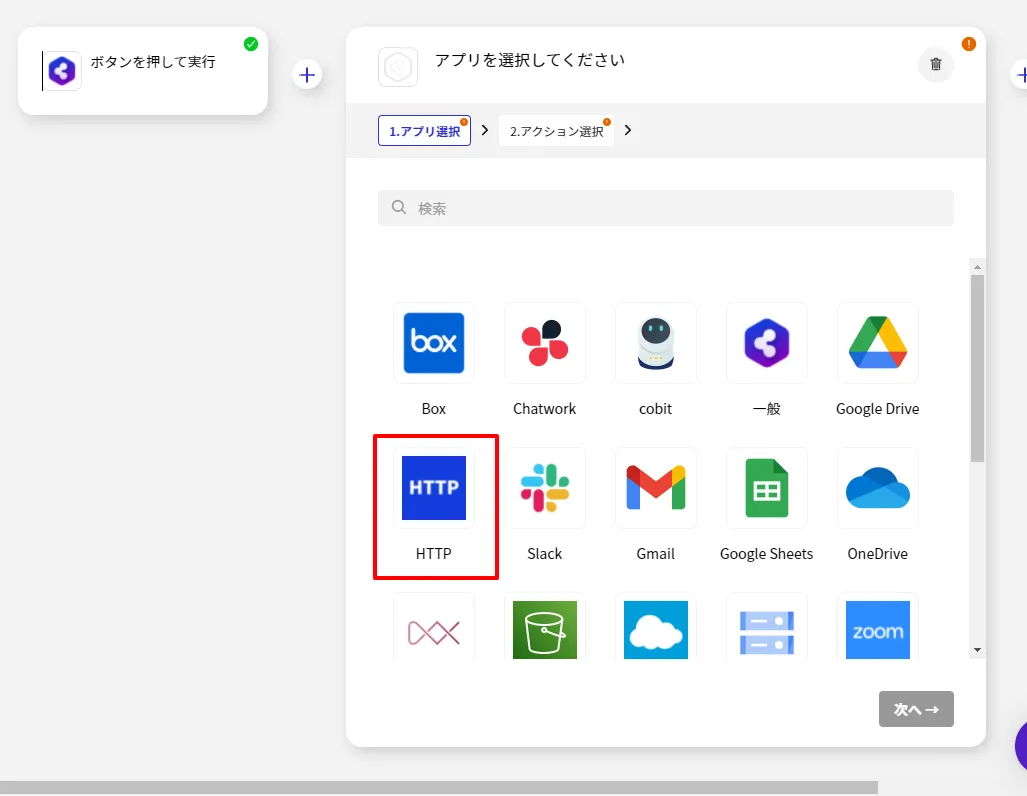
今回のシナリオでは、Spark のデータを取得して BizteX Connect で扱えるようにします。
- API Server へのアクセスには「HTTP コネクタ」が利用できるので、アプリの一覧から選択します。
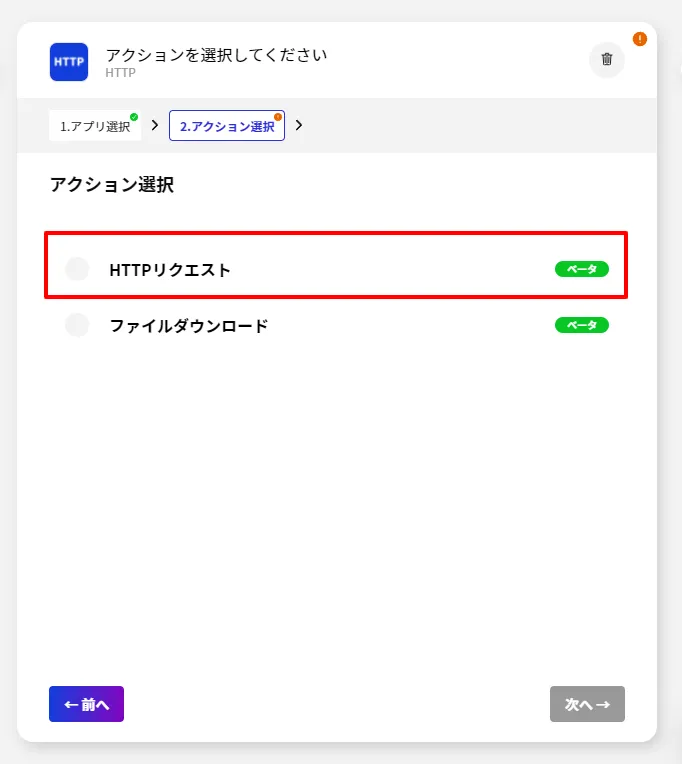
- アクションは「HTTP リクエスト」を指定します。
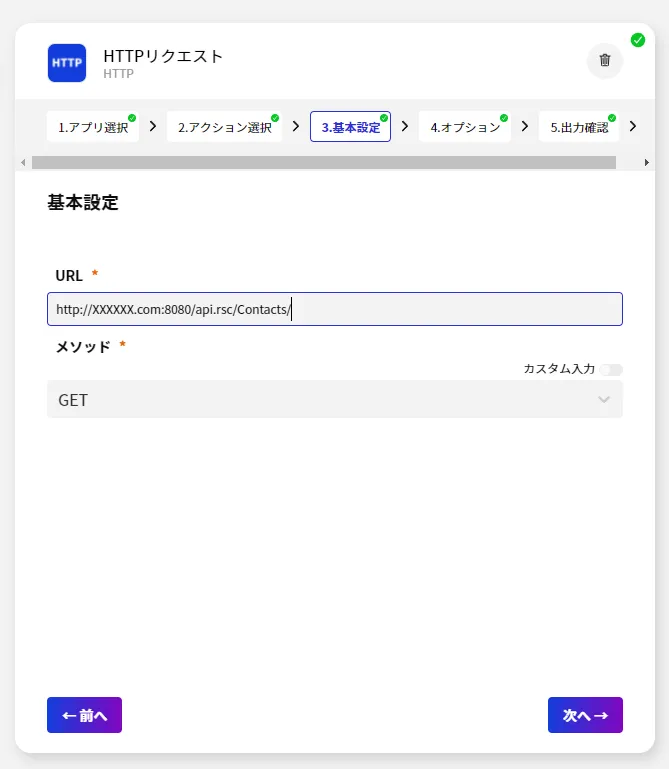
- 続いて、データを取得するためのAPI リクエストを指定します。今回はデータを取得するのでGET リクエストです。対象のURL はAPI Server のAPI ドキュメントから取得してきて指定しましょう。
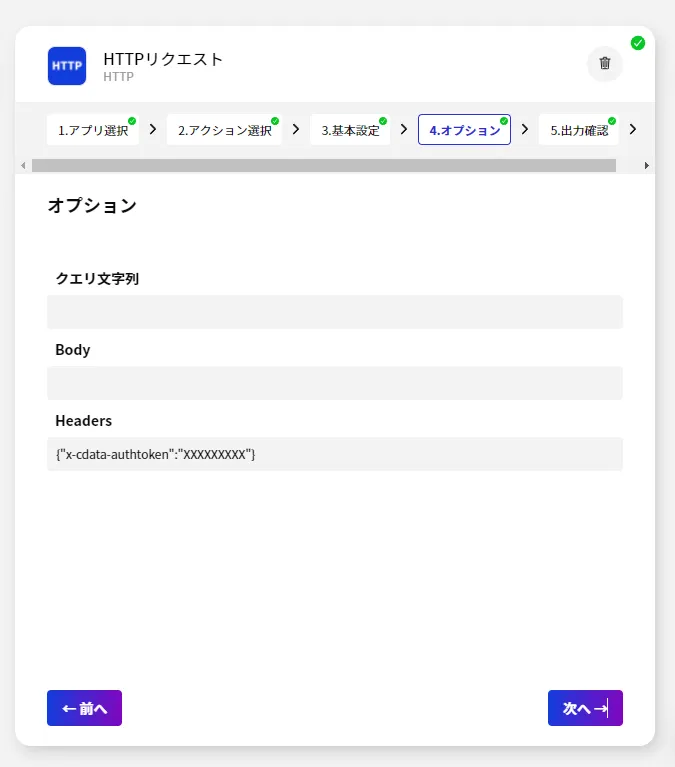
- 基本設定が完了したら、オプションを指定します。ここで最低限必要になるオプションはAPI Server への認証情報の指定です。以下のようなJSON 形式でx-cdata-authtoken のプロパティにAPI Server で構成したユーザーのトークンを指定すれば接続が行えます。
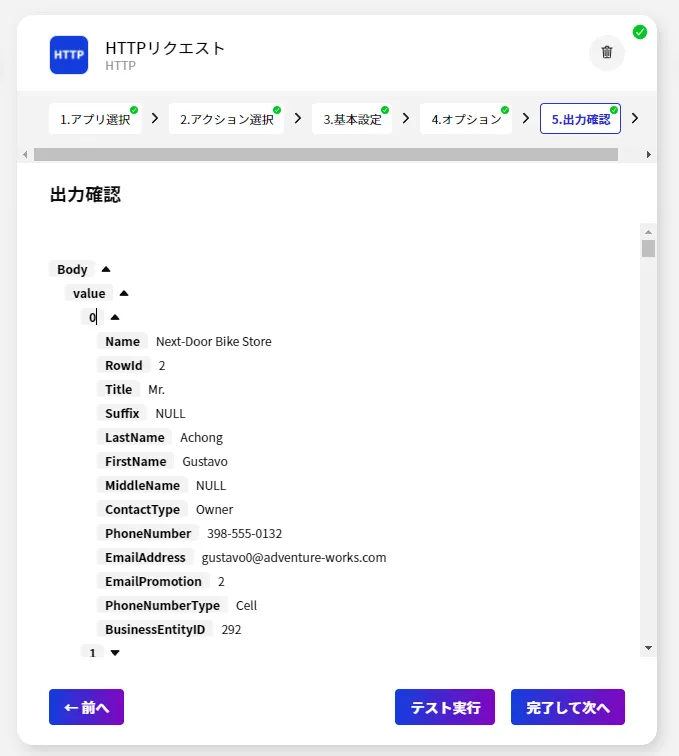
- すべての設定が完了したら出力結果を確認してみましょう。以下のようにBody の中の「value」オブジェクトの中に配列形式でデータが格納されていることが確認できます。正常にBizteX Connect からSpark のデータが取得できていますね。
- あとはBizteX Connect の各種機能を活用して、さまざまなサービスとの連携を実現できます。
このように、CData API Server を経由することで、API 側の複雑な仕様を意識せずにAPI 連携をしたプロジェクトをBizteX Connect で開発できます。他にも多くのデータソースに対応するCData API Server の詳細をこちらからご覧ください。