





Looker Studio でSpark のデータと連携した可視化を作成する方法

Looker Studio(旧Google データポータル)を使えば、リッチな可視化を追加したダッシュボードやレポートを簡単に作成できます。CData Connect AI と組み合わせることで、Spark のデータに簡単に接続してLooker Studio からデータを連携利用できます。この記事では、Looker Studio からCData Connect AI を通してSpark に連携し、Spark のデータを使用した可視化を作成する方法を説明します。
CData Connect AI offers a seamless cloud-to-cloud interface tailored for Spark, making it straightforward to construct reports directly from liveSpark のデータwithin Looker Studio without the need for data replication. As you create visualizations, Looker Studio generates queries to retrieve data. With its inherent optimized data processing capabilities, CData Connect AI efficiently channels all supported query operations, including filters, JOINs, and more, directly to Spark. This leverages server-side processing to swiftly provide the requested Spark のデータ.
Connect AI からSpark への接続
CData Connect AI では、直感的なクリック操作ベースのインターフェースを使ってデータソースに接続できます。
- Connect AI にログインし、 Add Connection をクリックします。
- 「Add Connection」パネルから「Spark」を選択します。

-
必要な認証プロパティを入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
- Create & Tast をクリックします。
- 「Add Spark Connection」ページの「Permissions」タブに移動し、ユーザーベースのアクセス許可を更新します。
コネクションの設定が完了したら、Looker Studio からSpark のデータへの接続準備ができました。
Spark のリアルタイムデータにLooker Studio からアクセス
それでは、Looker Studio からCData Connect AI に接続して新しいSpark のデータソースを作成し、データを使った可視化を作成していきましょう。
- Looker Studio にログインして、「作成」ボタンから新しいデータソースを作成し、CData Connect AI Connector を選択します。
- 「Authorize」をクリックしてGoogle アカウントへのアクセスを許可します。
- 「Authorize」をクリックしてご利用のCData Connect AI インスタンスを認証します。

- Looker Studio のCData Connect AI Connector でコネクション(例:SparkSQL1)を選択し、「Next」をクリックします。
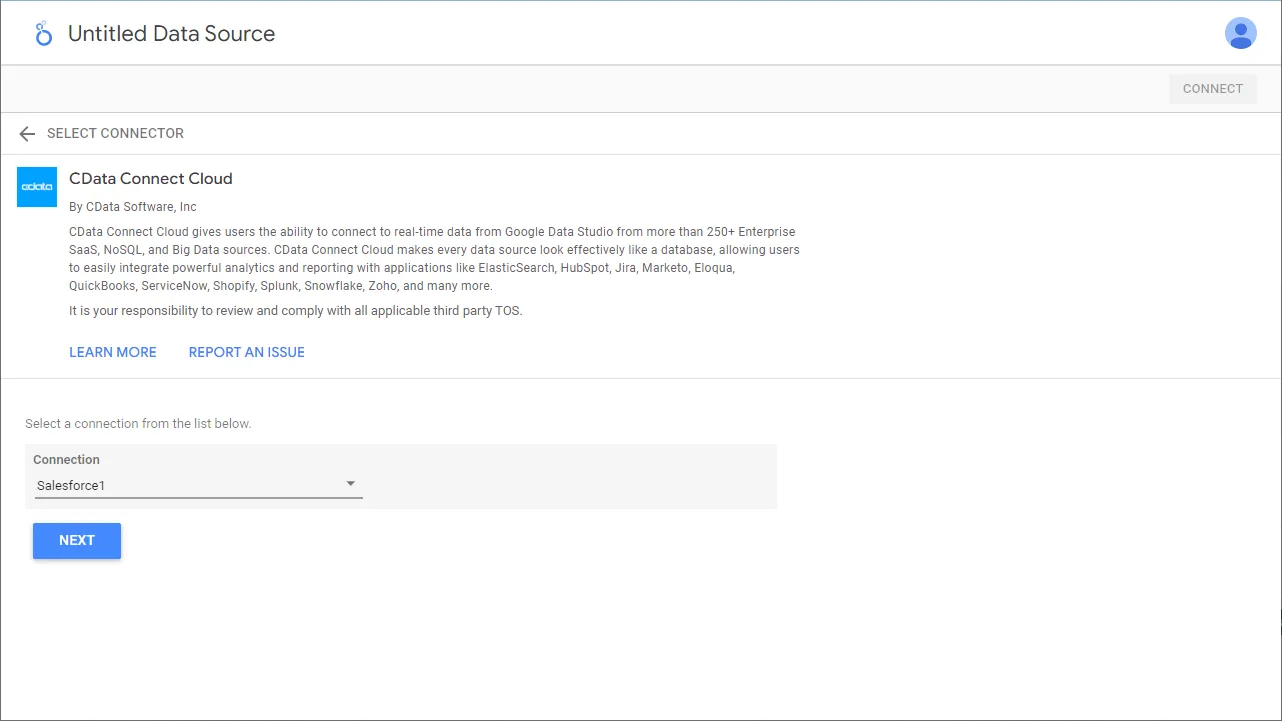
- テーブル(例:Customers)を選択するかCustom Query を使用して、「CONNECT」をクリックして次に進みます。
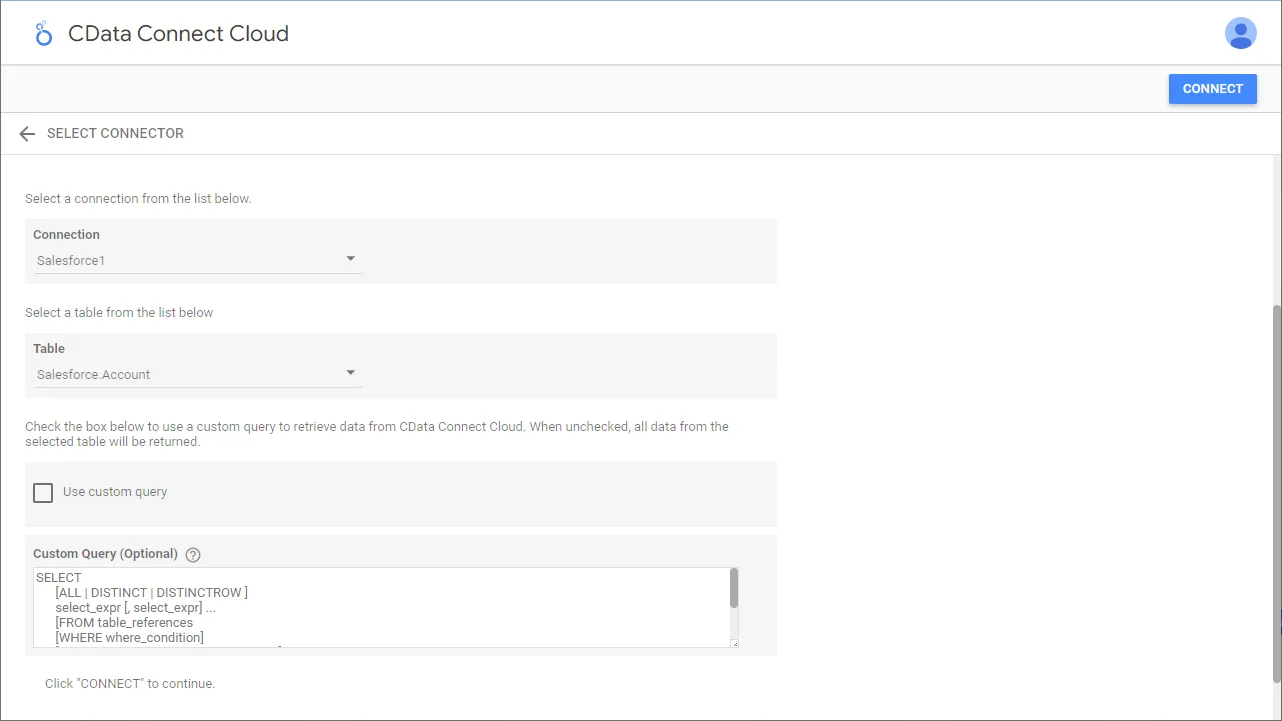
- 必要な場合にはカラムを変更して、「レポートを作成」をクリックしてデータソースをレポートに追加します。
- 可視化のスタイルを選択してレポートに追加します。
- ディメンションと指標を選択して可視化を作成します。これで、Spark のデータの可視化が作成できました。
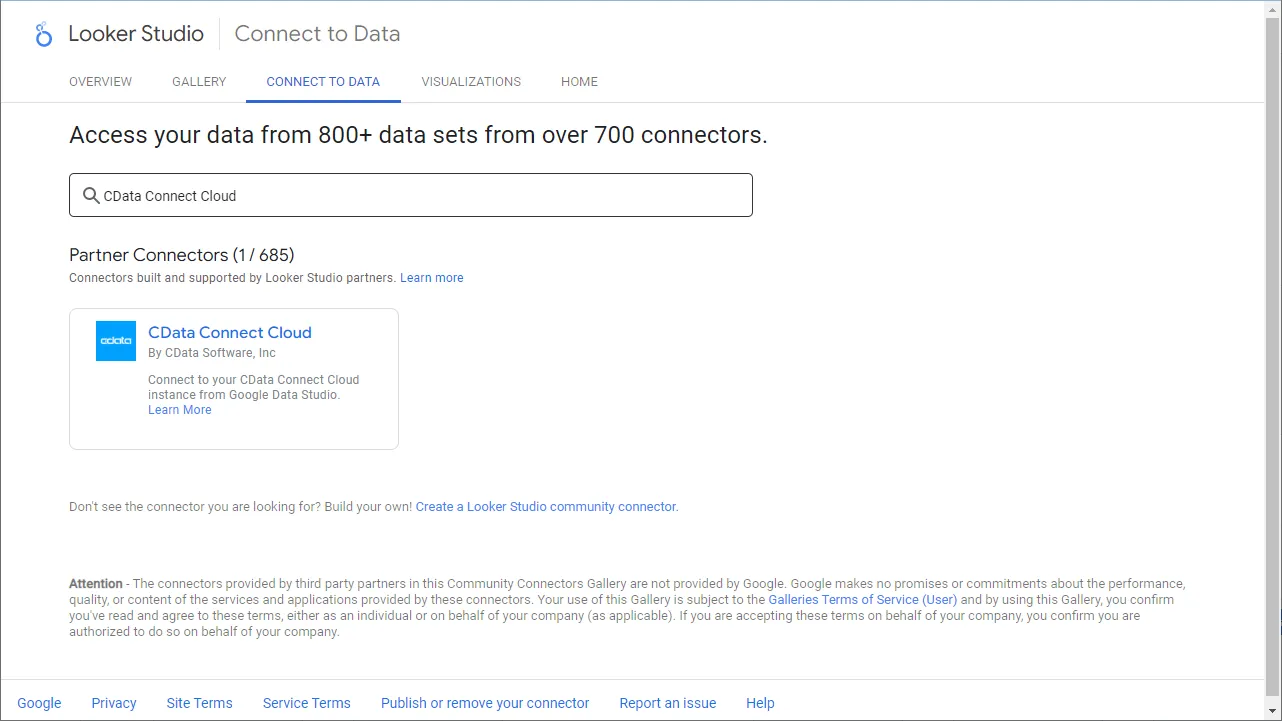
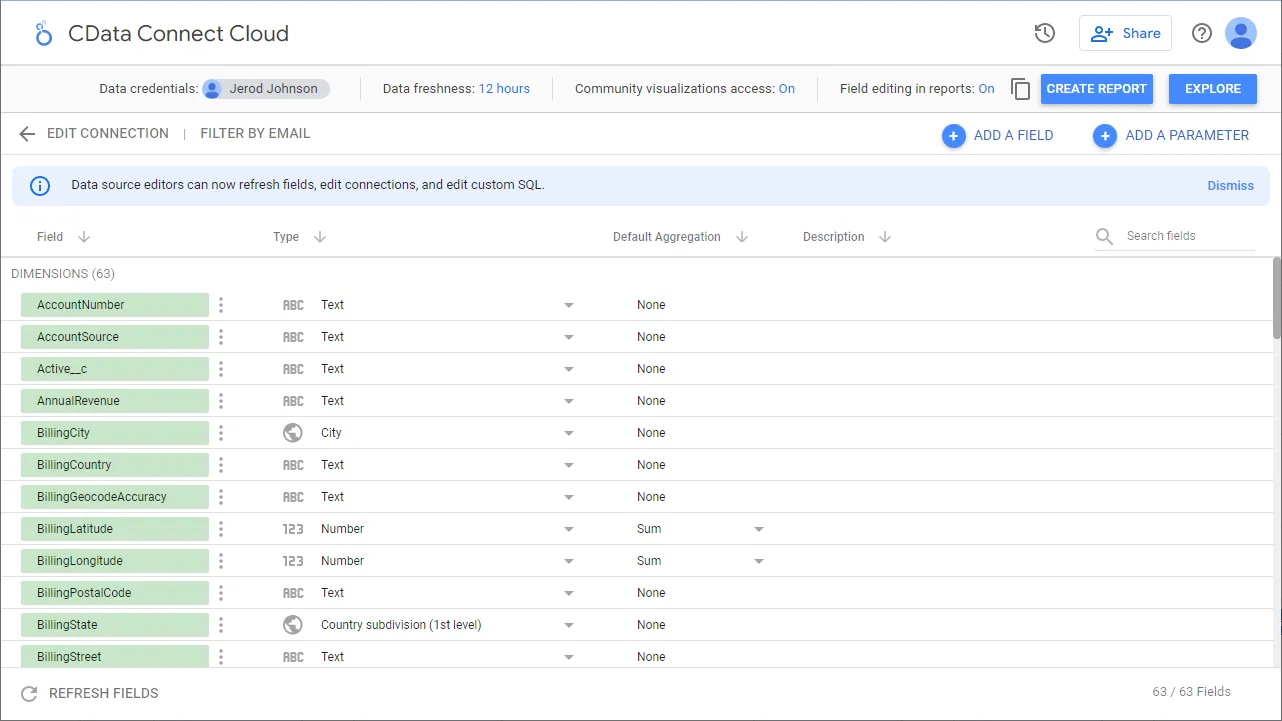
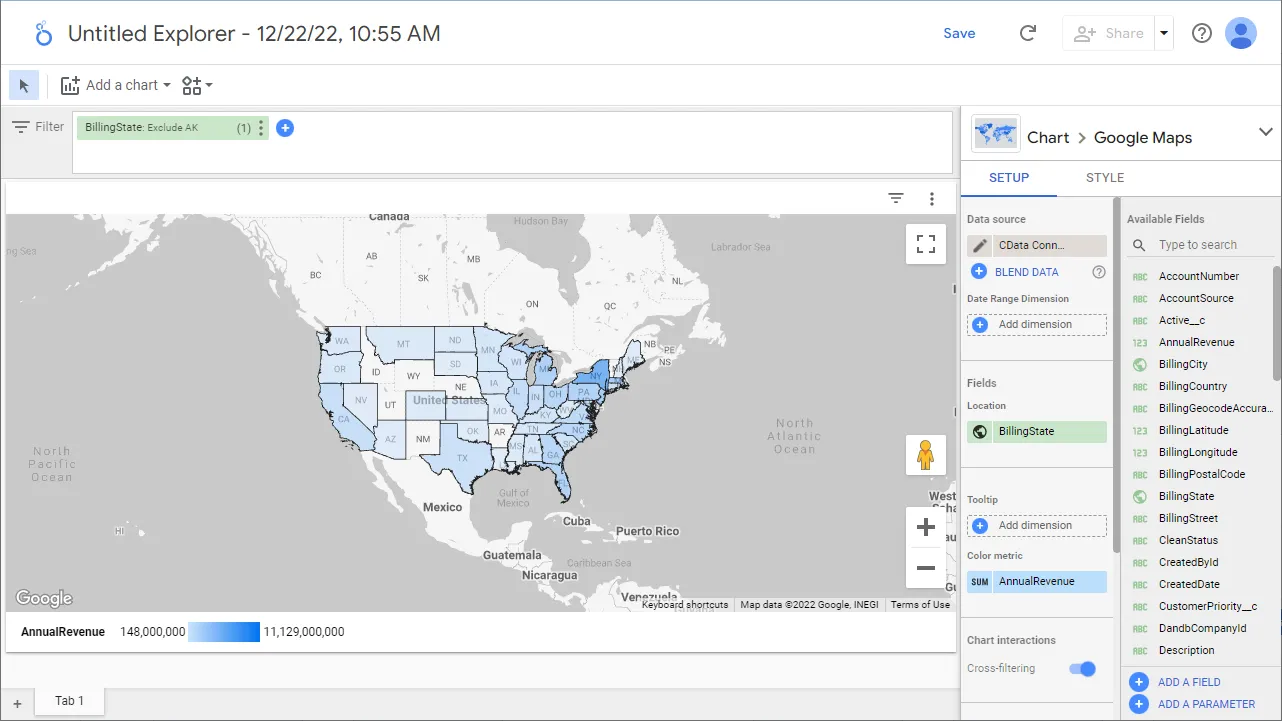
クラウドアプリケーションからSpark のデータへのリアルタイム連携
これで、可視化の作成は完了です。あとは、Spark から自在にデータを取得して、ダッシュボード構築やレポーティングに活用できます。
クラウドアプリケーションから150を超えるSaaS、ビッグデータ、NoSQL データソースへのリアルタイムデータ連携の実現には、CData Connect AI の14日間無償トライアルをぜひお試しください。