





コラボフローでSpark のデータと連携したワークフローを作成

コラボフロー(www.collabo-style.co.jp/ )は誰でも簡単に作れるクラウドベースのワークフローサービスです。さらにCData Connect AI と連携することで、Spark のデータへのクラウドベースのアクセスをノーコードで追加できます。本記事では、CData Connect AI 経由でコラボフローからSpark 連携を実現する方法を紹介します。
CData Connect AI はSpark のデータへのクラウドベースのOData インターフェースを提供し、コラボフローからSpark のデータへのリアルタイム連携を実現します。
Connect AI を構成
コラボフローでSpark のデータを操作するには、Connect AI からSpark に接続し、コネクションにユーザーアクセスを提供してSpark のデータのOData エンドポイントを作成する必要があります。
Spark に接続したら、目的のテーブルのOData エンドポイントを作成します。
(オプション)新しいConnect AI ユーザーの追加
必要であれば、Connect AI 経由でSpark に接続するユーザーを作成します。
- 「Users」ページに移動し、 Invite Users をクリックします。
- 新しいユーザーのE メールアドレスを入力して、 Send をクリックしてユーザーを招待します。
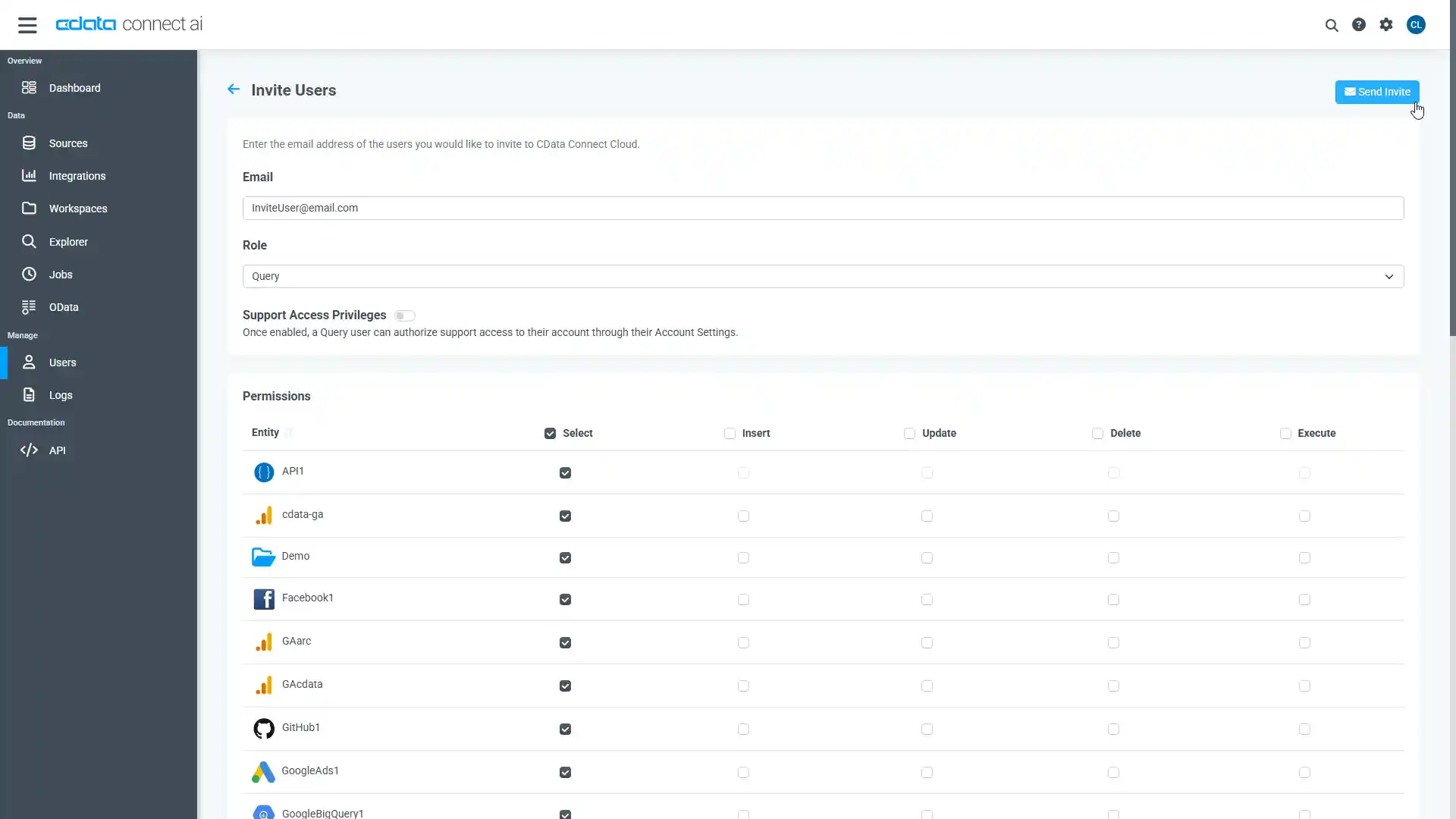
- 「Users」ページからユーザーを確認および編集できます。
パーソナルアクセストークン(PAT)の追加
OAuth 認証をサポートしていないサービス、アプリケーション、プラットフォーム、またはフレームワークから接続する場合は、認証に使用するパーソナルアクセストークン(PAT)を作成できます。きめ細かなアクセス管理を行うために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
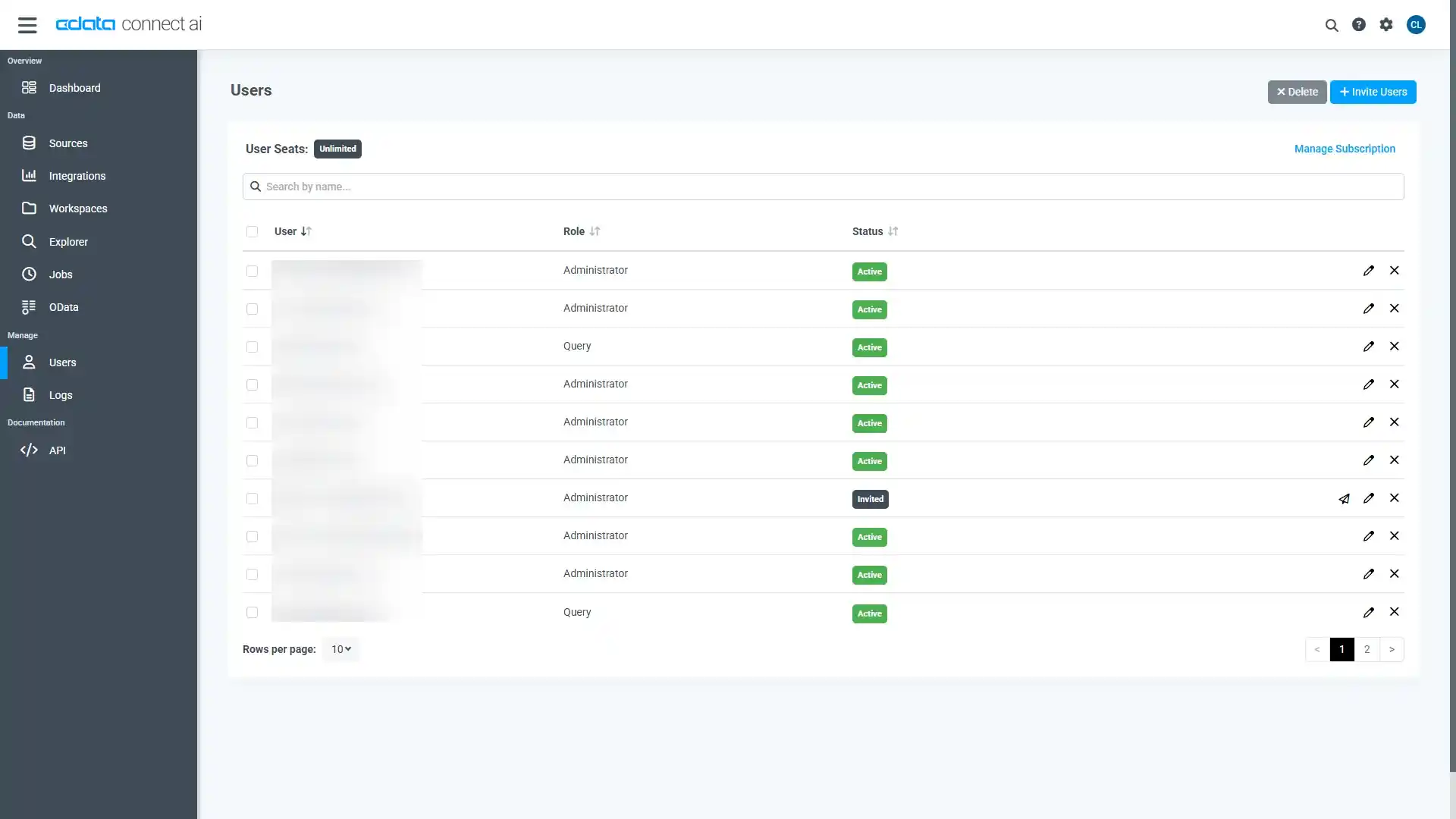
- Connect AI アプリの右上にあるユーザー名をクリックし、「User Profile」をクリックします。
- 「User Profile」ページで「Access Token」セクションにスクロールし、 Create PAT をクリックします。
- PAT の名前を入力して Create をクリックします。
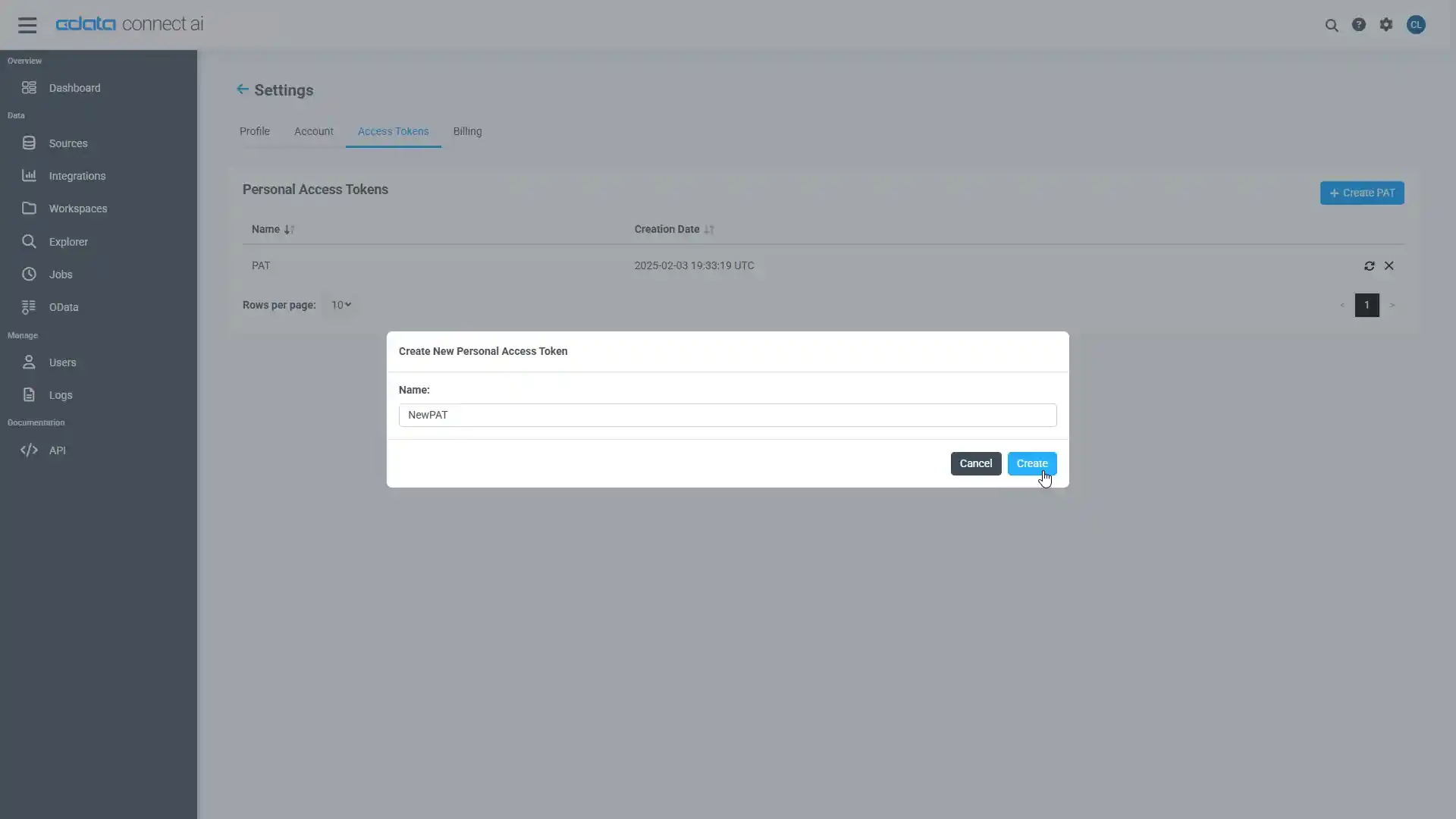
- パーソナルアクセストークン(PAT)は作成時にしか表示されないため、必ずコピーして安全に保存してください。
Connect AI からSpark に接続
CData Connect AI では、簡単なクリック操作ベースのインターフェースでデータソースに接続できます。
- Connect AI にログインし、 Add Connection をクリックします。
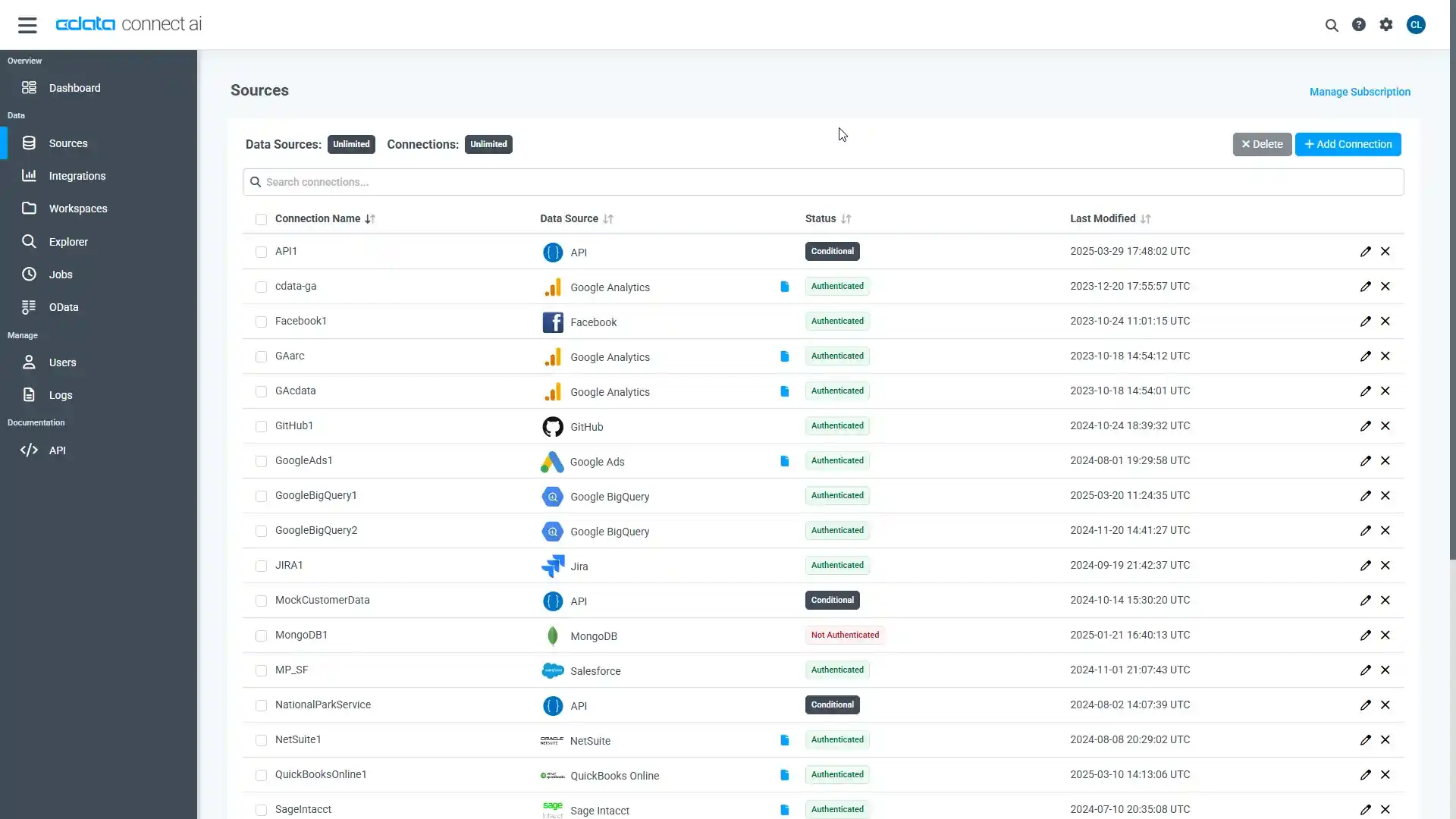
- 「Add Connection」パネルから「Spark」を選択します。

-
必要な認証プロパティを入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
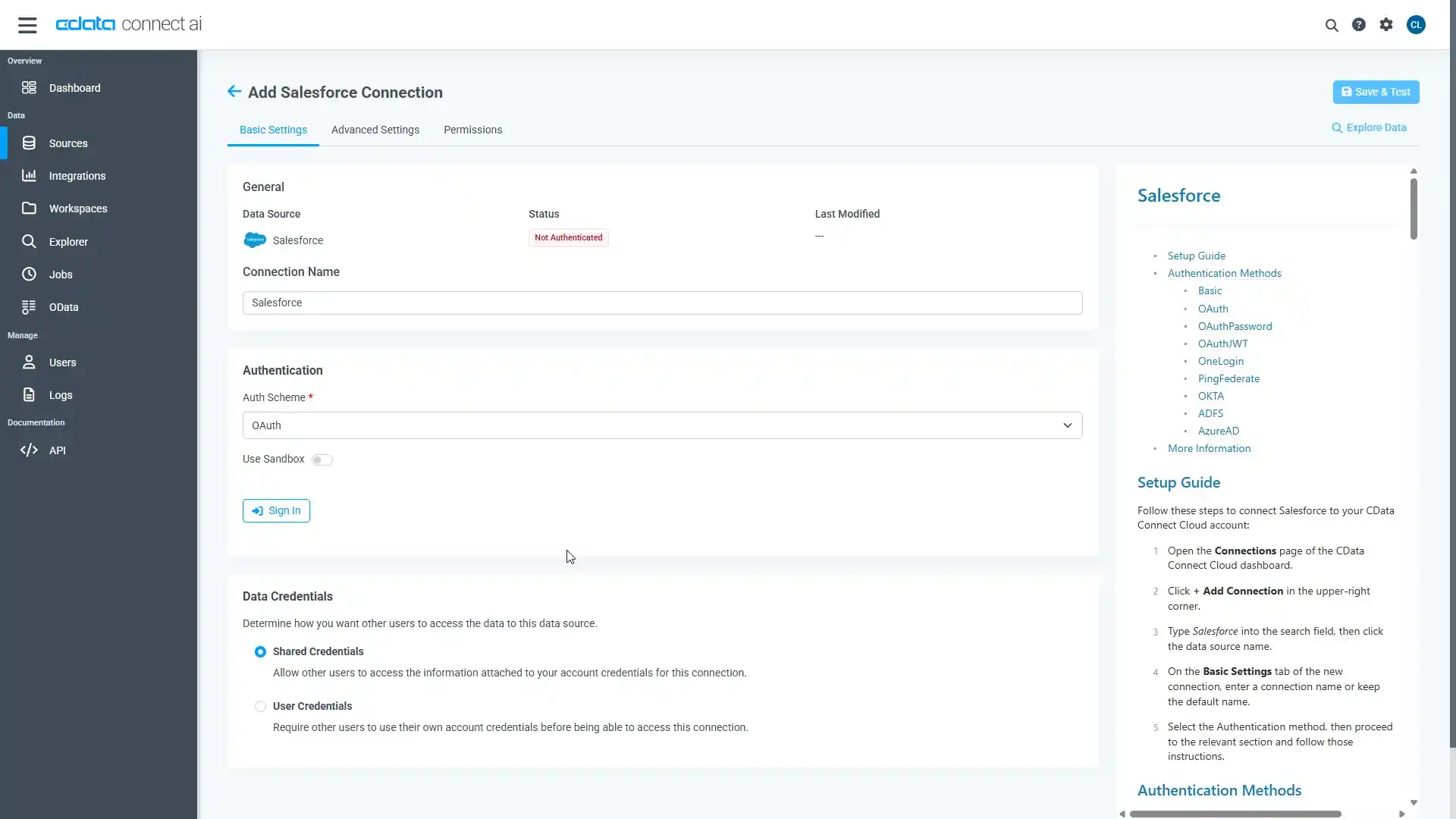
- Create & Test をクリックします。
- 「Add Spark Connection」ページの「Permissions」タブに移動し、ユーザーベースのアクセス許可を更新します。
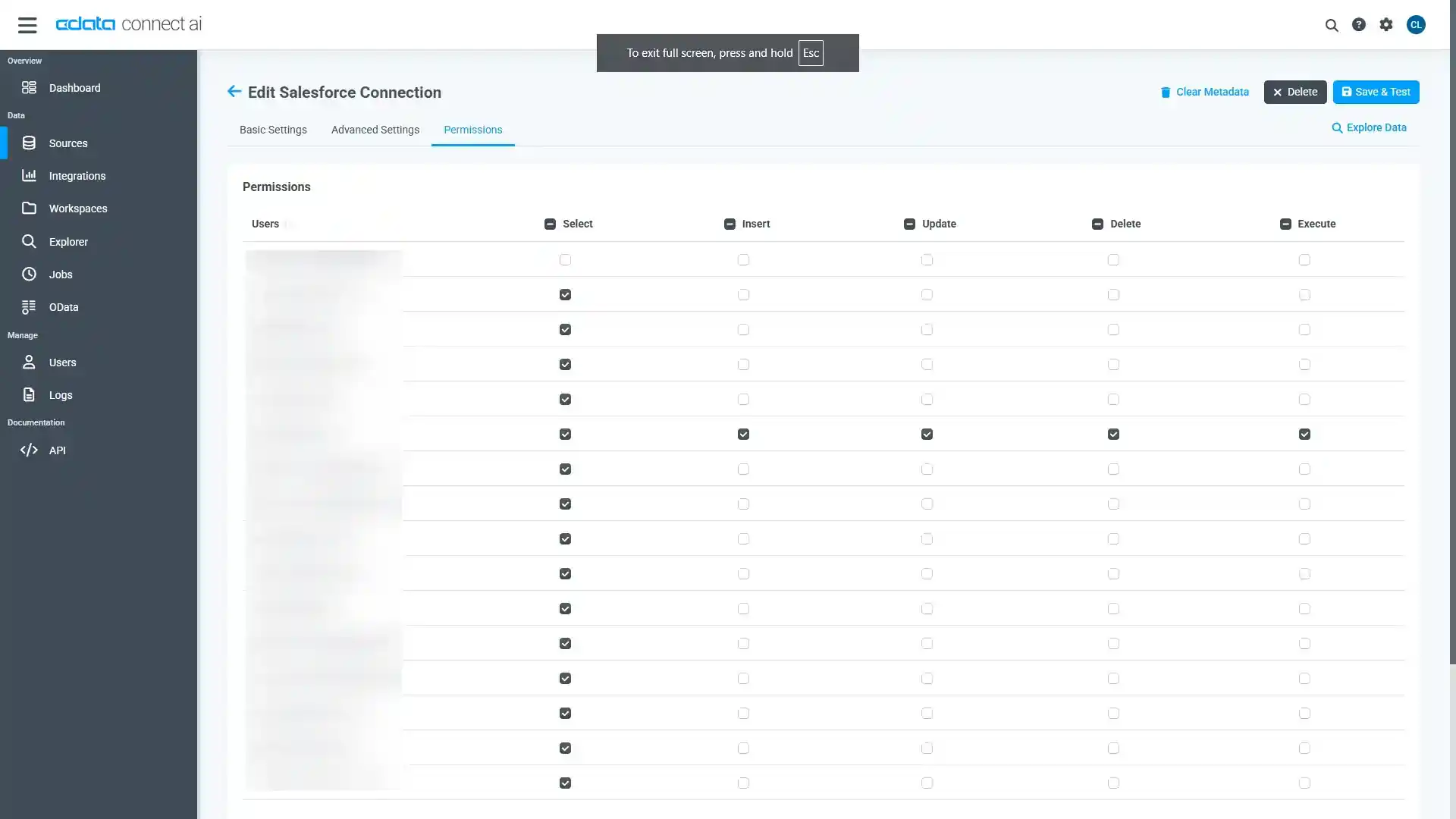
Connect AI にSpark OData エンドポイントを追加する
Spark に接続したら、目的のテーブルのOData エンドポイントを作成します。
- OData ページに移動し、 Add をクリックして新しいOData エンドポイントを作成します。
- Spark 接続(例:SparkSQL1)を選択し、Next をクリックします。
- 使用するテーブルを選択し、「Confirm」をクリックします。
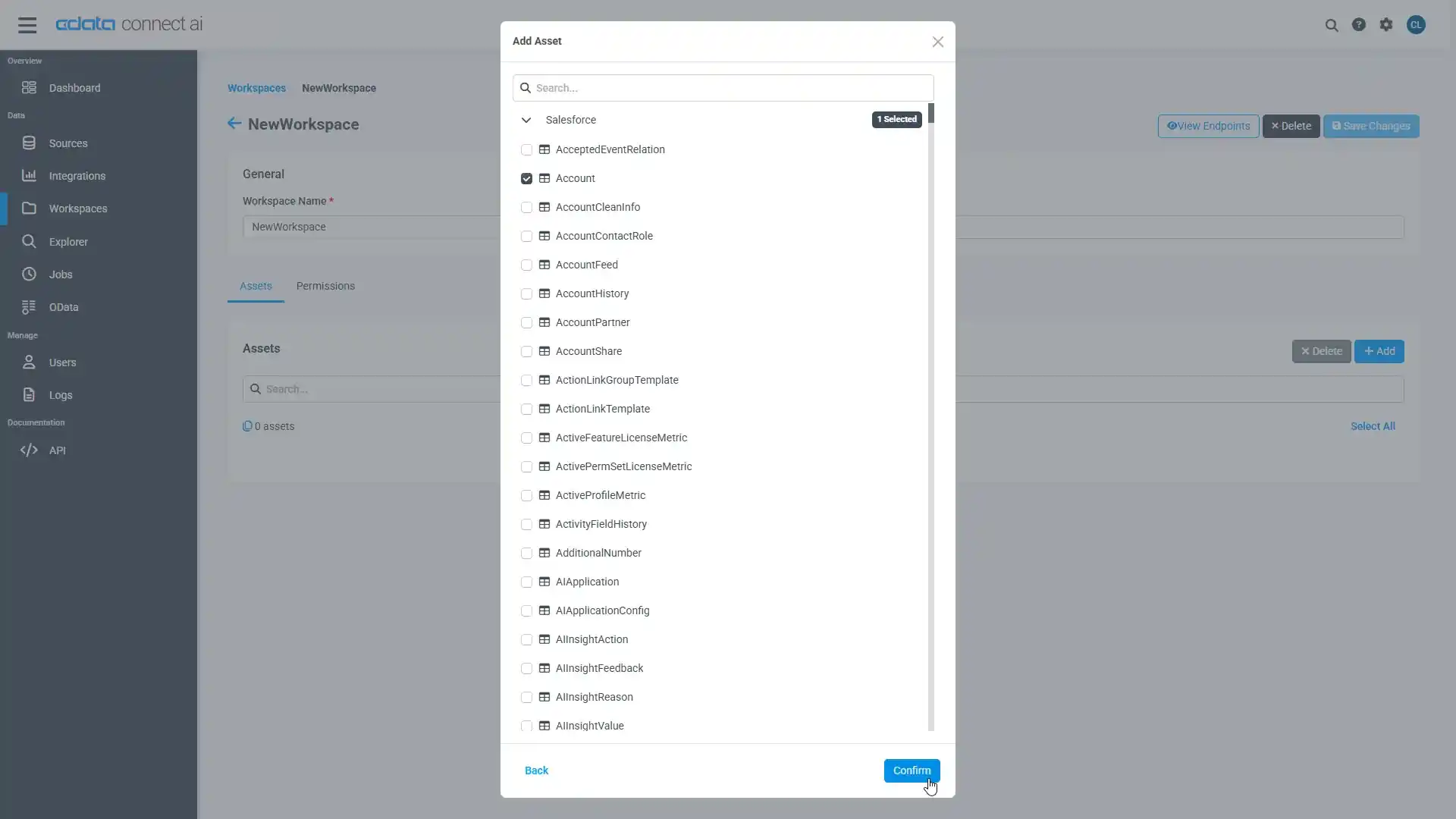
コネクションとOData エンドポイントを設定したら、コラボフローからSpark のデータに接続できます。
Spark のデータに接続したワークフローを作成
コラボフローからConnect AI に連携するためのJavaScript の準備
コラボフロー上で使用するConnect AI との接続用JavaScriptを準備します。
(function () {
'use strict';
// Setting Propeties
const AutocompleteSetting =
{
// Autocomplete target field for Collaboflow
InputName: 'fid0',
// Collaboflow item detils line number
ListRowNumber : 15,
// Autocomplete tartget field for Connect AI
ApiListupFiledColumn : 'sparksql_column',
// Key Column Name for Connect AI resource
ApiListupKeyColumn : 'sparksql_keycolumn',
// Mapping between Collaboflow field and Connect AI column
Mappings: [
{
PartsName: 'fid1', // Collabo flow field name
APIName: 'sparksql_column1' // Connect AI column name
},
{
PartsName: 'fid2',
APIName: 'sparksql_column2'
},
{
PartsName: 'fid3',
APIName: 'sparksql_column3'
},
{
PartsName: 'fid4',
APIName: 'sparksql_column4'
}
]
};
const CDataConnectCloudSetting = {
// Connect AI URL
ConnectCloudUrl : 'http://XXXXXX',
// Connect AI Resource Name
ConnectCloudResourceName : 'sparksql_table',
// Connect AI Key
Headers : { Authorization: 'Basic YOUR_BASIC_AUTHENTICATION' },
// General Properties
ParseType : 'json',
get BaseUrl() {
return CDataCloudServerSetting.ApiServerUrl + '/api.rsc/' + CDataCloudServerSetting.ApiServerResourceName
}
}
let results = [];
let records = [];
// Set autocomplete processing for target input field
collaboflow.events.on('request.input.show', function (data) {
for (let index = 1; index < AutocompleteSetting.ListRowNumber; index++) {
$('#' + AutocompleteSetting.InputName + '_' + index).autocomplete({
source: AutocompleteDelegete,
autoFocus: true,
delay: 500,
minLength: 2
});
}
});
// This function get details from Connect AI, Then set values at each input fields based on mappings object.
collaboflow.events.on('request.input.' + AutocompleteSetting.InputName + '.change', function (eventData) {
debugger;
let tartgetParts = eventData.parts.tbl_1.value[eventData.row_index - 1];
let keyId = tartgetParts[AutocompleteSetting.InputName].value.split(':')[1\;
let record = records.find(x => x[AutocompleteSetting.ApiListupKeyColumn] == keyId);
if (!record)
return;
AutocompleteSetting.Mappings.forEach(x => tartgetParts[x.PartsName].value = '');
AutocompleteSetting.Mappings.forEach(x => tartgetParts[x.PartsName].value = record[x.APIName]);
});
function AutocompleteDelegete(req, res) {
let topParam = '&$top=10'
let queryParam = '$filter=contains(' + AutocompleteSetting.ApiListupFiledColumn + ',\'' + encodeURIComponent(req.term) + '\')';
collaboflow.proxy.get(
CDataCloudServerSetting.BaseUrl + '?' +
queryParam +
topParam,
CDataCloudServerSetting.Headers,
CDataCloudServerSetting.ParseType).then(function (response) {
results = [];
records = [];
if (response.body.value.length == 0) {
results.push('No Results')
res(results);
return;
}
records = response.body.value;
records.forEach(x => results.push(x[AutocompleteSetting.ApiListupFiledColumn] + ':' + x[AutocompleteSetting.ApiListupKeyColumn]));
res(results);
}).catch(function (error) {
alert(error);
});
}
})();
- 「CDataConnectCloudSetting」のそれぞれのプロパティには構成したSSH Server のURL とConnect AI の認証情報をそれぞれ設定してください。
- 「AutocompleteSetting」はどのフィールドでオートコンプリートを動作させるか? といった設定と、API のプロパティとのマッピングを行います。
- 今回はコラボフローのデフォルトテンプレートで提供されている「12a.見積書・注文書」で利用しますので、デフォルトでは商品名のフィールドを、Product テーブルのName と紐付けて、Autocomplete を行うように構成しています。値が決定されたら、Key となるProductID を元に「型番、標準単価、仕入単価、御提供単価」をそれぞれAPI から取得した値で自動補完するようになっています。
コラボフロー側でJavaScript を登録
JavaScript を作成したら、後はコラボフローにアップするだけです。
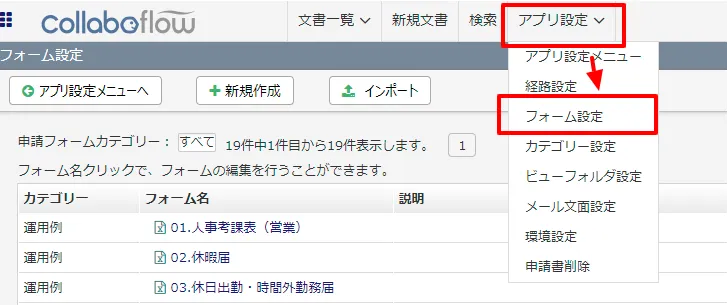
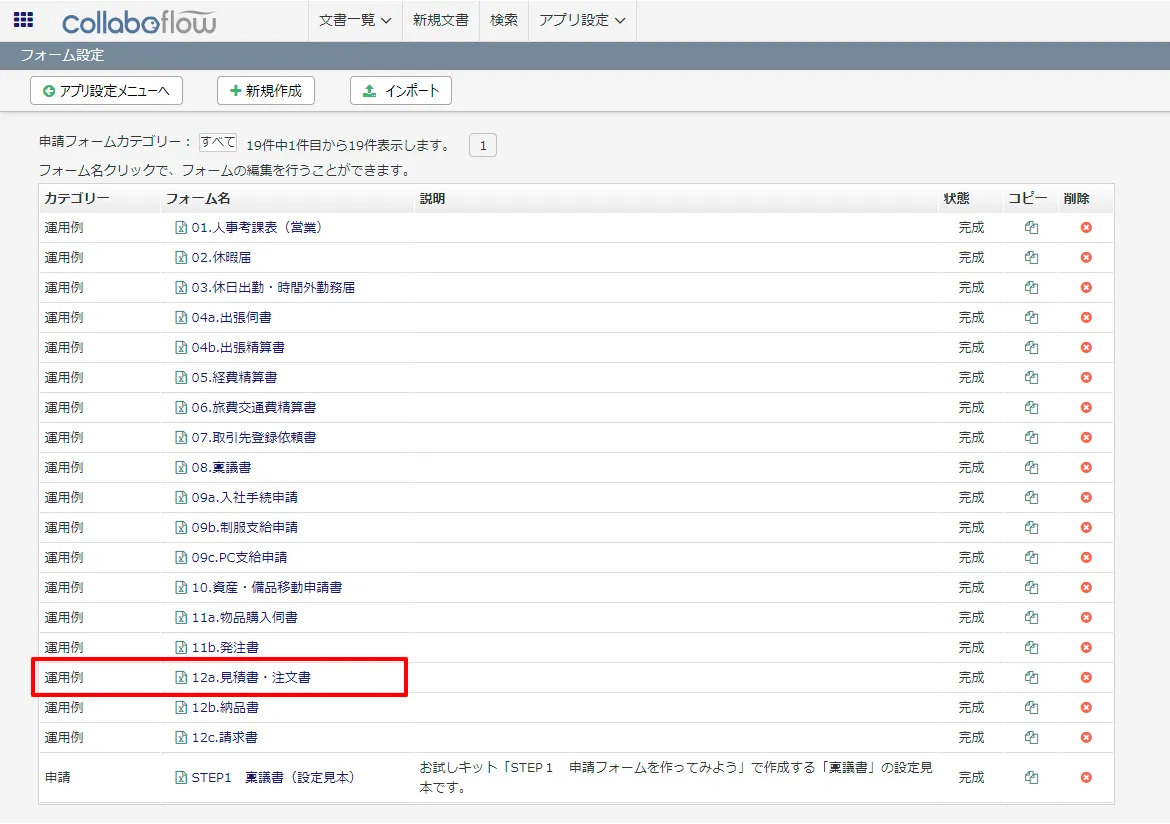
- コラボフローにログインし「アプリ設定」→「フォーム設定」に移動します。
- フォーム一覧から使用するフォームを選択します。
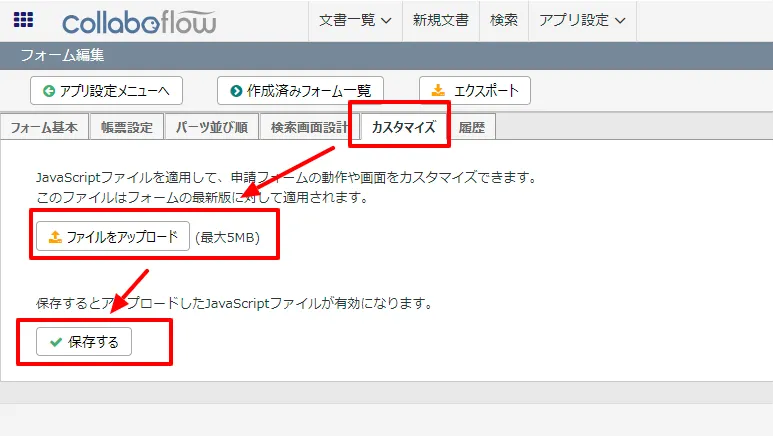
- フォーム編集画面に移動後、「カスタマイズ」タブをクリックし、ファイルをアップロードから作成したJSファイルをアップロードし、保存します。
- これでConnect AI 経由でSpark のデータを取得し、自動入力補完する機能がコラボフローの申請フォームに追加できました。
クラウドアプリケーションからSpark のデータへのライブ接続
コラボフローからSpark のリアルタイムデータに直接接続できるようになりました。これで、Spark のデータを複製せずにより多くの接続とアプリを作成できます。
クラウドアプリケーションから直接100を超えるSaaS 、ビッグデータ、NoSQL ソースへのリアルタイムデータアクセスを取得するには、CData Connect AI を参照してください。