





Azure Analysis Services を使ってSpark のデータをモデル化する方法

Azure Analysis Services(AAS)は、エンタープライズレベルのデータモデルをクラウド上で提供する、フルマネージドのPaaS です。Azure 上で提供されているので、お馴染みの環境で手軽に使い始められます。CData Connect AI と連携することで、Spark のデータをAAS に繋いでBI ツール向けのデータモデルを簡単に作成できます。 この記事ではConnect AI からSpark に接続し、AAS の拡張機能を有効にしたVisual Studio でSpark のデータをインポートする方法を紹介します。
Connect AI からSpark への接続
CData Connect AI を使うと、直感的なクリック操作ベースのインターフェースを使ってデータソースに接続できます。
- Connect AI にログインし、 Add Connection をクリックします。
- Add Connection パネルで「Spark」を選択します。
-
必要な認証プロパティを入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
- Create & Test をクリックします。
-
(任意の設定)「Add Spark Connection」ページの「Permissions」タブに移動し、アクセス許可を更新します。

パーソナルアクセストークンの取得
OAuth 認証をサポートしていないサービス、アプリケーション、プラットフォーム、またはフレームワークから接続する場合は、認証に使用するパーソナルアクセストークン(PAT)を作成できます。 きめ細かなアクセス管理を行うために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
- Connect AI アプリの右上にあるユーザー名をクリックし、User Profile をクリックします。
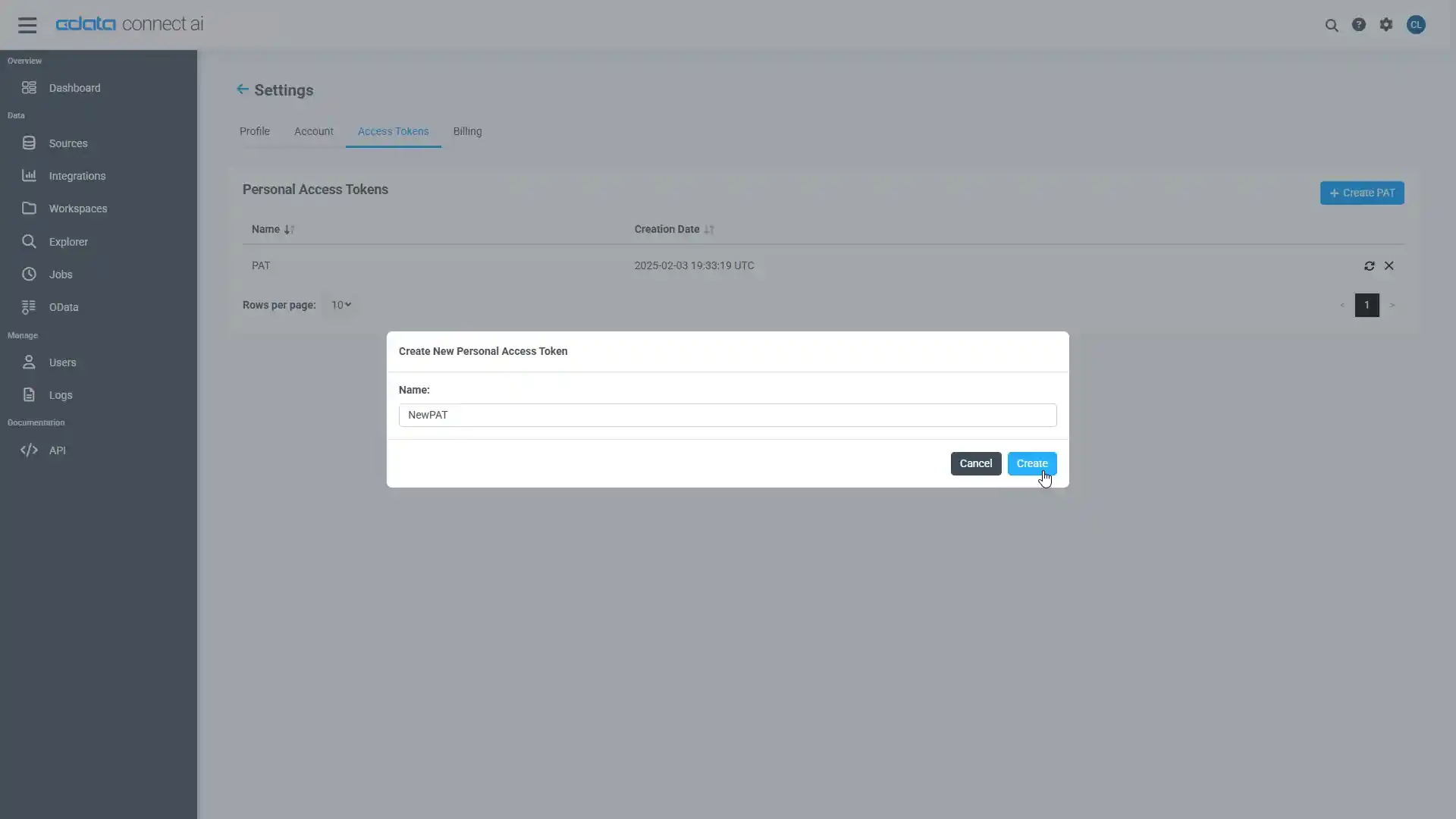
- User Profile ページでPersonal Access Token セクションにスクロールし、 Create PAT をクリックします。
- PAT の名前を入力して Create をクリックします。
- パーソナルアクセストークンは作成時にしか表示されないため、必ずコピーして安全に保存してください。
接続の設定が完了したら、Azure Analysis Services を使用してVisual Studio からSpark のデータに接続できるようになります。
AAS を使ってVisual Studio からSpark に接続
以下のステップでは、Visual Studio からAzure Analysis Services にからCData Connect AI に接続して新しいSpark のデータソースを作成する方法を説明します。 続けるには、Microsoft Analysis Services Projects の拡張機能が必要です。拡張機能はこちらからダウンロードできます。
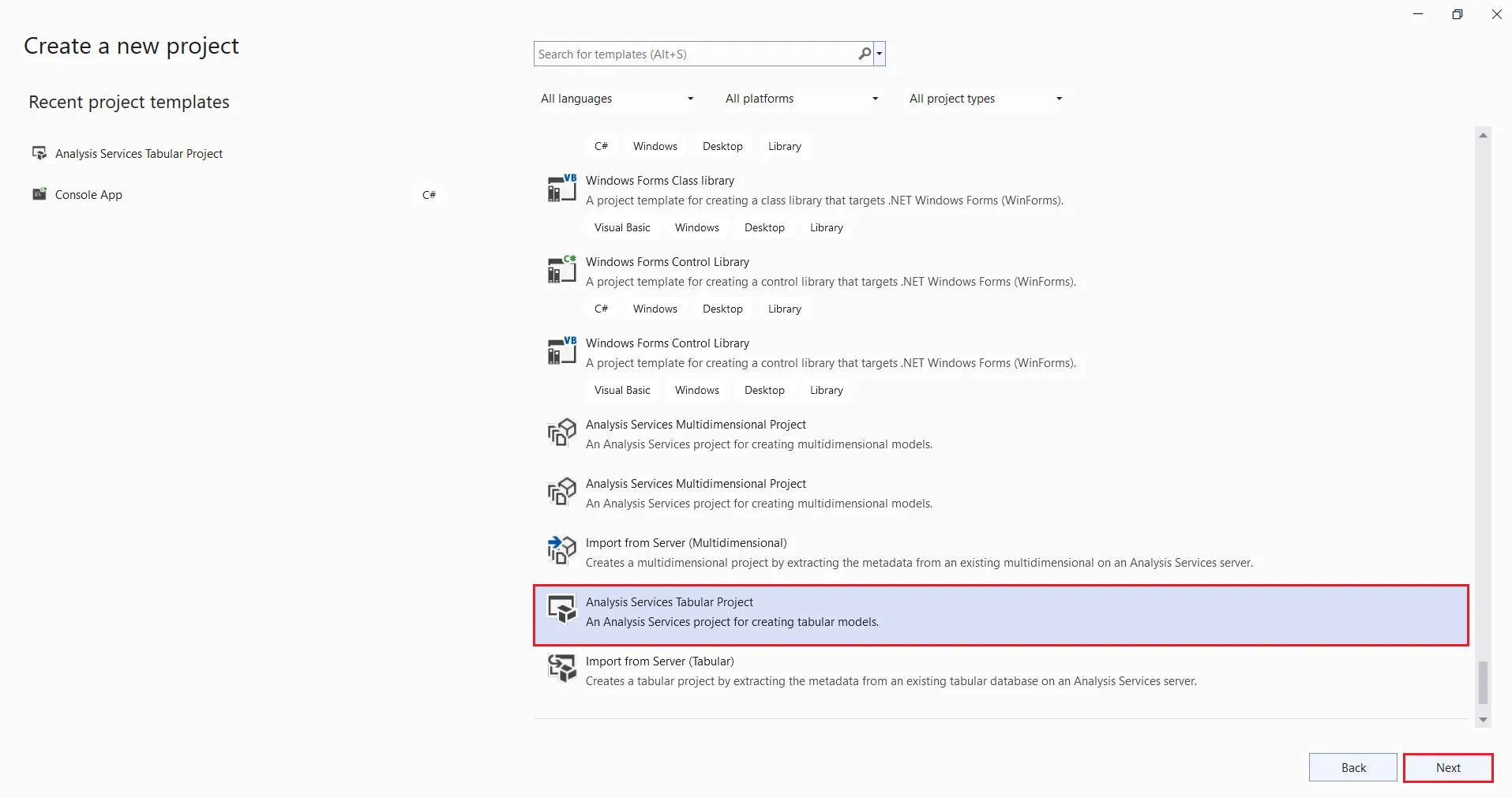
- 拡張機能をインストールしたら、Visual Studio で新しいプロジェクトを作成しましょう。「Analysis Services 表形式プロジェクト」を選択します。
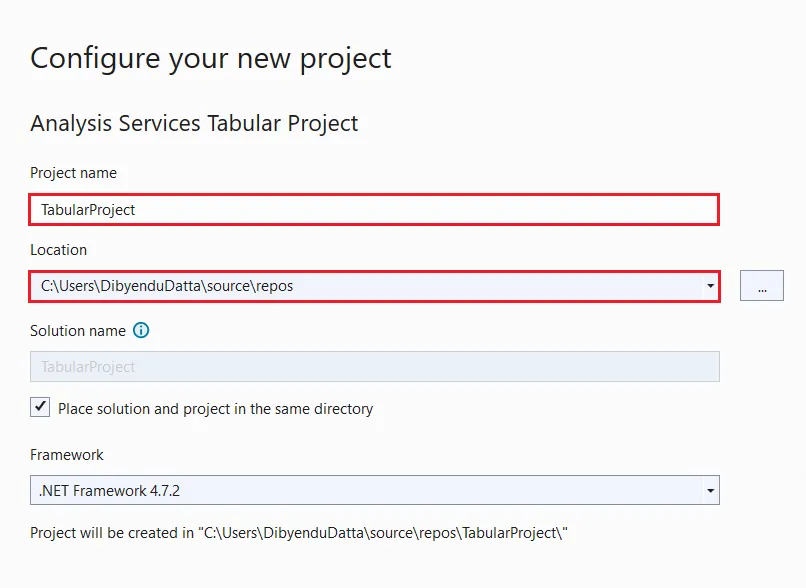
- 「新しいプロジェクト構成します」ダイアログが表示されるので、フィールドに必要な項目を入力します。
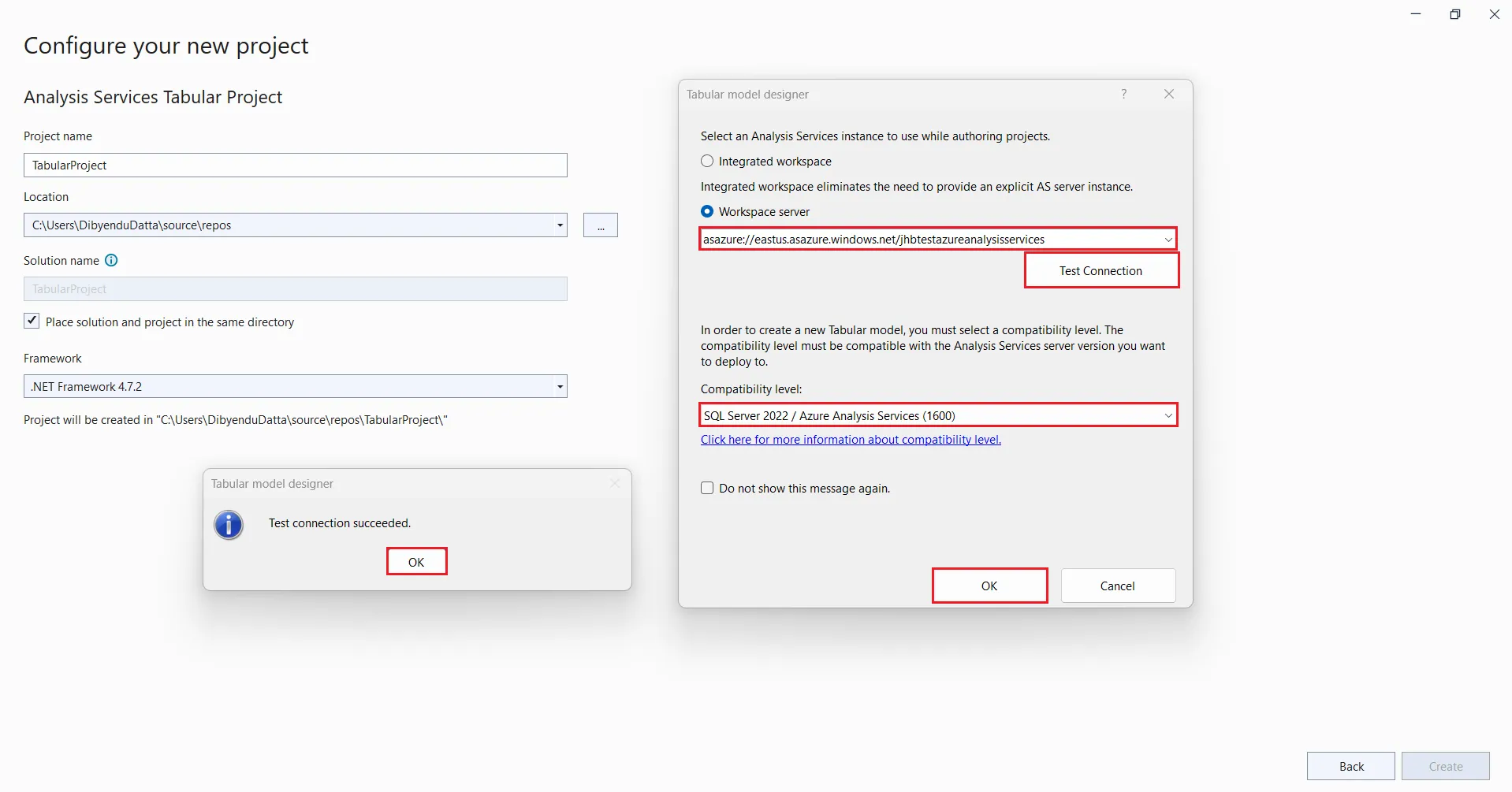
- 「作成」をクリックします。「テーブルモデルデザイナー」ダイアログボックスが開きます。ワークスペースサーバーを選択し、Azure Analysis Services サーバーのアドレス(例:asazure://eastus.azure.windows.net/myAzureServer)を入力します。 Test Connection をクリックし、サーバーにサインインします。
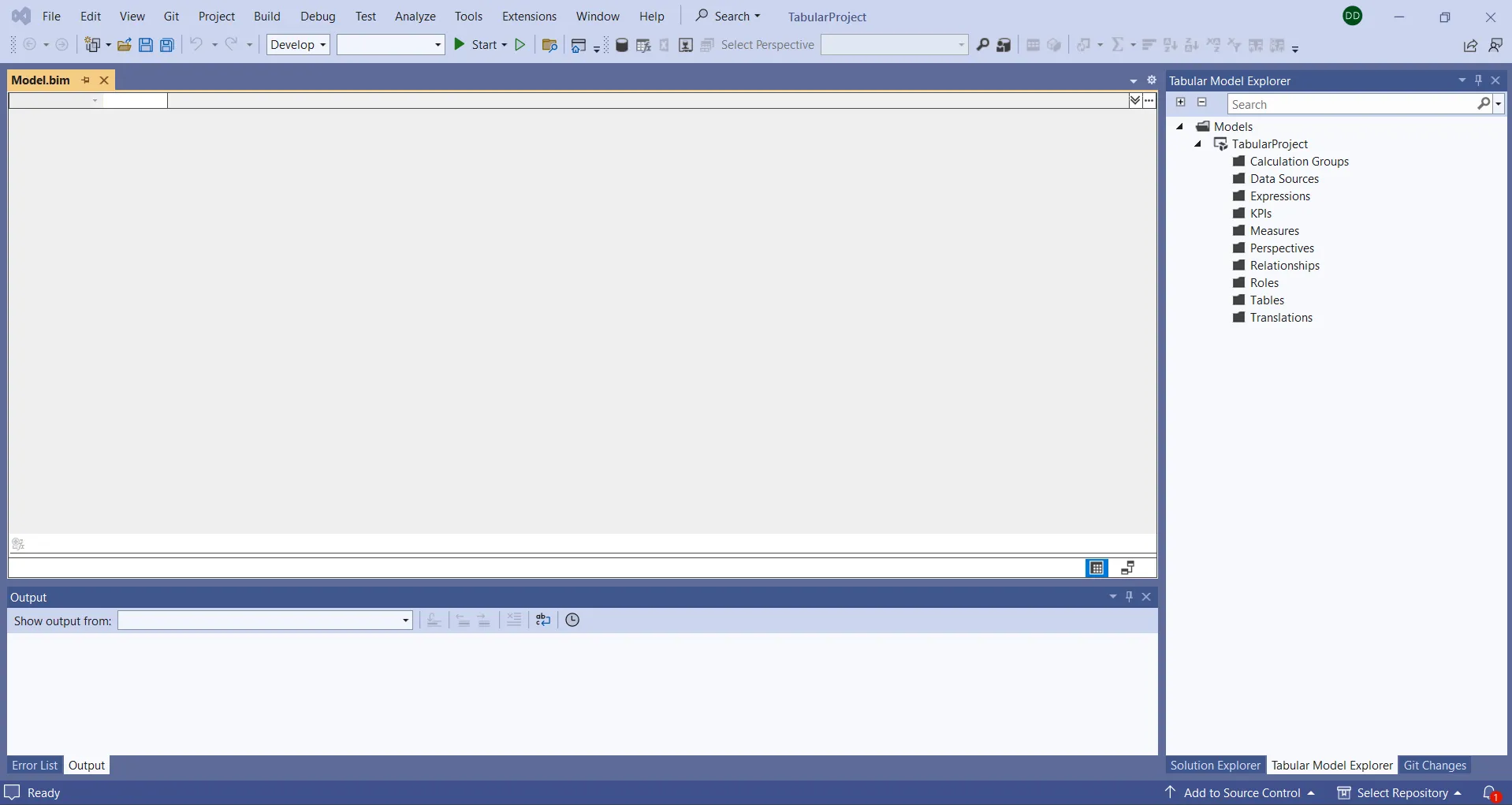
- OK をクリックしてプロジェクトを作成します。Visual Studio ウィンドウは、以下のスクリーンショットのようになります。
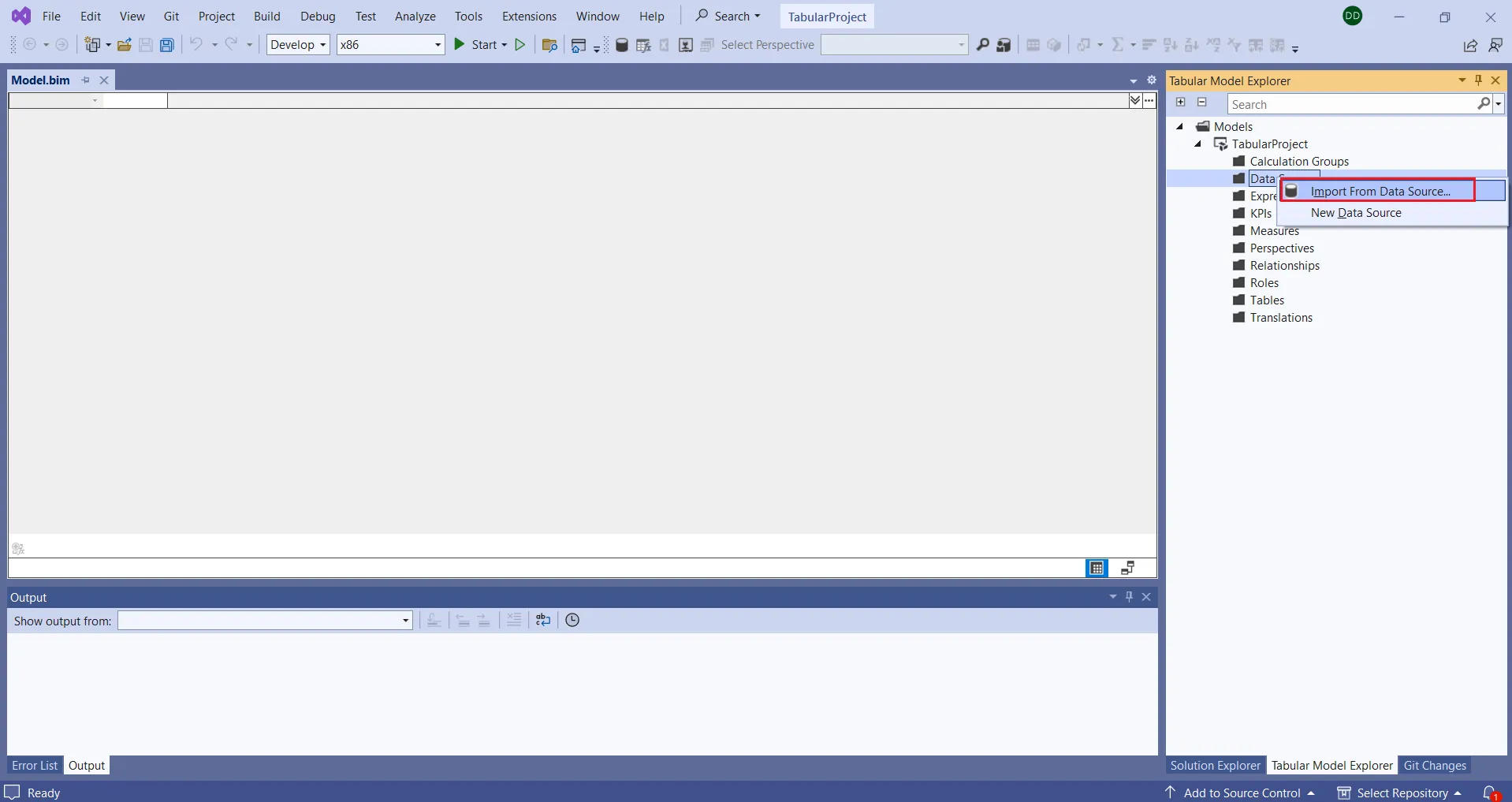
- Visual Studio の表形式モデルエクスプローラーで、データソースを右クリックして「データソースからインポート」を選択します。
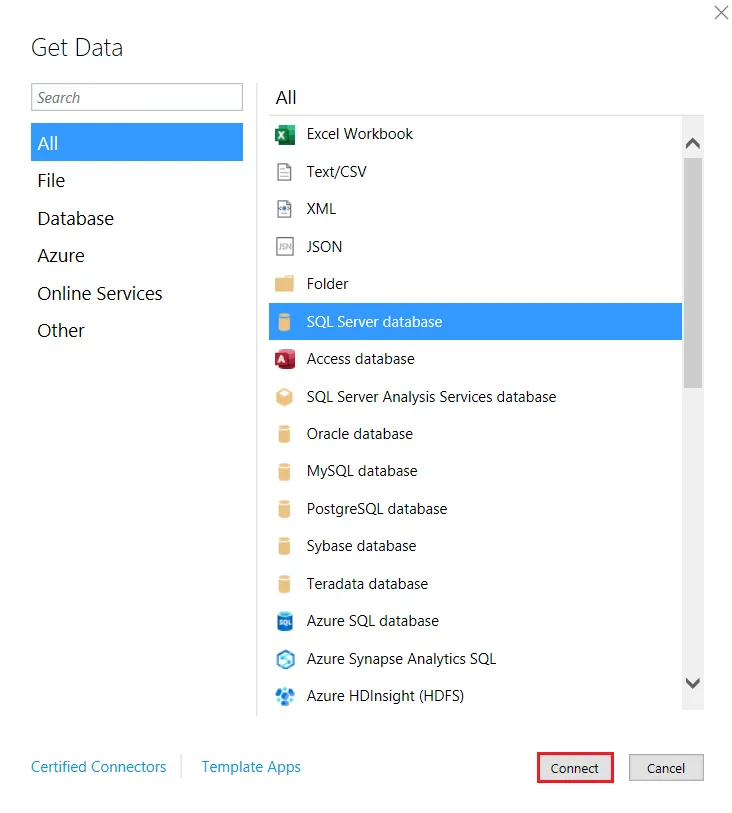
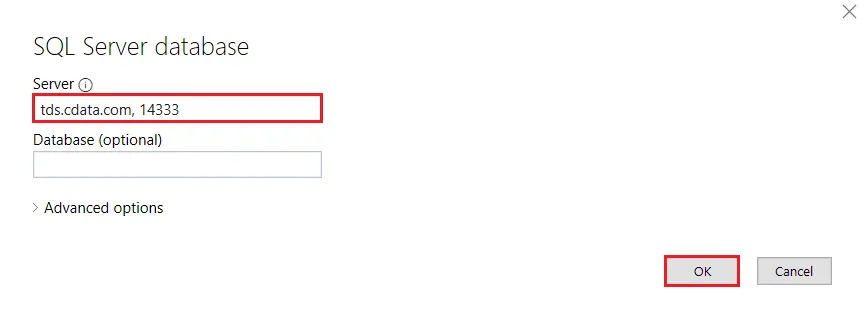
- Table Import Wizard で、SQL Server データベースを選択してConnect をクリックします。Server フィールドに、仮想SQL Server のエンドポイントとポートをカンマで区切って入力します(例:tds.cdata.com,14333)。
-
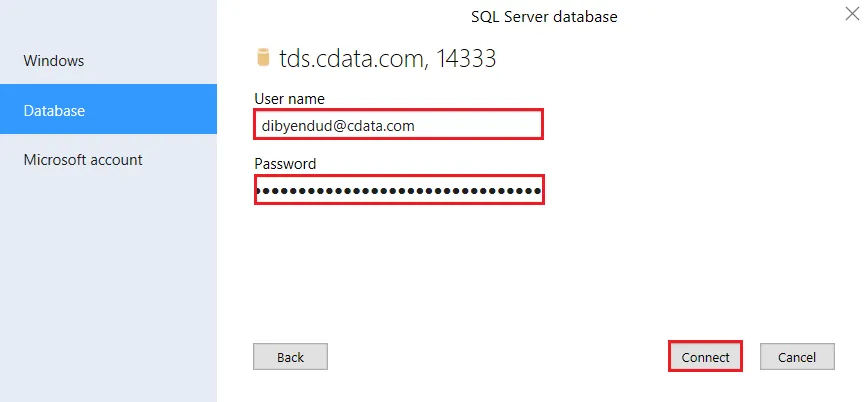
SQL Server Authentication をクリックして、次の情報を入力します。
- User name:CData Connect AI のユーザー名を入力します。ユーザー名はCData Connect AI のインターフェースの右上に表示されています(例:test@cdata.com)。
- Password:Settings ページで生成したPAT を入力します。
- 次の画面で、Current User を選択してNext をクリックします。
- ここでは、最初のオプションを選択してNext をクリックします。
- 次の画面で、リストからテーブルを選択してPreview & Filter をクリックします。
- テーブルにSpark からデータが入力されたことを確認できます。

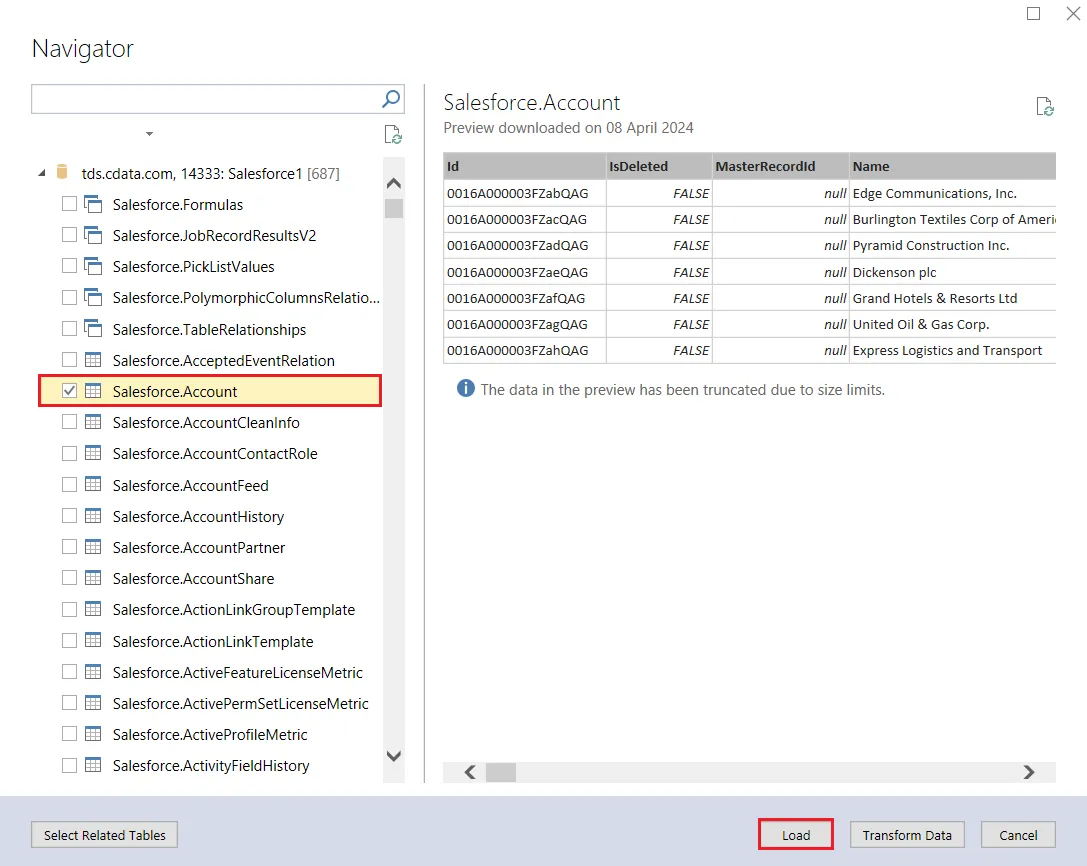
これでSpark のデータをデータモデルにインポートできたので、Azure Analysis Services にプロジェクトをデプロイして、BI ツールやクライアントアプリケーションなどから利用できます。
おわりに
CData Connect AI の14日間無償トライアルを利用して、クラウドアプリケーションから直接100を超えるSaaS、ビッグデータ、NoSQL データソースへのSQL アクセスをお試しください。