





エンタープライズサーチのNeuron にSharePoint のデータを取り込んで検索利用

ブレインズテクノロジー社のNeuron は、先端OSS 技術(Apache Solr)を活用したエンタープライズサーチ(企業内検索エンジン)サービスです。Apache Solr は、エンタープライズサーチ機能をAPI として提供してくれますが、Neuron はApache Solr に企業ユーザーがデータを探索するためのシンプルかつ使いやすいユーザーインターフェースと管理画面・運用機能を提供してくれます。これによりエンドユーザーが簡単にエンタープライズサーチを利用することができます。管理画面では、ファイルやデータのクローリング設定がUI で行えるようになっています。この記事では、Neuron に備わっているJDBC インターフェース経由で、CData JDBC Driver for SharePoint を利用することでNeuron にSharePoint のデータを取り込んで検索で利用できるようにします。
Neuron にCData JDBC Driver for SharePoint データをロード
CData JDBC Driver for SharePoint のインストールと.jar ファイルの配置
- CData JDBC Driver for SharePoint をNeuron と同じマシンにインストールします。
-
以下のパスにJDBC Driver がインストールされます。
C:\Program Files\CData\CData JDBC Driver for SharePoint 20xxJ\lib\cdata.jdbc.sharepoint.jar
-
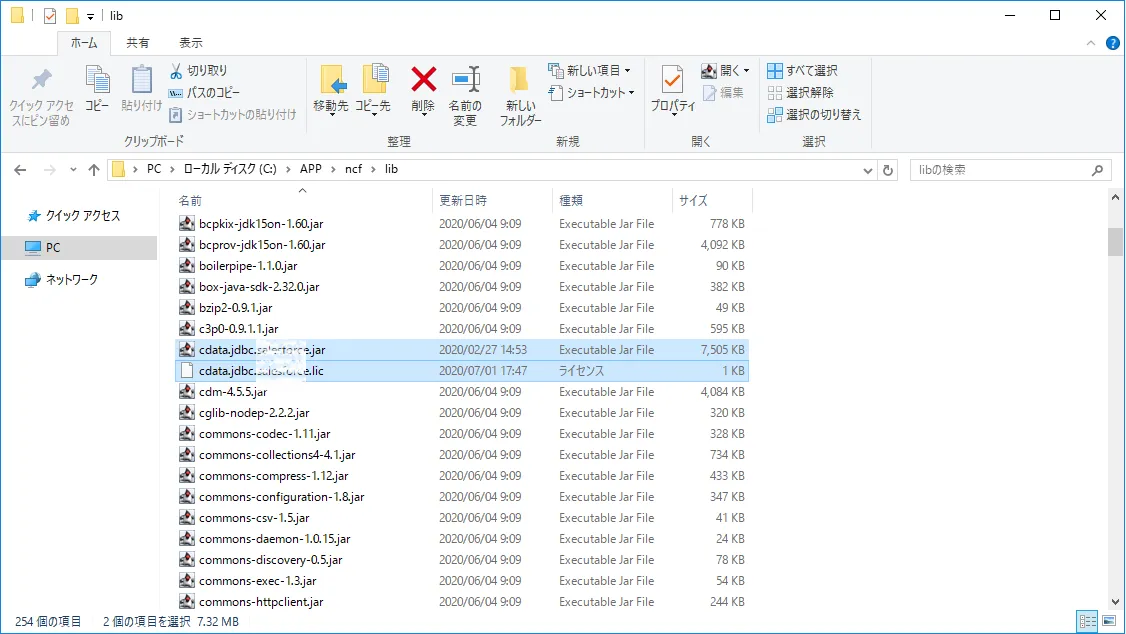
このcdata.jdbc.sharepoint.jar とcdata.jdbc.sharepoint.lic ファイルをコピーして、Neuron のC:\APP
cf\lib フォルダに配置します。
Neuron CF でのSharePoint のデータを扱うリポジトリの作成
-
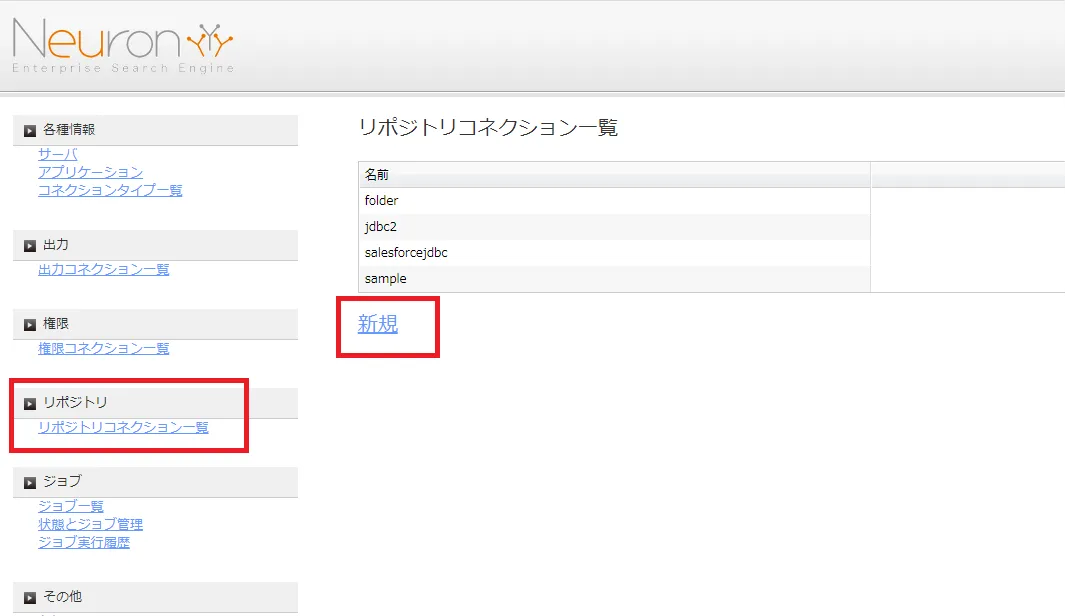
Neuron CF でクローラーの設定をGUI で行います。JDBC を読み取るためのリポジトリを作成します。Neuron の管理画面にログインし、[リポジトリ]→[リポジトリコレクション一覧]→[新規]をクリックします。
-
任意のリポジトリ名を入力します。タイプは[JDBC]を選択します。

-
次に、ドライバーのクラス名とJDBC 接続文字列でSharePoint への接続を行います。
Microsoft SharePoint への接続
URL の設定:
Microsoft SharePoint では、2つの範囲でデータを操作できます。グローバルなMicrosoft SharePoint サイト全体を対象にするか、個々のサイトのみを対象にするかを選択できます。
グローバルなMicrosoft SharePoint サイトですべてのリストおよびドキュメントを操作したい場合は、URL 接続プロパティをサイトコレクションURL に設定しましょう。以下のような形式です。
https://teams.contoso.com
個々のサイトのリストおよびドキュメントのみを扱いたい場合は、URL 接続プロパティを個々のサイトURL に設定してください。以下のような形式です。
https://teams.contoso.com/TeamA
続いて、お使いの環境に適した認証プロパティを設定していきましょう。詳細な設定手順については、 href="/kb/help/" target="_blank">ヘルプドキュメントの「はじめに」をご参照ください。
Microsoft SharePoint Online
SharePointEdition を"SharePoint Online" に設定し、User およびPassword にはSharePoint へのログオンで使用するクレデンシャル(例:Microsoft Online Services アカウントのクレデンシャル)を設定します。
Microsoft SharePoint Online は様々なクラウドベースアーキテクチャをサポートしており、それぞれ異なる認証スキームが利用できます。
- Microsoft Entra ID(Azure AD)
- ADFS、Okta、OneLogin、またはPingFederate SSO ID プロバイダーを介したシングルサインオン(SSO)
- Azure MSI
- Azure パスワード
- OAuthJWT
- SharePointOAuth
Microsoft SharePoint オンプレミス
Microsoft SharePoint オンプレミスでは、多くのオンプレミス環境に対応した認証方式をサポートしています。
- Windows(NTLM)
- Kerberos
- ADFS
- 匿名アクセス
まずSharePointEdition を"SharePoint On-Premises" に設定しましょう。
Windows(NTLM)認証
これは最も一般的な認証方式です。そのため、CData 製品ではNTLM をデフォルトとして使用するよう事前設定されています。Windows のUser およびPassword を設定するだけで接続できます。
ドライバクラス名:cdata.jdbc.sharepoint.SharePointDriver
接続文字列:jdbc:sharepoint:User=myuseraccount;Password=mypassword;Auth Scheme=NTLM;URL=http://sharepointserver/mysite;SharePointEdition=SharePointOnPremise;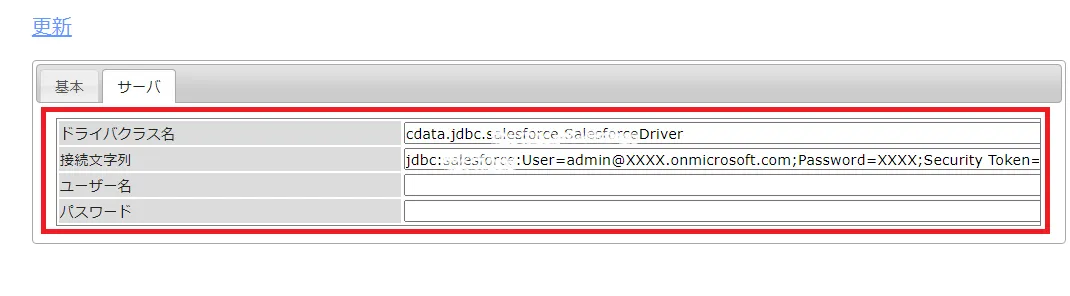
- [更新]をクリックして、SharePoint に接続するリポジトリコレクションができました。
Neuron でSharePoint のデータをクローリングするジョブを作成
続いて、SharePoint のどのデータをどのようにクローリングするのかをジョブで定義していきます。
-
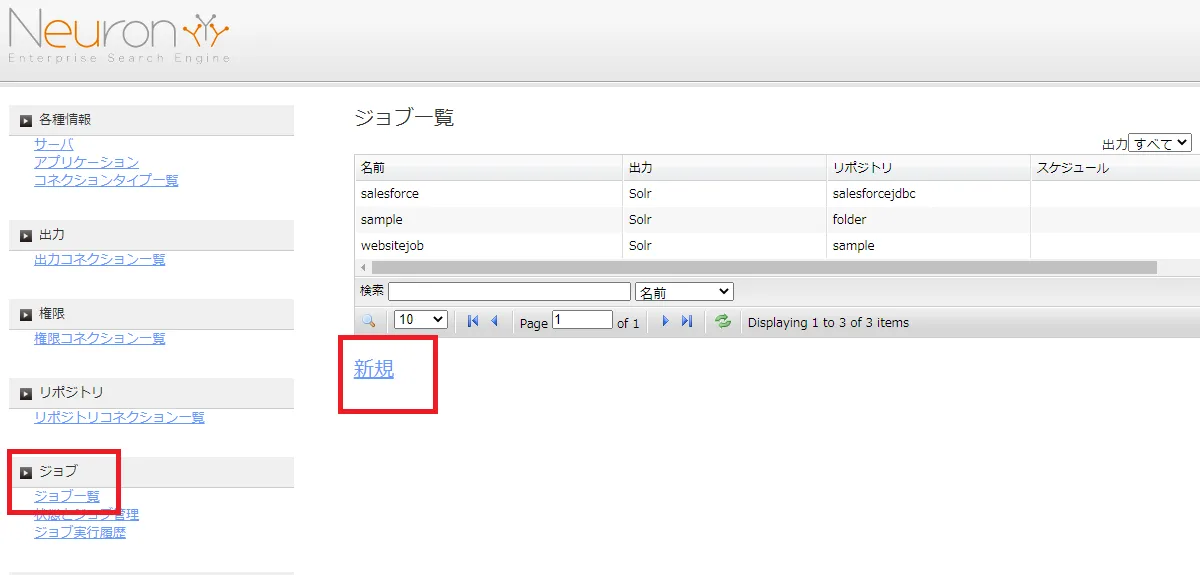
管理画面で[ジョブ]→[ジョブ一覧]→[新規]とクリックします。
-
任意のジョブ名を入力します。出力先にはSolr を選択します。リポジトリは先ほど作成したSharePoint に接続するリポジトリコレクションを選びます。
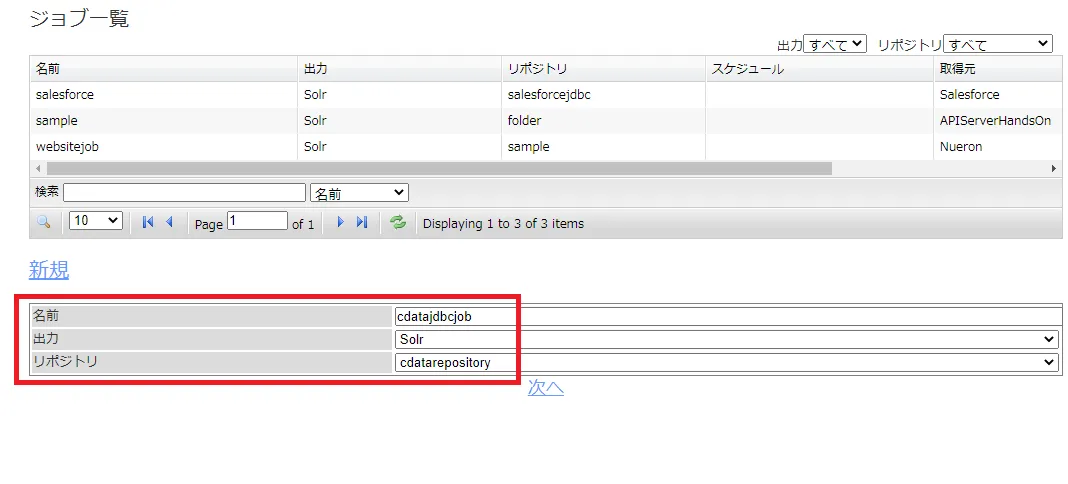
-
次に基本タブからジョブ実行を手動にするか、定期実行するかを自由に設定します。
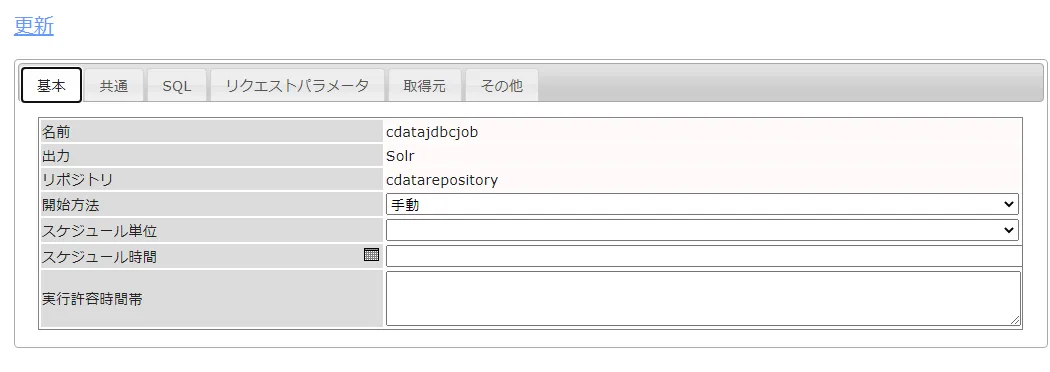
-
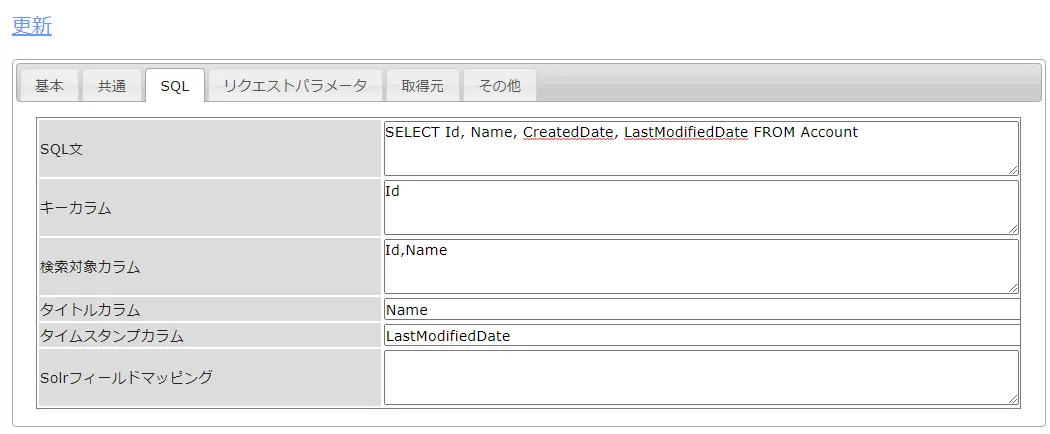
SQL タブでは、どんなデータを取得するのか、テーブル名やカラム、フィルタリング条件などを設定できます。CData JDBC ドライバがSharePoint のデータをテーブルにモデル化しているので、標準SQL でSharePoint をクエリすることができます。
- SQL文:SELECT Name, Revenue FROM MyCustomList
- キーカラム:Id など取得テーブルのキーとなるカラム
- 検索対象カラム:検索の対象とするカラム
- タイトルカラム:検索結果のタイトルとするカラム
- タイムスタンプカラム:タイムスタンプとなるカラムがあれば、ここで指定します
- リクエストパラメータでは、検索結果レコードのURL (があれば)を設定することもできます。URL を表示できると表示された検索結果からレコードに簡単に移動できます。
- 取得元では、ラベルを設定しておきます。[更新]をクリックして、クローラージョブの設定を完了します。
Neuron でSharePoint のデータをクロールするジョブを実行
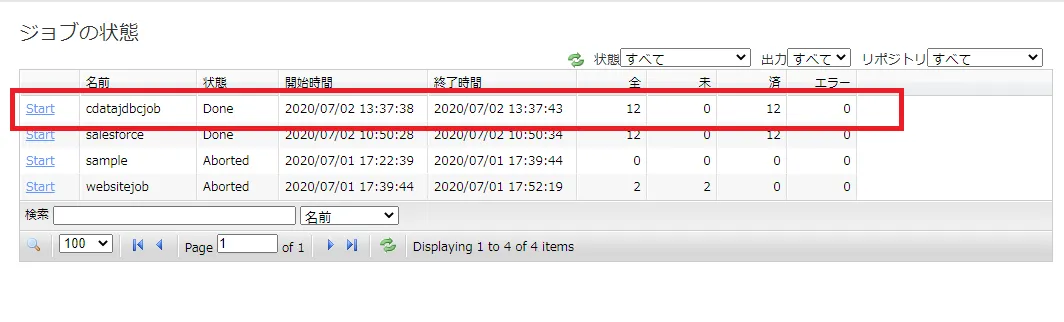
実際にNeuron で作成したジョブを実行します。[ジョブ]→[状態とジョブ管理]をクリックし、作成したジョブの[Start]をクリックします。
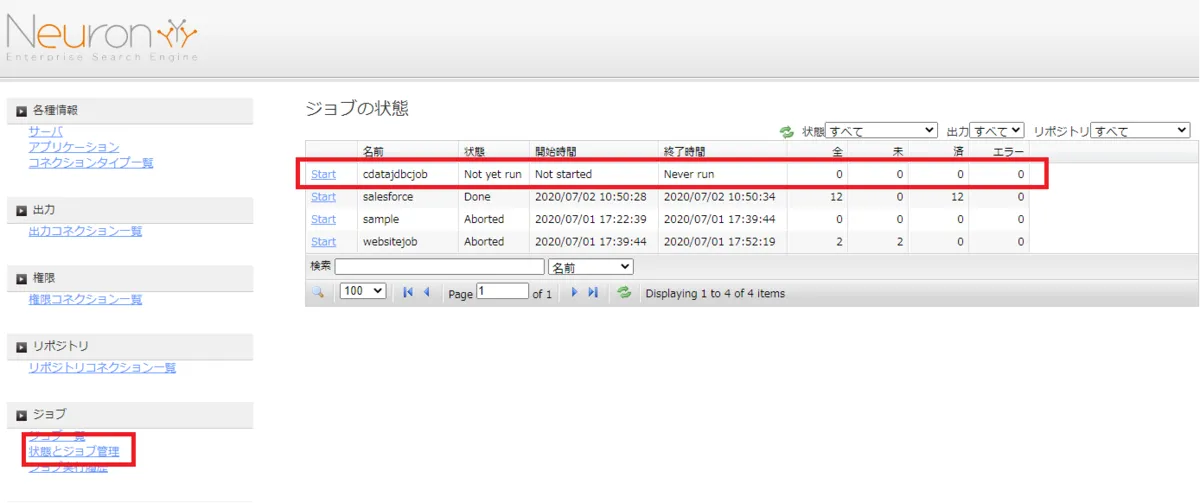
ジョブが正常完了すると、[Done]がステータスとして表示されます。
Neuron 上でのSharePoint のデータの検索の実施
実際にNeuron 上で検索ができるか確認してみます。取得元を絞り込むこと、内容やファイル名での検索、ファイルサイズやファイル更新日の絞り込み、部分一致や全部一致で検索が可能です。 検索をかけてみると、以下のようにデータを取得できました。
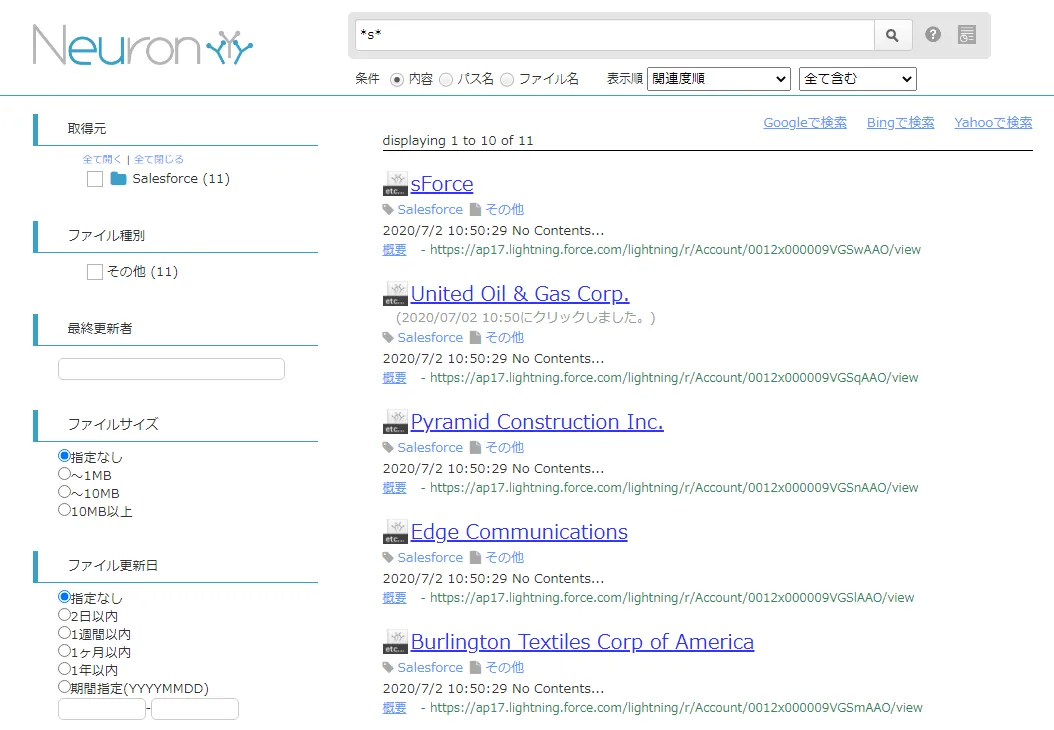
CData JDBC Driver for SharePoint をNeuron で使うことで、SharePoint コネクタとして機能し、簡単にデータを取得して同期することができました。ぜひ、30日の無償評価版をお試しください。
はじめる準備はできましたか?
SharePoint Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード詳細:
Java 開発者は、Web、デスクトップ、およびモバイルアプリケーションをSharePoint Server のリスト、連絡先、カレンダー、リンク、タスクなどのデータに簡単に接続できるようになります。