





【ノーコード】Redshift のデータを複数のデータベースにレプリケーション。

常時起動のアプリケーションは、自動フェイルオーバー機能およびリアルタイムなデータアクセスを必要とします。CData Sync は、リアルタイムRedshift のデータをミラーリングデータベース、上記稼働のクラウドデータベース、レポーティングサーバーなどのほかのデータベースに連携し、Windows からリモートRedshift に接続し、自動的に同期を取ります。
レプリケーションの同期先の設定
CData Sync を使って、Redshift をクラウド・オンプレにかかわらず複数のデータベースレプリケーションします。レプリケーションの同期先を追加するには、[接続]タブを開きます。
それぞれのデータベース向けに以下を行います:
- [同期先]タブをクリックします。
- 同期先を選択します。この記事では、SQLite を使います。
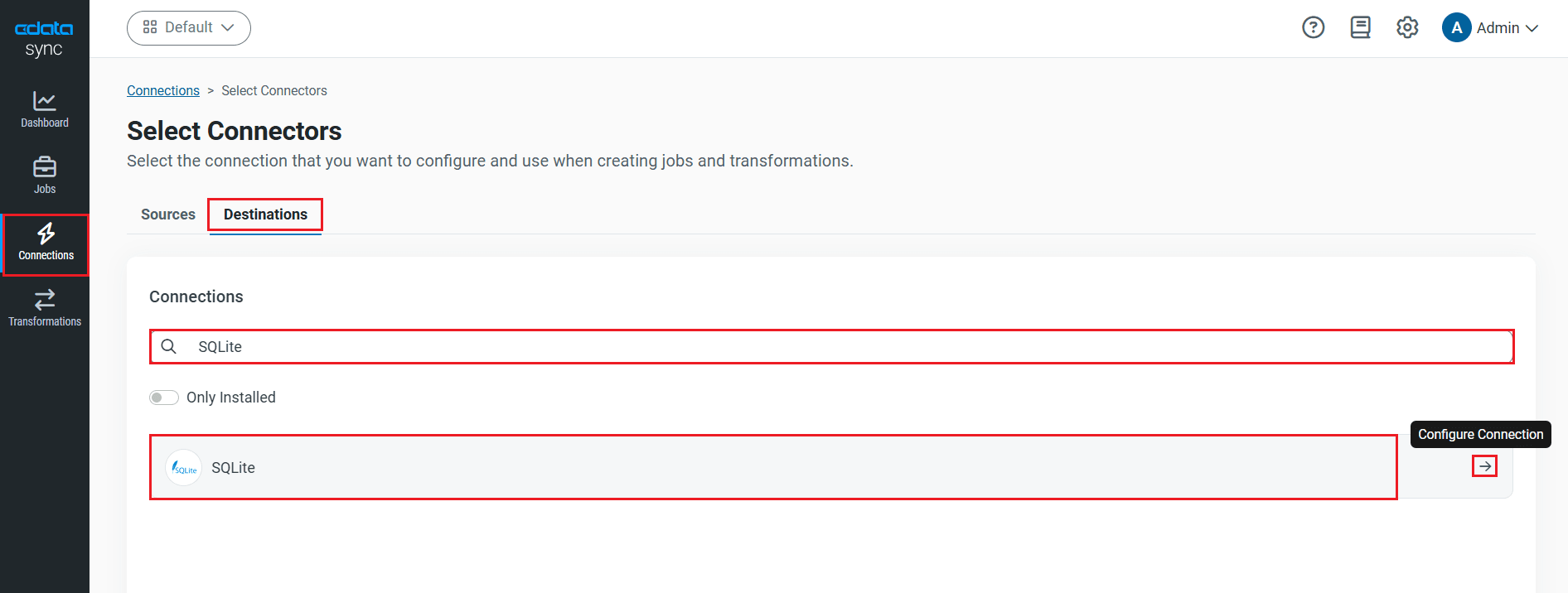
- 必要な接続プロパティを入力します。SQLite データベースにRedshift をレプリケートするためにDataSource ボックスにファイルパスを入力します。
- [接続のテスト]をクリックして、正しく接続できているかをテストします。
- [変更を保存]をクリックします。
Redshift 接続の設定
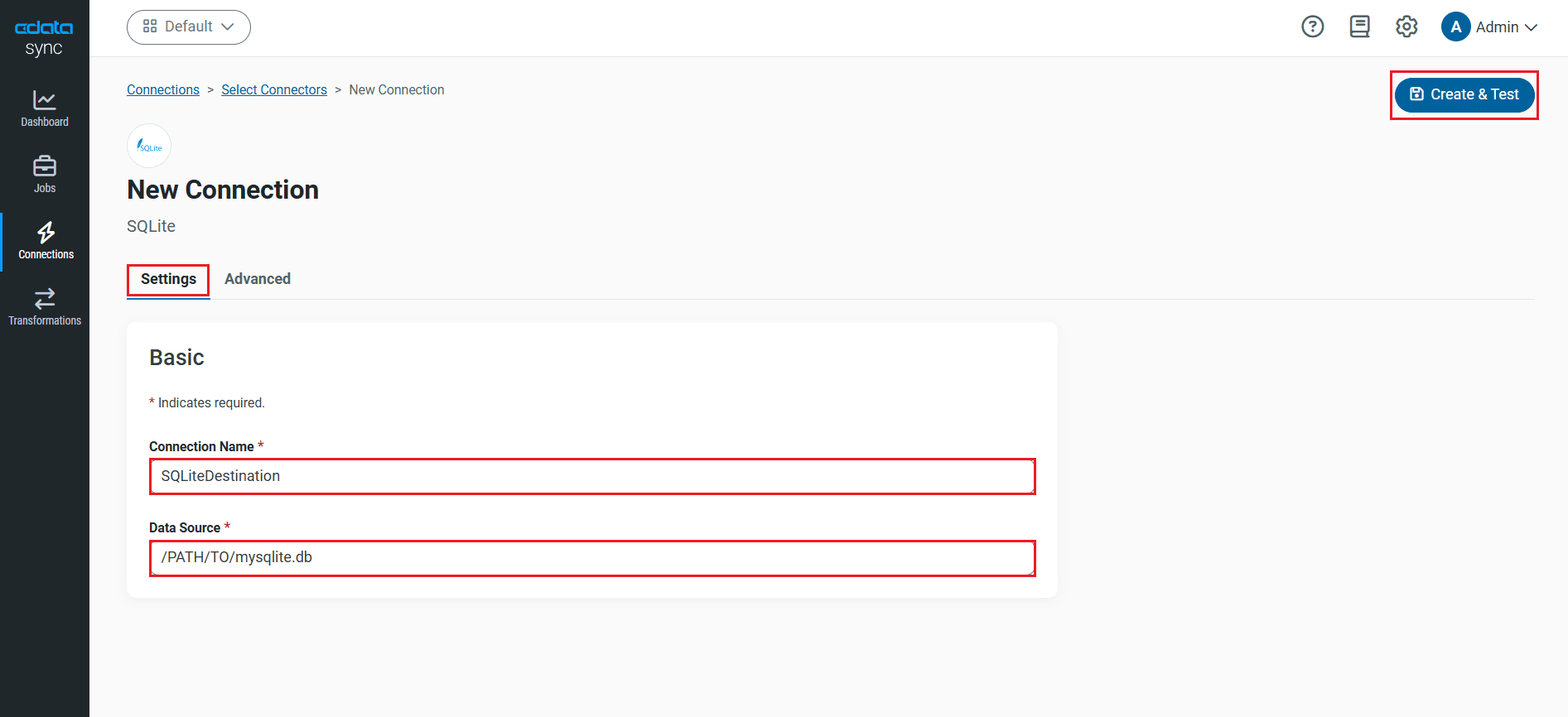
データソース側にRedshift を設定します。[接続]タブをクリックします。
- [同期先]タブをクリックします。
- Redshift アイコンをデータソースとして選択します。プリインストールされたソースにRedshift がない場合には、追加データソースとしてダウンロードします。
- 接続プロパティに入力をします。
Amazon Redshift への接続
それでは、早速Amazon Redshift に接続していきましょう。データに接続するには、以下の接続パラメータを指定します。
- Server:Amazon Redshift データベースをホスティングしているサーバーのホスト名またはIP アドレス
- Database:Amazon Redshift クラスター用に作成したデータベース
- Port(オプション):Amazon Redshift データベースをホスティングしているサーバーのポート。デフォルトは5439です
これらの値は、以下のステップでAWS マネージメントコンソールから取得できます。
- Amazon Redshift コンソールを開きます(http://console.aws.amazon.com/redshift)
- Clusters ページで、クラスター名をクリックしてください
- Configuration タブの"Cluster Database Properties" セクションからプロパティを取得します。接続プロパティの値は、ODBC URL で設定された値と同じになります
Amazon Redshiftへの認証
CData 製品では幅広い認証オプションに対応しています。標準認証情報からIAM クレデンシャル、ADFS、Ping Federate、Microsoft Entra ID(Azure AD)、Azure AD PKCE まで利用可能です。標準認証
ログイン資格情報を使用してAmazon Redshift に接続するには、以下のプロパティを設定してみましょう。- AuthScheme:Basic
- User:認証するユーザーのログイン情報
- Password:認証するユーザーのパスワード
その他の認証方法については、ヘルプドキュメントをご確認ください。

- [接続のテスト]をクリックして、正しく接続できているかをテストします。
- [変更を保存]をクリックします。
レプリケーションを実行するクエリの設定
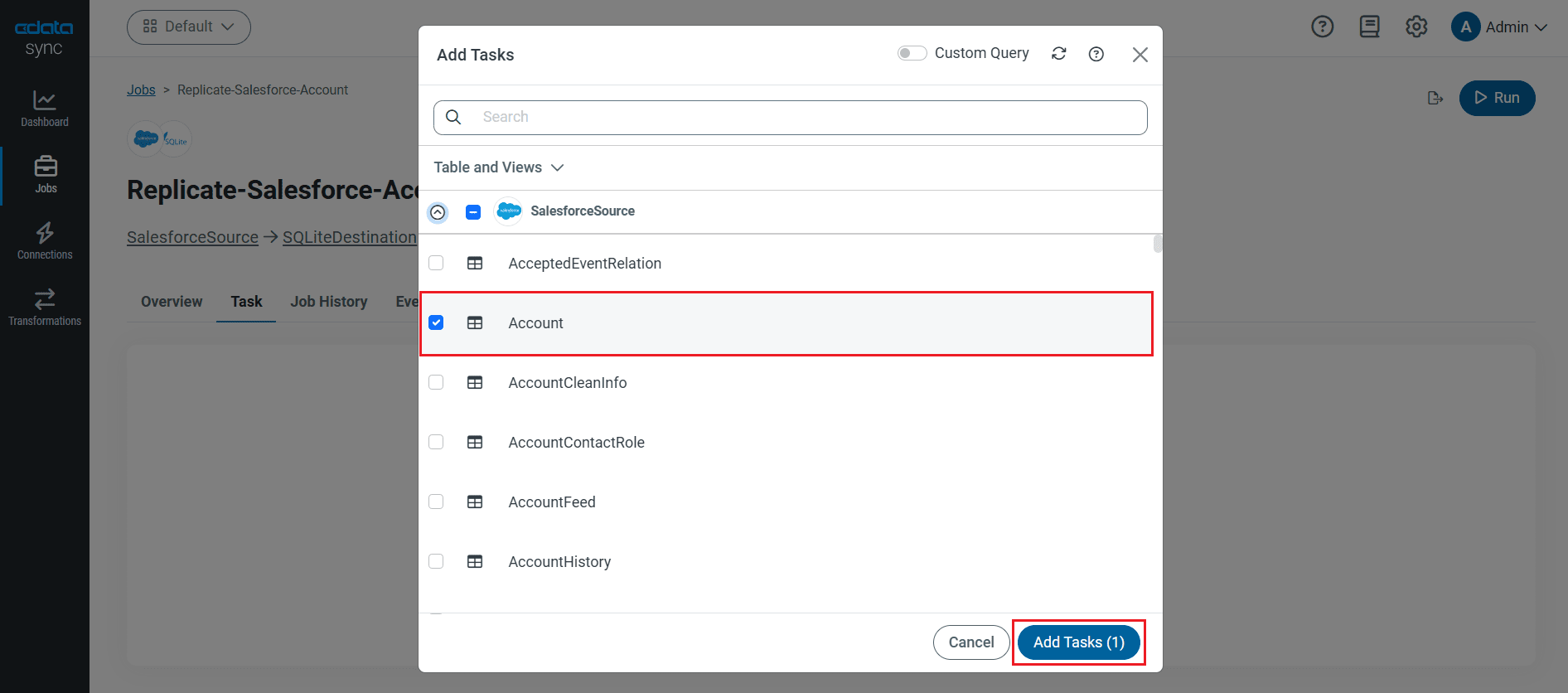
CData Sync はレプリケーションをコントロールするSQL クエリを簡単なGUI 操作で設定できます。レプリケーションジョブ設定には、[ジョブ]タブに進み、[ジョブを追加]ボタンをクリックします。 次にデータソースおよび同期先をそれぞれドロップダウンから選択します。
テーブル全体をレプリケーションする
テーブル全体をレプリケーションするには、[テーブル]セクションで[テーブルを追加]をクリックします。表示されたテーブルリストからレプリケーションするテーブルをチェックします。
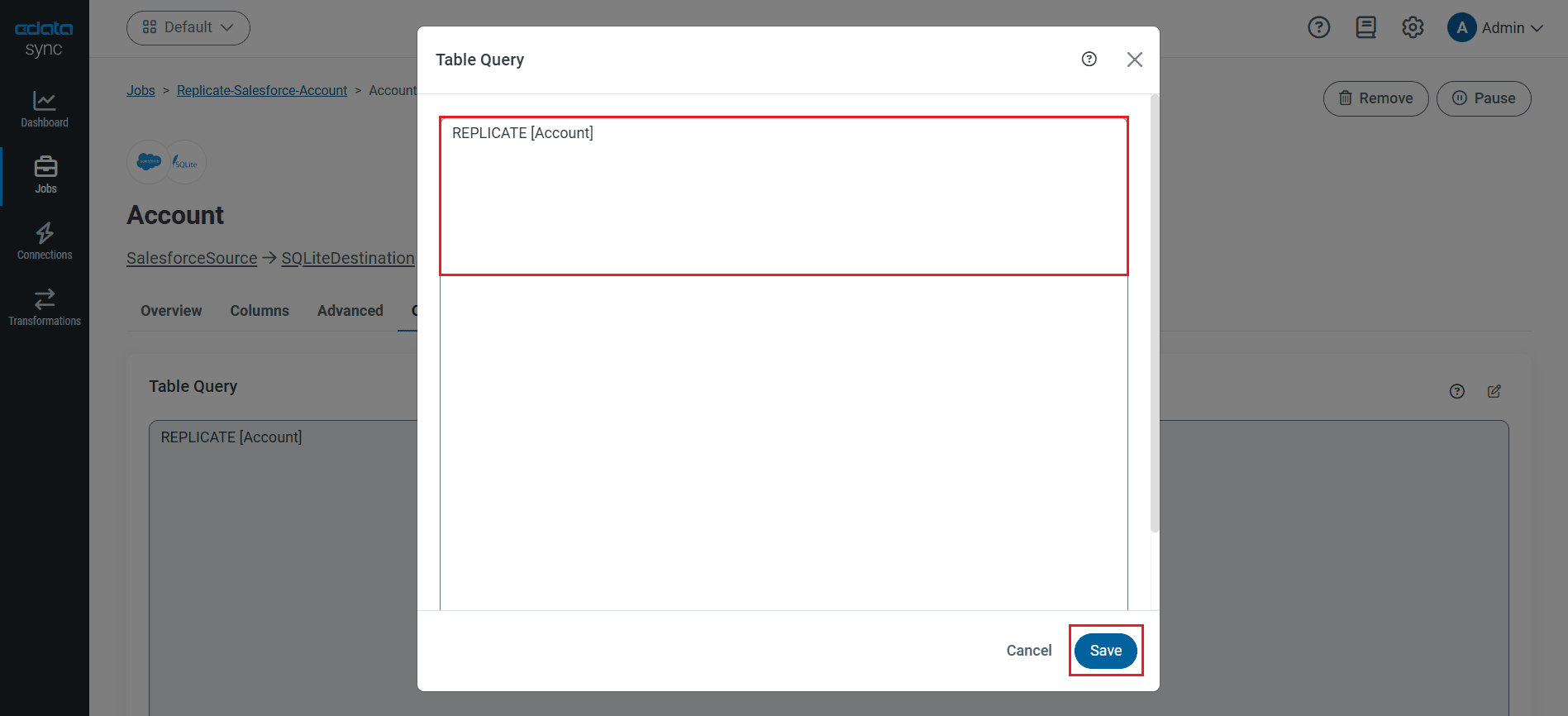
テーブルをカスタマイズしてレプリケーションする
SQL クエリを使って、レプリケーションをカスタマイズすることができます。REPLICATE ステートメントは、データベースにテーブルをキャッシュして、保持するハイレベルなコマンドです。Redshift API でサポートされているSELECT クエリを使うことができます。レプリケーションのカスタマイズには、[カスタムクエリを追加]をクリックして、カスタムクエリステートメントを定義します。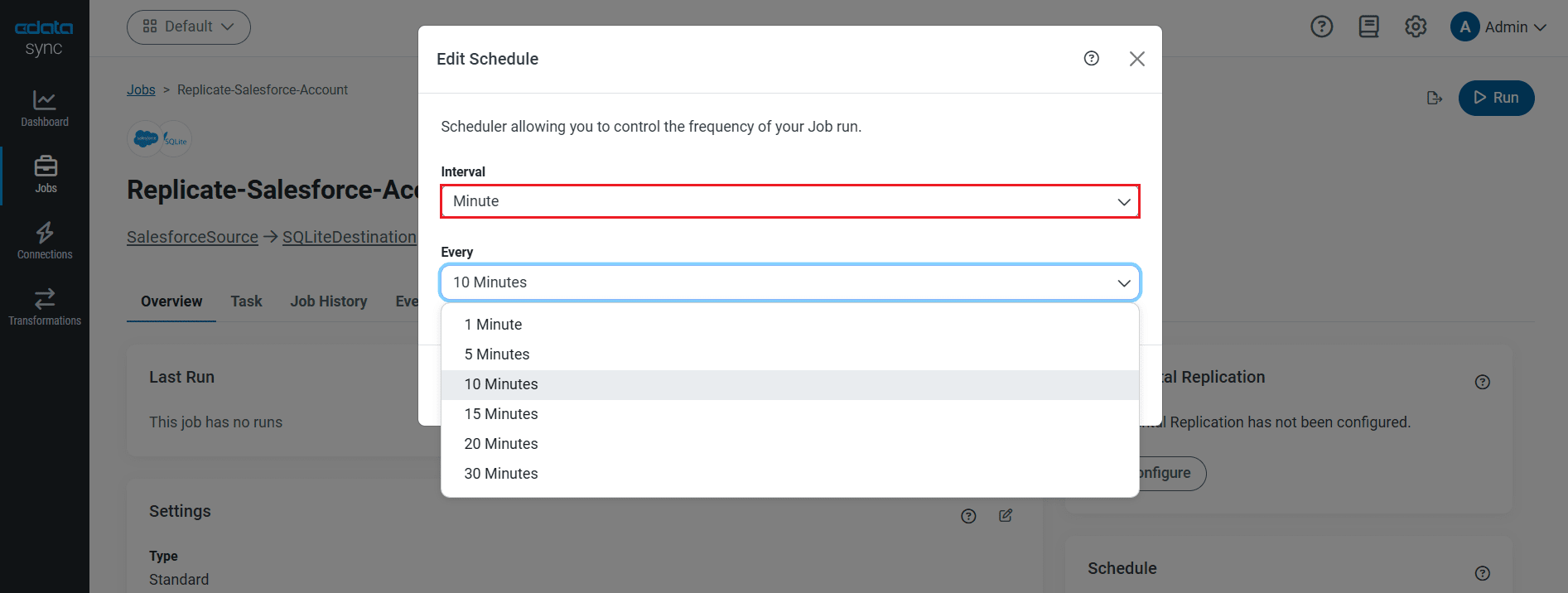
次のステートメントは、Redshift のテーブルのアップデートを差分更新でキャッシュします:
REPLICATE Orders;
特定のデータベースを更新するために、レプリケーションクエリを含むファイルを指定することもできます。レプリケーションクエリをセミコロンで区切ります。複数のRedshift アカウントを同じデータベースに同期しようとする際には、以下のオプションが便利です:
-
REPLICATE SELECT ステートメントで別のprefix を使う:
REPLICATE PROD_Orders SELECT * FROM Orders;
-
別の方法では、別のスキーマを使う:
REPLICATE PROD.Orders SELECT * FROM Orders;
レプリケーションのスケジュール起動設定
[スケジュール]セクションでは、レプリケーションジョブの自動起動スケジュール設定が可能です。反復同期間隔は、15分おきから毎月1回までの間で設定が可能です。
レプリケーションジョブを設定したら、[変更を保存]ボタンを押して保存します。Redshift のオンプレミス、クラウドなどのデータベースへのレプリケーションジョブは一つではなく複数を作成することが可能です。