





データ統合ツールQlik Replicate を使ってRedshift のデータをMySQL にレプリケートする方法

Qlik Replicate はBI ツールのQlik Sense で有名な、Qlik 社が提供するデータ分析基盤のためのデータパイプライン・データ統合ツールです。主要なプラットフォームに多く対応しているのが特徴で、AWS・GCP・Azure・Oracle・Snowflake などのDWH に各種データを取り込むことが可能です。
Qlik Replicate ではODBC インターフェースが用意されているので、CData ODBC Driver for Redshift と組み合わせることで、各種クラウドサービスのAPI にアクセスすることができるようになります。本記事では、CData ODBC ドライバを使ってQlik Replicate からRedshift のデータをMySQL にレプリケートする方法をご紹介します。
CData ODBC ドライバとは?
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
- Redshift をはじめとする、CRM、MA、会計ツールなど多様なカテゴリの270種類以上のSaaS / オンプレミスデータソースに対応
- 多様なアプリケーション、ツールにRedshift のデータを連携
- ノーコードでの手軽な接続設定
- 標準 SQL での柔軟なデータ読み込み・書き込み
CData ODBC ドライバでは、1.データソースとしてRedshift の接続を設定、2.Qlik Replicate 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData ODBC ドライバのインストールとRedshift への接続設定
まずは、本記事右側のサイドバーからRedshift ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
インストール後、ODBC DSN(データソース名)で接続プロパティを設定します。Microsoft ODBC Data Source Administrator を使用して、ODBC DSN を作成および設定できます。
Amazon Redshift への接続
それでは、早速Amazon Redshift に接続していきましょう。データに接続するには、以下の接続パラメータを指定します。
- Server:Amazon Redshift データベースをホスティングしているサーバーのホスト名またはIP アドレス
- Database:Amazon Redshift クラスター用に作成したデータベース
- Port(オプション):Amazon Redshift データベースをホスティングしているサーバーのポート。デフォルトは5439です
これらの値は、以下のステップでAWS マネージメントコンソールから取得できます。
- Amazon Redshift コンソールを開きます(http://console.aws.amazon.com/redshift)
- Clusters ページで、クラスター名をクリックしてください
- Configuration タブの"Cluster Database Properties" セクションからプロパティを取得します。接続プロパティの値は、ODBC URL で設定された値と同じになります
Amazon Redshiftへの認証
CData 製品では幅広い認証オプションに対応しています。標準認証情報からIAM クレデンシャル、ADFS、Ping Federate、Microsoft Entra ID(Azure AD)、Azure AD PKCE まで利用可能です。標準認証
ログイン資格情報を使用してAmazon Redshift に接続するには、以下のプロパティを設定してみましょう。- AuthScheme:Basic
- User:認証するユーザーのログイン情報
- Password:認証するユーザーのパスワード
その他の認証方法については、ヘルプドキュメントをご確認ください。
Qlik Replicate にODBC データソースを追加
CData ODBC ドライバの設定が完了したら、Qlik Replicate を立ち上げてレプリケーション構成を進めていきましょう。Qlik Replicate ではタスクという単位でレプリケーション処理を構成していきますが、まずタスクで利用するデータソースとレプリケーション先のコネクション情報を登録する必要があるので、この設定を行います。
- Qlik Replicate の管理画面に移動したら、 「Manage Endpoint Connections…」をクリックします。
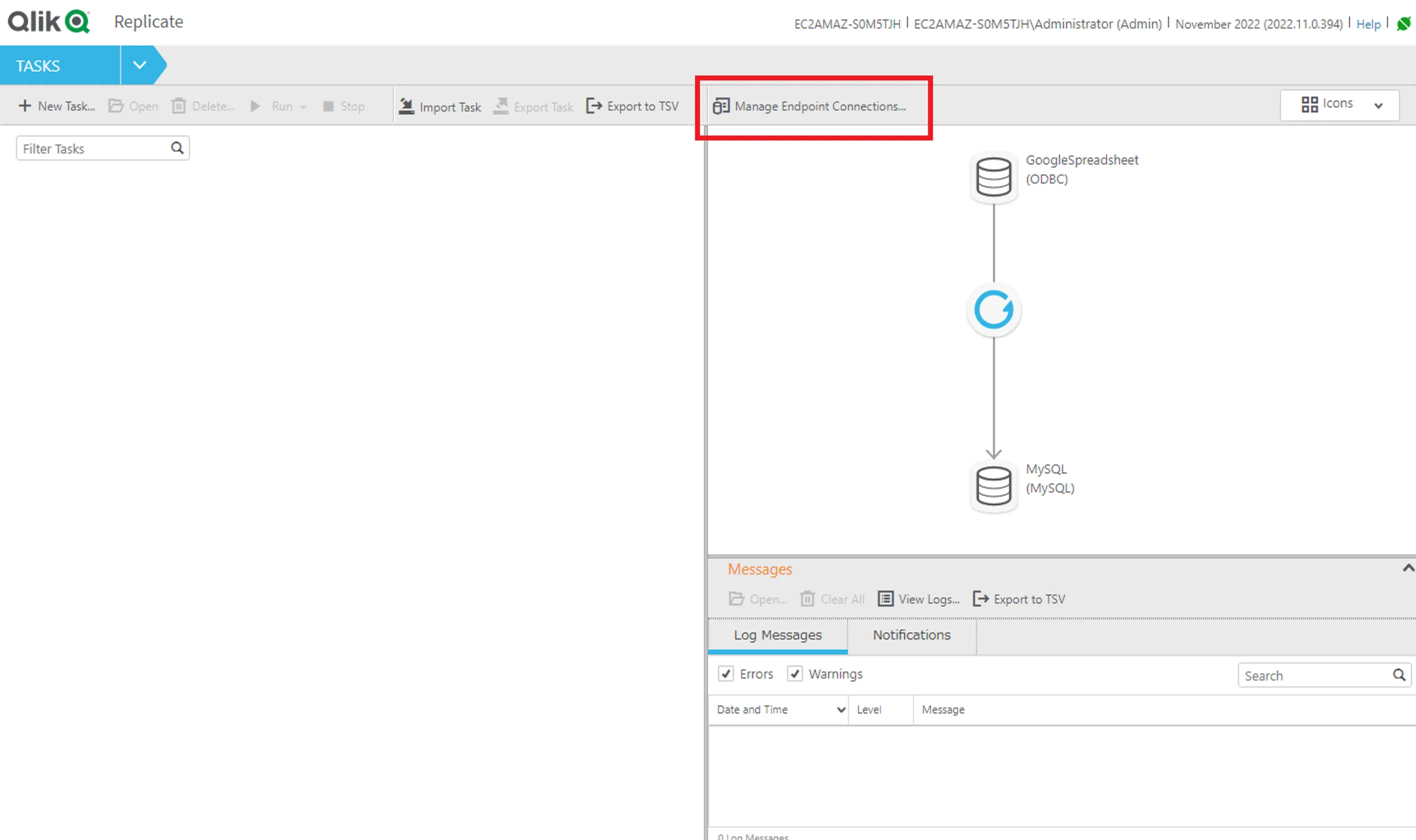
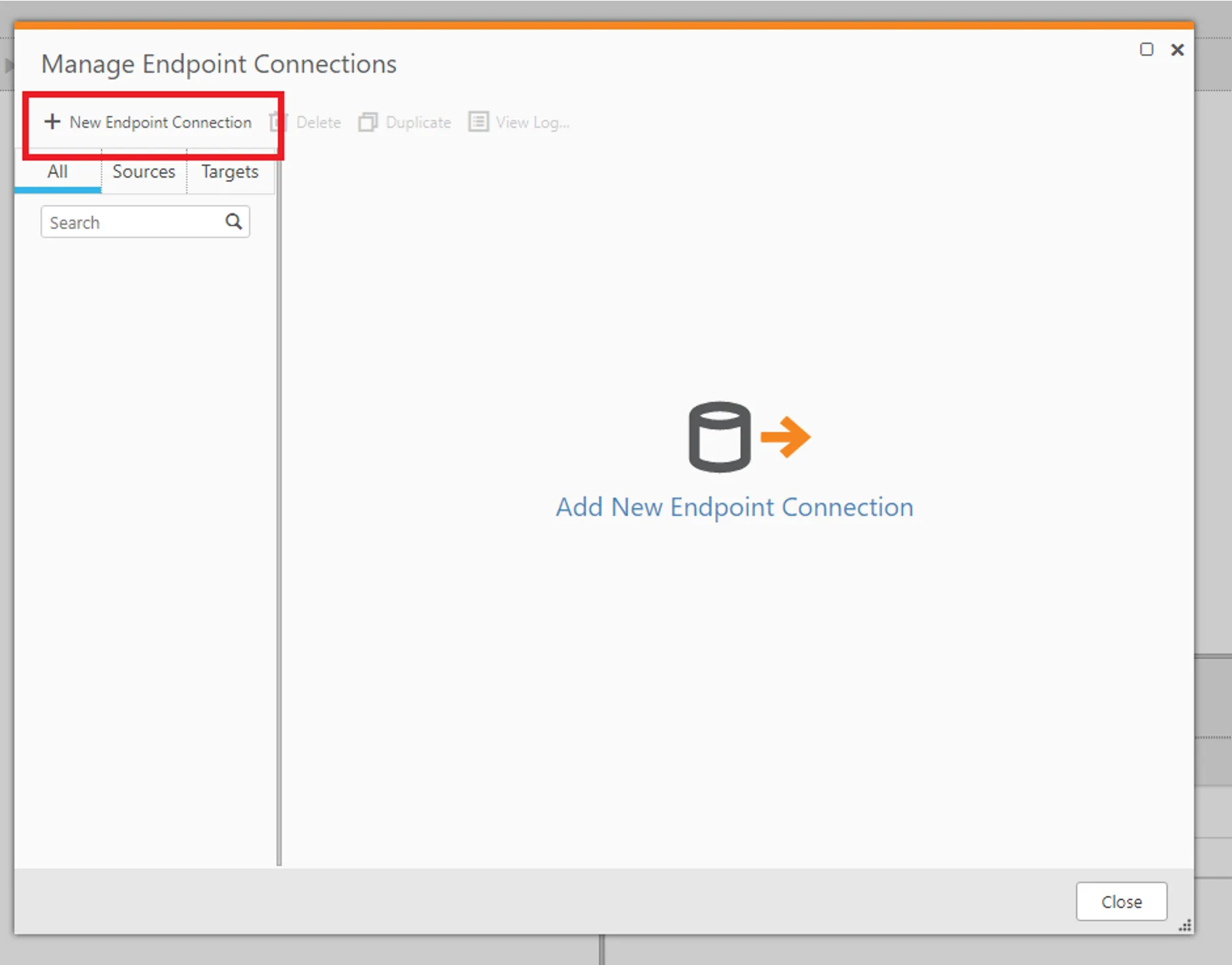
- その後表示される画面で、「+New Endpoint Connection」をクリック。この画面からデータソースとレプリケーション先(ターゲット)のコネクションを構成していきます。
- まずはデータソースとなるRedshift へのコネクションを構成します。前述の通り、Redshift への連携はCData ODBC ドライバを経由して行うため、「Role:Source」「Type:ODBC」でコネクションを構成します。

- そして、事前に構成しておいたRedshift のDSN を指定します。任意のName を指定したあと、Test Connection がパスできれば設定完了です。
MySQL Target 接続を追加
続いて、レプリケーション先となるMySQL へのコネクションも追加します。
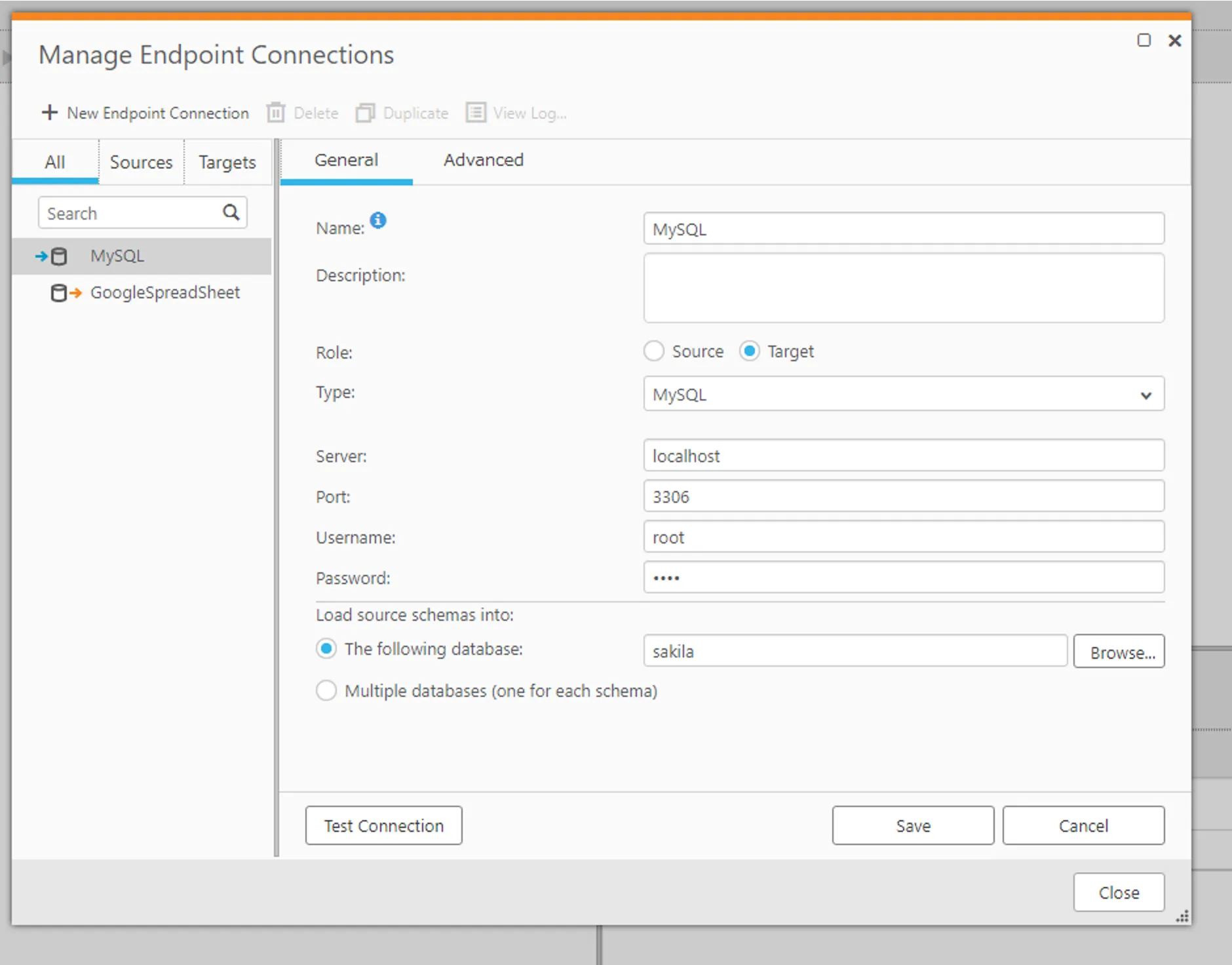
- 先程と同じように「+New Endpoint Connection」をクリックします。
- 「Role: Target」「Type: MySQL」を指定して、Server アドレスやUserName、Password などMySQL 接続に必要な接続情報をそれぞれ指定し、保存します。
Task の構成
コネクションの作成が完了したら、実際のレプリケーション処理であるTask の作成を進めていきましょう。
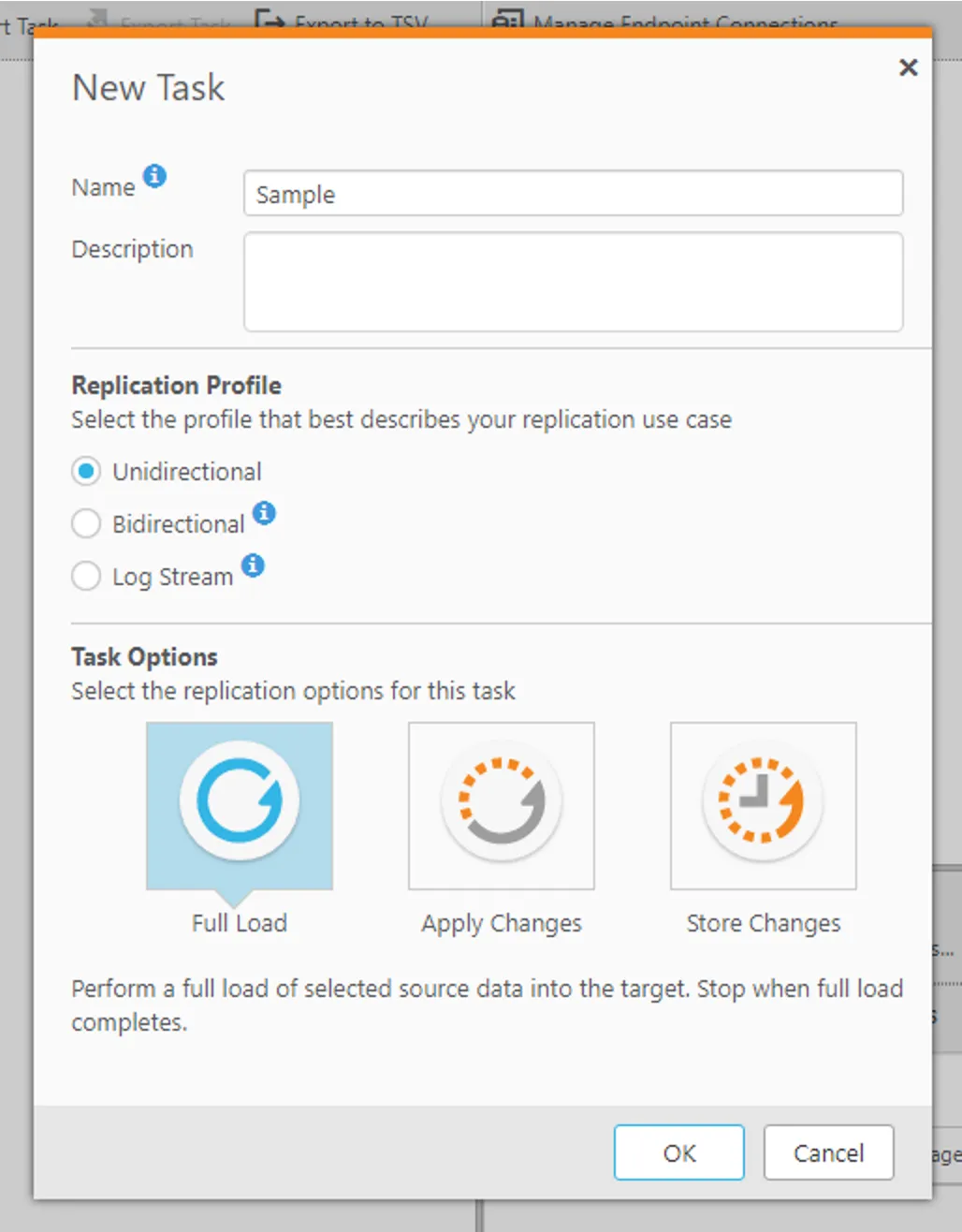
- 「+New Task」をクリックし、任意の名称でTask を作成します。Replication Profileは「Unidirectional:単方向」でTask Optionsは「Full Load」を指定します。
- タスク作成後の画面で、データソースには先程作成したRedshift のコネクションを、ターゲットにはMySQL のコネクションを、ドラッグドロップでそれぞれ指定します。
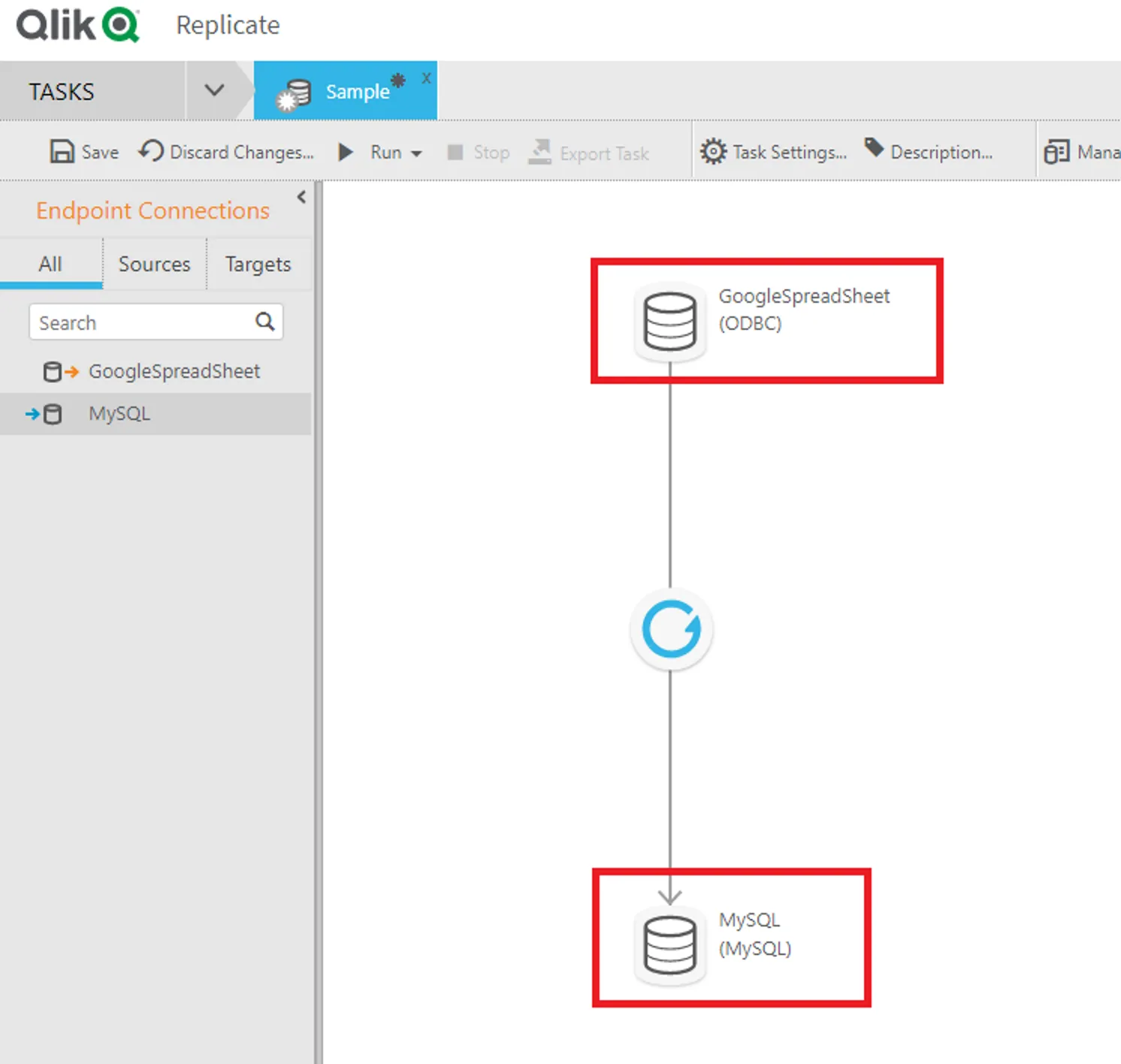
レプリケーション対象のテーブルを選択
データソースとターゲットを決めたら、レプリケーション対象のテーブルを指定しましょう。
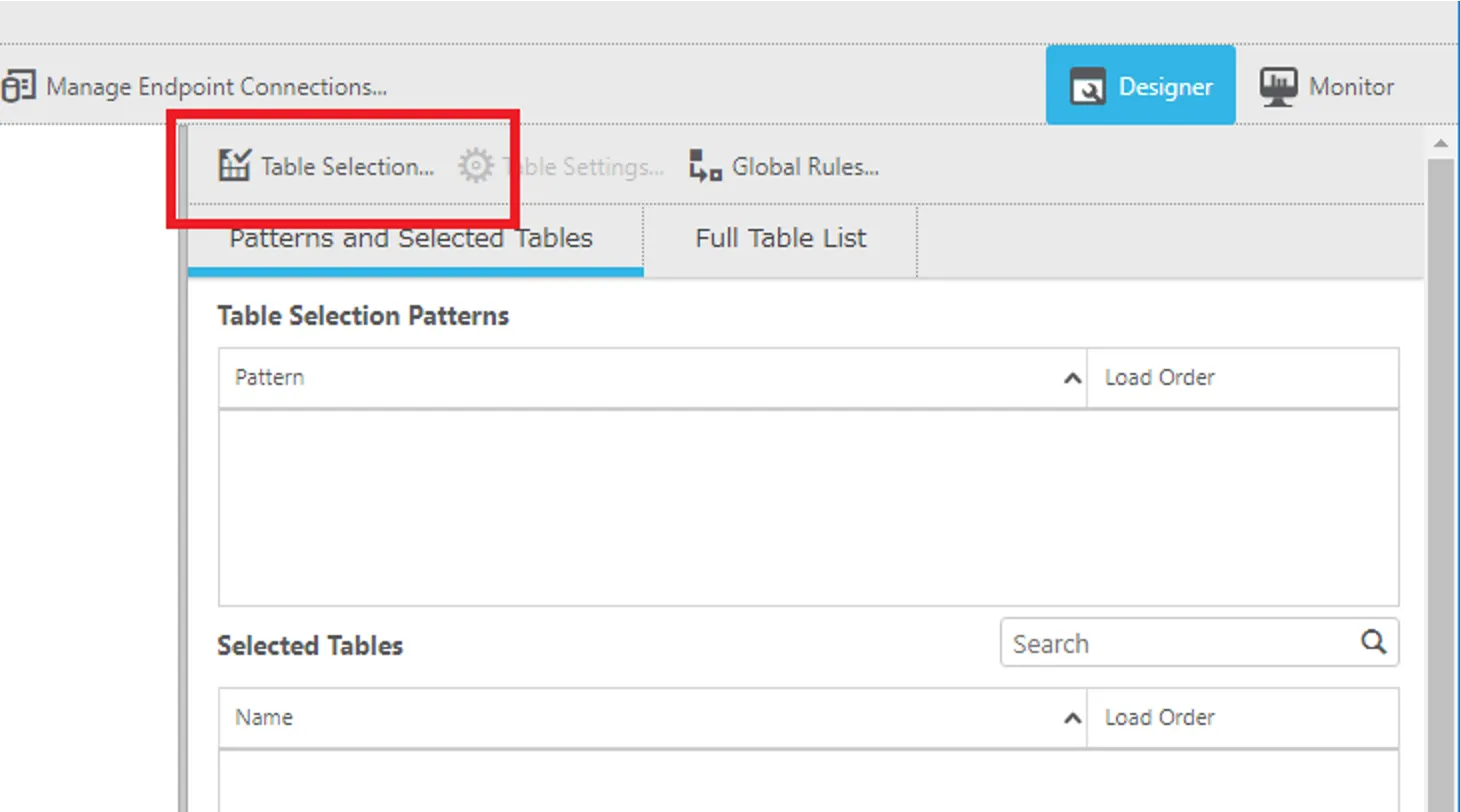
- 「Table Selection」をクリックします。
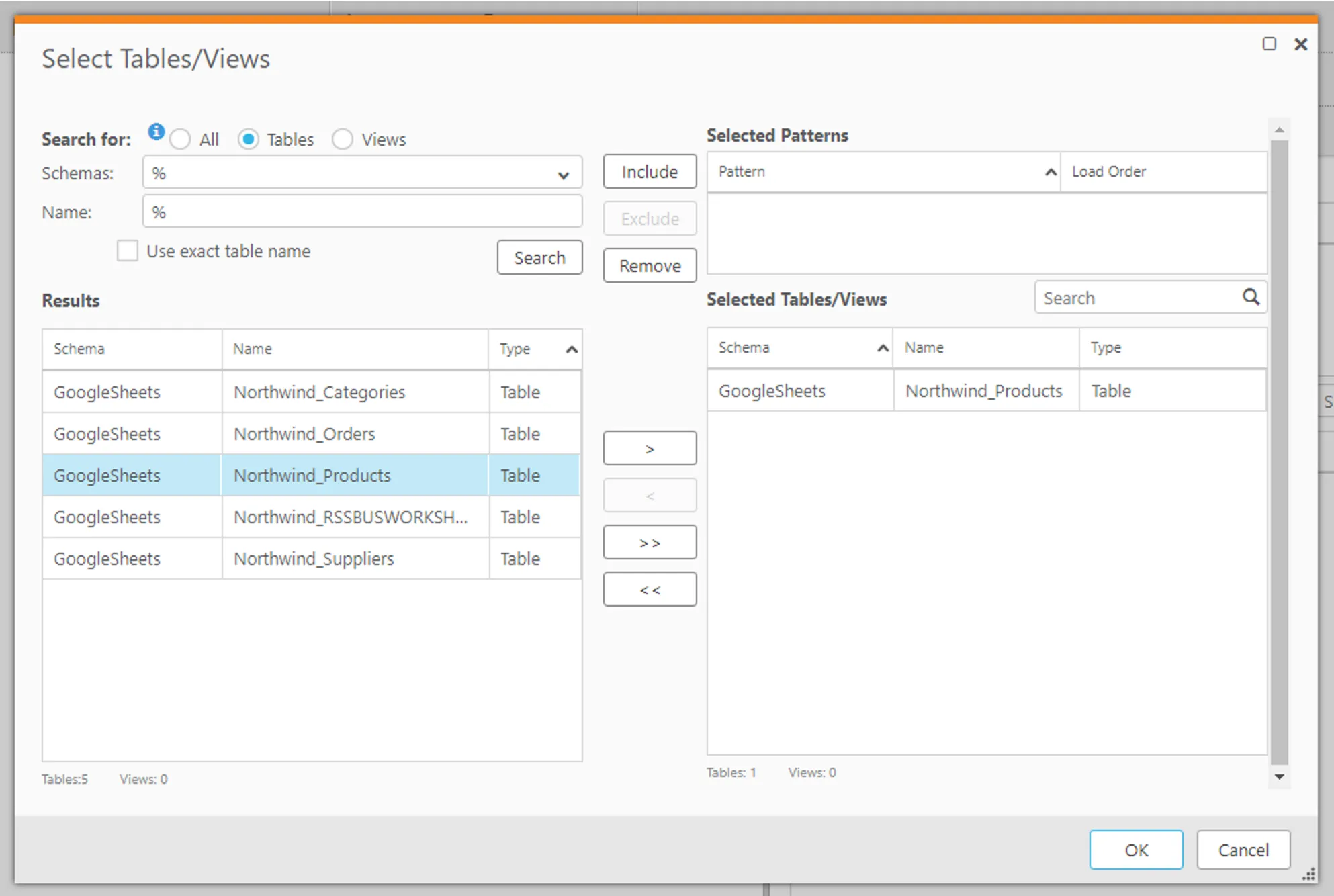
- 「Search」をクリックして、対象となるテーブルを検索します。以下のようにRedshift のテーブル一覧が表示されるので、任意のテーブルを選択していきます。
- これで以下のように選択されればOK です。ちなみにデフォルトではテーブルの全レコード・全カラムをレプリケーションしますが、Global Rules から細かな条件や項目の設定がチューニング可能です。

作成したTask を実行
それでは作成したTask を実際に実行してみましょう。
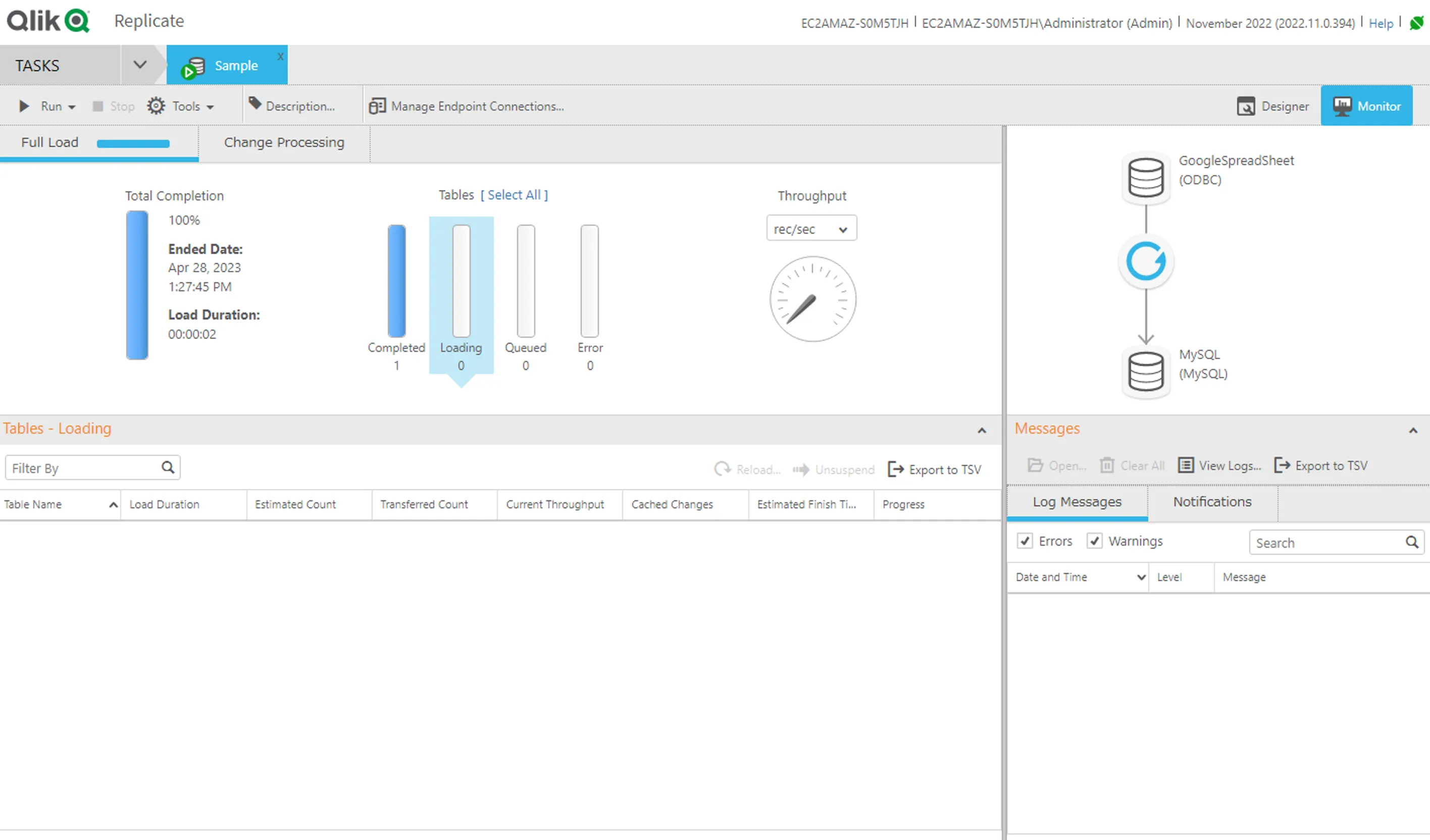
- 「Run」をクリックすることで、レプリケーションを開始できます。
- レプリケーションが進むとMonitor 画面に遷移し、レプリケーション結果を確認できます。Completed が表示されればOKです。
- 実際にMySQL のテーブルを確認してみると、以下のようにテーブルが自動生成され、データが正常に複製されていました。
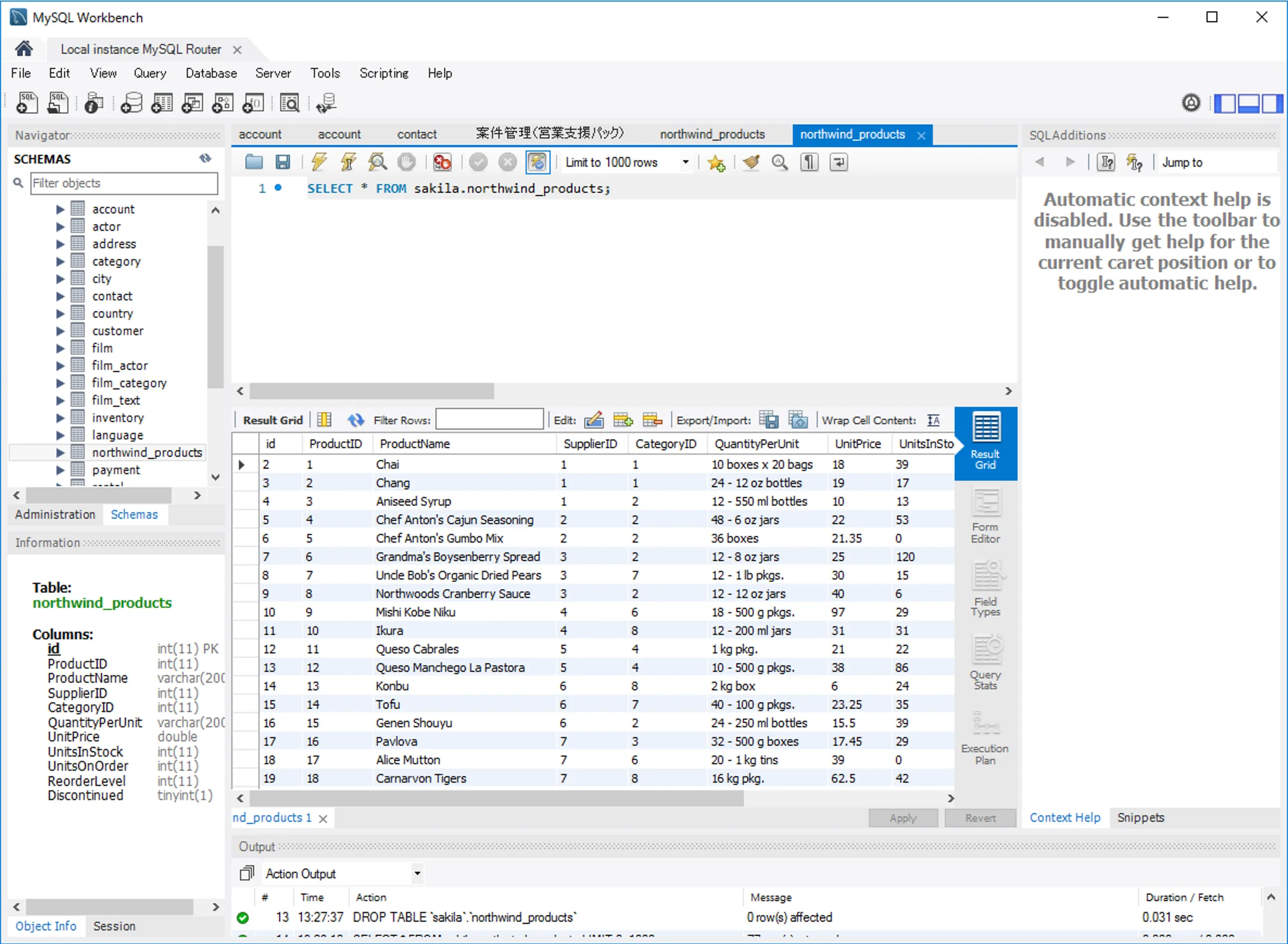
おわりに
このようにCData ODBC ドライバを利用することで、各種クラウドサービスをQlik Replicate の接続先として利用できるようになります。 CData ではRedshift 以外にも270種類以上のデータソース向けにODBC Driver を提供しています。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
日本のユーザー向けにCData Sync は、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。
はじめる準備はできましたか?
Amazon Redshift ODBC Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード詳細:
Amazon Redshift ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからAmazon Redshift データへの接続を実現するパワフルなツールです。
標準ODBC Driver インターフェースを通じて、Amazon Redshift データを読み、書き、更新。