





Exploratory でRedshift のデータを連携する方法

CData ODBC Driver for Redshift は、ODBC 経由でリアルタイムRedshift データに標準SQL での利用を可能にします。
ここでは、汎用ODBC データプロバイダーとしてRedshift に接続し、データアナリティクスツールのExploratory (https://exploratory.io/) からRedshift のデータを連携利用する手順を説明します。
Exploratory は、多くのRDB やRedshift、BigQuery などのクラウドデータストアに対応していますが、SaaS データを分析したい場合にはCData ODBC ドライバを使うことで、API コーディング不要でデータを活用できます。今回はRedshift を例に説明します。
CData ODBC ドライバとは?
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
- Redshift をはじめとする、CRM、MA、会計ツールなど多様なカテゴリの270種類以上のSaaS / オンプレミスデータソースに対応
- 多様なアプリケーション、ツールにRedshift のデータを連携
- ノーコードでの手軽な接続設定
- 標準 SQL での柔軟なデータ読み込み・書き込み
CData ODBC ドライバでは、1.データソースとしてRedshift の接続を設定、2.Exploratory 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData ODBC ドライバのインストールとRedshift への接続設定
まずは、本記事右側のサイドバーからRedshift ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
次にマシンにRedshift のデータ に接続するODBC DSN を設定します。Exploratory からはそのODBC DSN を参照する形になります。ODBC DSN 設定の詳細については、ドキュメントを参照してください。
Amazon Redshift への接続
それでは、早速Amazon Redshift に接続していきましょう。データに接続するには、以下の接続パラメータを指定します。
- Server:Amazon Redshift データベースをホスティングしているサーバーのホスト名またはIP アドレス
- Database:Amazon Redshift クラスター用に作成したデータベース
- Port(オプション):Amazon Redshift データベースをホスティングしているサーバーのポート。デフォルトは5439です
これらの値は、以下のステップでAWS マネージメントコンソールから取得できます。
- Amazon Redshift コンソールを開きます(http://console.aws.amazon.com/redshift)
- Clusters ページで、クラスター名をクリックしてください
- Configuration タブの"Cluster Database Properties" セクションからプロパティを取得します。接続プロパティの値は、ODBC URL で設定された値と同じになります
Amazon Redshiftへの認証
CData 製品では幅広い認証オプションに対応しています。標準認証情報からIAM クレデンシャル、ADFS、Ping Federate、Microsoft Entra ID(Azure AD)、Azure AD PKCE まで利用可能です。標準認証
ログイン資格情報を使用してAmazon Redshift に接続するには、以下のプロパティを設定してみましょう。- AuthScheme:Basic
- User:認証するユーザーのログイン情報
- Password:認証するユーザーのパスワード
その他の認証方法については、ヘルプドキュメントをご確認ください。
Exploratory 上でRedshift のデータをセット
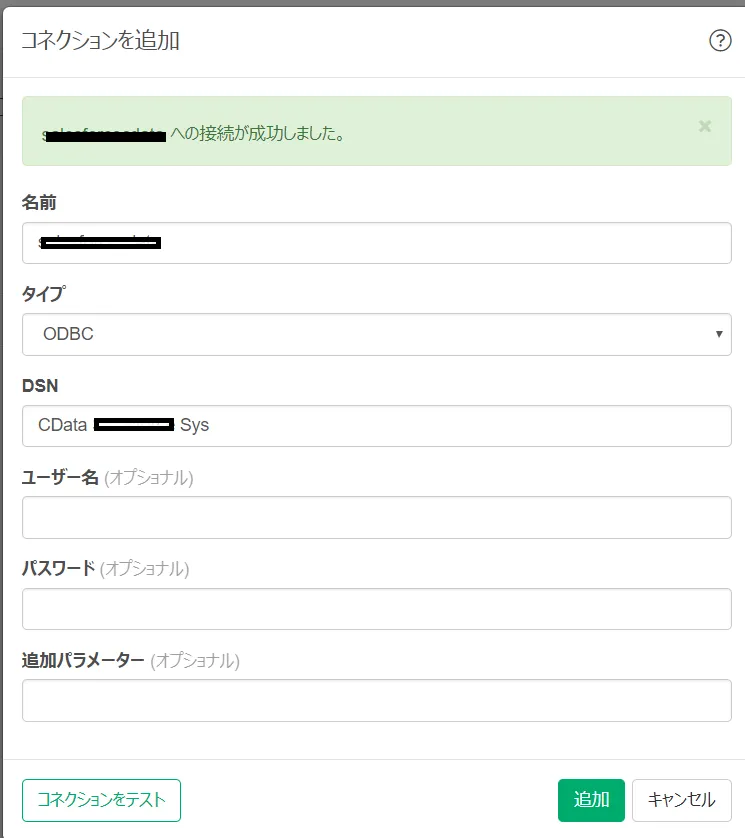
- Exploratory で[コネクション]をクリックして新しいコネクションを作成します。
- [追加]→[ODBC]の順にクリック。
- コネクション追加画面で先ほど設定したRedshift ODBC のDSN を設定します。
名前:任意
タイプ:ODBC
DSN:上の設定したDSN 名(CData Redshift Sys) - コネクションテストを下の地、[追加]を押して接続を確定させます。
Exploratory でRedshift のデータをクエリし、データフレームとして保存
さあ、Exploratory からRedshift のデータを扱ってみましょう。
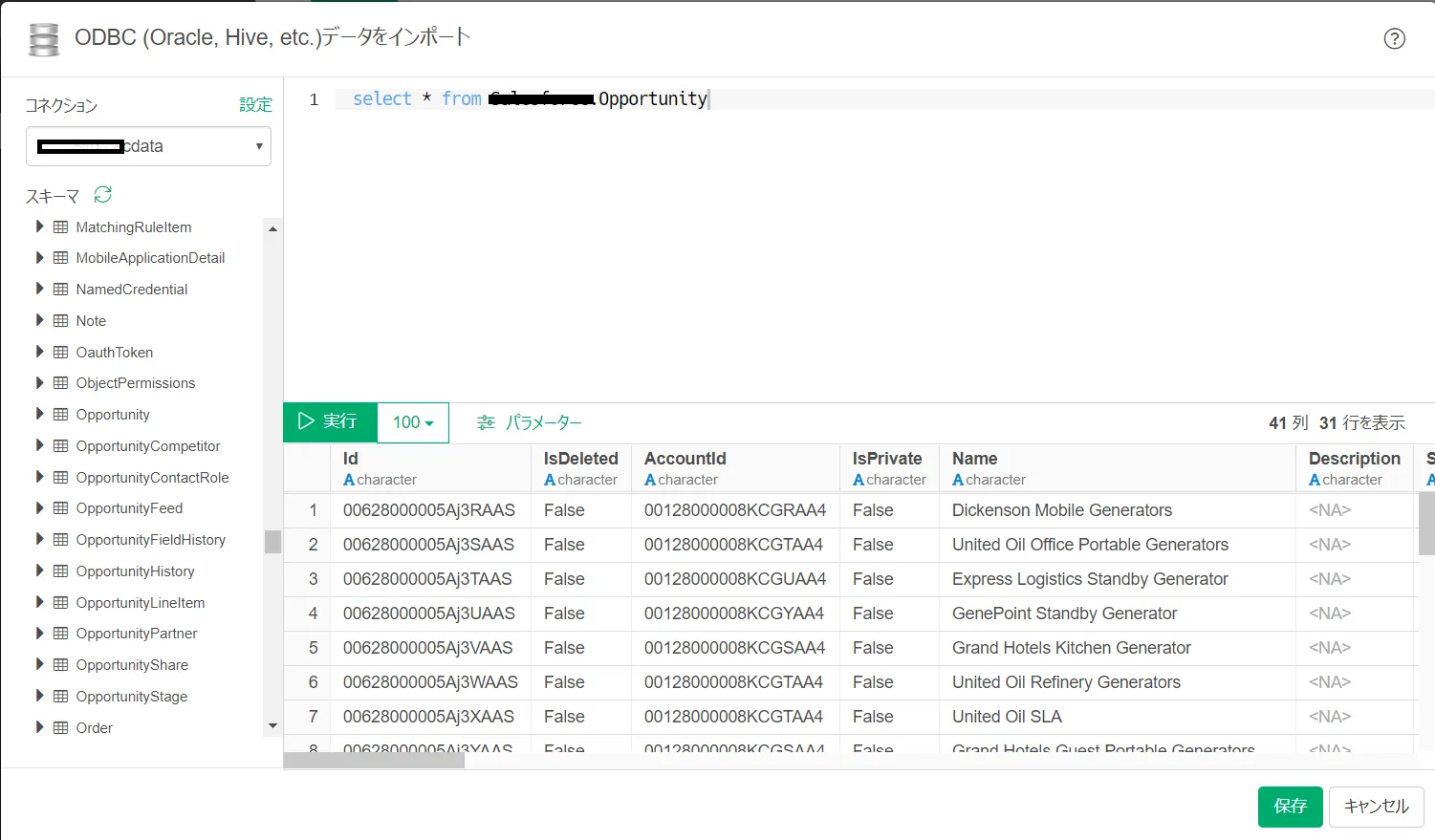
- Exploratory でプロジェクトを[新規作成]します。
- [データフレーム]の[+]印をクリックし、[データベースデータ]を選択します。
- データベースは[ODBC]をクリック。
- [コネクション]で先ほど設定したRedshift のコネクションを選択します。
- RDB ソースの感覚でSELECT クエリでRedshift のデータをクエリします。標準SQL でフィルタリング、ソート、JOIN も可能です。
- データセットをデータフレームとして保存します。


Exploratory でのRedshift のデータの分析
データフレームになったデータは通常のRDB データソースと同じようにExploratory で利用可能です。
おわりに
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。
はじめる準備はできましたか?
Amazon Redshift ODBC Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード詳細:
Amazon Redshift ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからAmazon Redshift データへの接続を実現するパワフルなツールです。
標準ODBC Driver インターフェースを通じて、Amazon Redshift データを読み、書き、更新。