





RapidMiner からRedshift のデータに連携

この記事では、CData JDBC Driver for Redshift をRapidMiner のプロセスと簡単に統合する方法を示します。この記事では、CData JDBC Driver for Redshift を使用してRedshift をRapidMiner のプロセスに転送します。
RapidMiner のRedshift にJDBC Data Source として接続する
以下のステップに従ってRedshift へのJDBC 接続を確認できます。
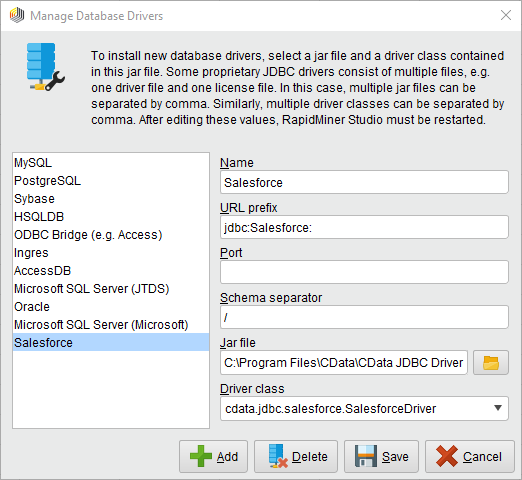
- Redshift 用の新しいデータベースドライバーを追加します。[Connections]->[Manage Database Drivers]とクリックします。
- 表示されるウィザードで[Add]ボタンをクリックし、接続に名前を入力します。
- JDBC URL のプレフィックスを入力します。
jdbc:redshift:
- インストールディレクトリのlib サブフォルダにあるcdata.jdbc.redshift.jar ファイルにパスを入力して下さい。
- ドライバークラスを入力します。
cdata.jdbc.redshift.RedshiftDriver
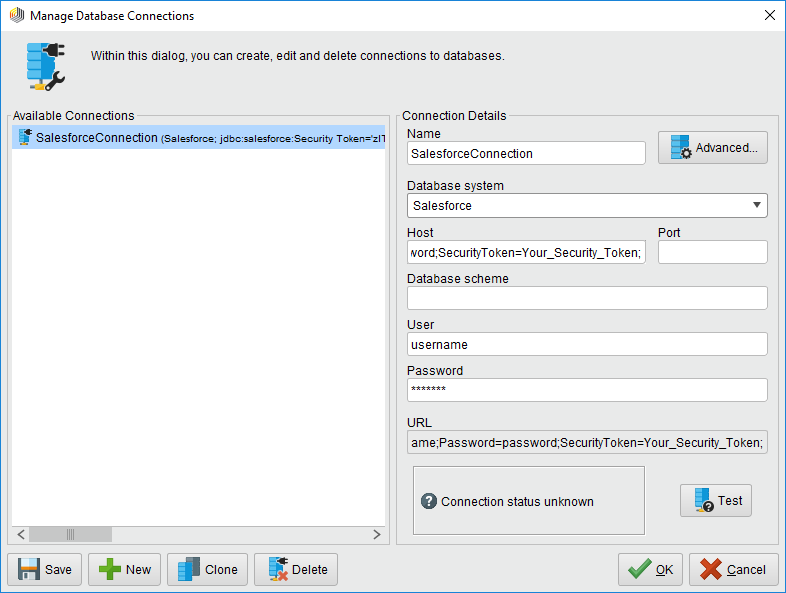
- 新しいRedshift 接続を作成します。[Connections]->[Manage Database Connections]とクリックします。
- 接続の名前を入力します。
- データベースシステムの場合は、以前構成したRedshift ドライバーを選択します。
- Host ボックスで接続文字列を入力します。
Amazon Redshift への接続
それでは、早速Amazon Redshift に接続していきましょう。データに接続するには、以下の接続パラメータを指定します。
- Server:Amazon Redshift データベースをホスティングしているサーバーのホスト名またはIP アドレス
- Database:Amazon Redshift クラスター用に作成したデータベース
- Port(オプション):Amazon Redshift データベースをホスティングしているサーバーのポート。デフォルトは5439です
これらの値は、以下のステップでAWS マネージメントコンソールから取得できます。
- Amazon Redshift コンソールを開きます(http://console.aws.amazon.com/redshift)
- Clusters ページで、クラスター名をクリックしてください
- Configuration タブの"Cluster Database Properties" セクションからプロパティを取得します。接続プロパティの値は、ODBC URL で設定された値と同じになります
Amazon Redshiftへの認証
CData 製品では幅広い認証オプションに対応しています。標準認証情報からIAM クレデンシャル、ADFS、Ping Federate、Microsoft Entra ID(Azure AD)、Azure AD PKCE まで利用可能です。標準認証
ログイン資格情報を使用してAmazon Redshift に接続するには、以下のプロパティを設定してみましょう。- AuthScheme:Basic
- User:認証するユーザーのログイン情報
- Password:認証するユーザーのパスワード
その他の認証方法については、ヘルプドキュメントをご確認ください。
ビルトイン接続文字列デザイナ
JDBC URL の構成については、Redshift JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.redshift.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。

以下は一般的な接続文字列です。
User=admin;Password=admin;Database=dev;Server=examplecluster.my.us-west-2.redshift.amazonaws.com;Port=5439;
- 必要であればユーザー名とパスワードを入力します。
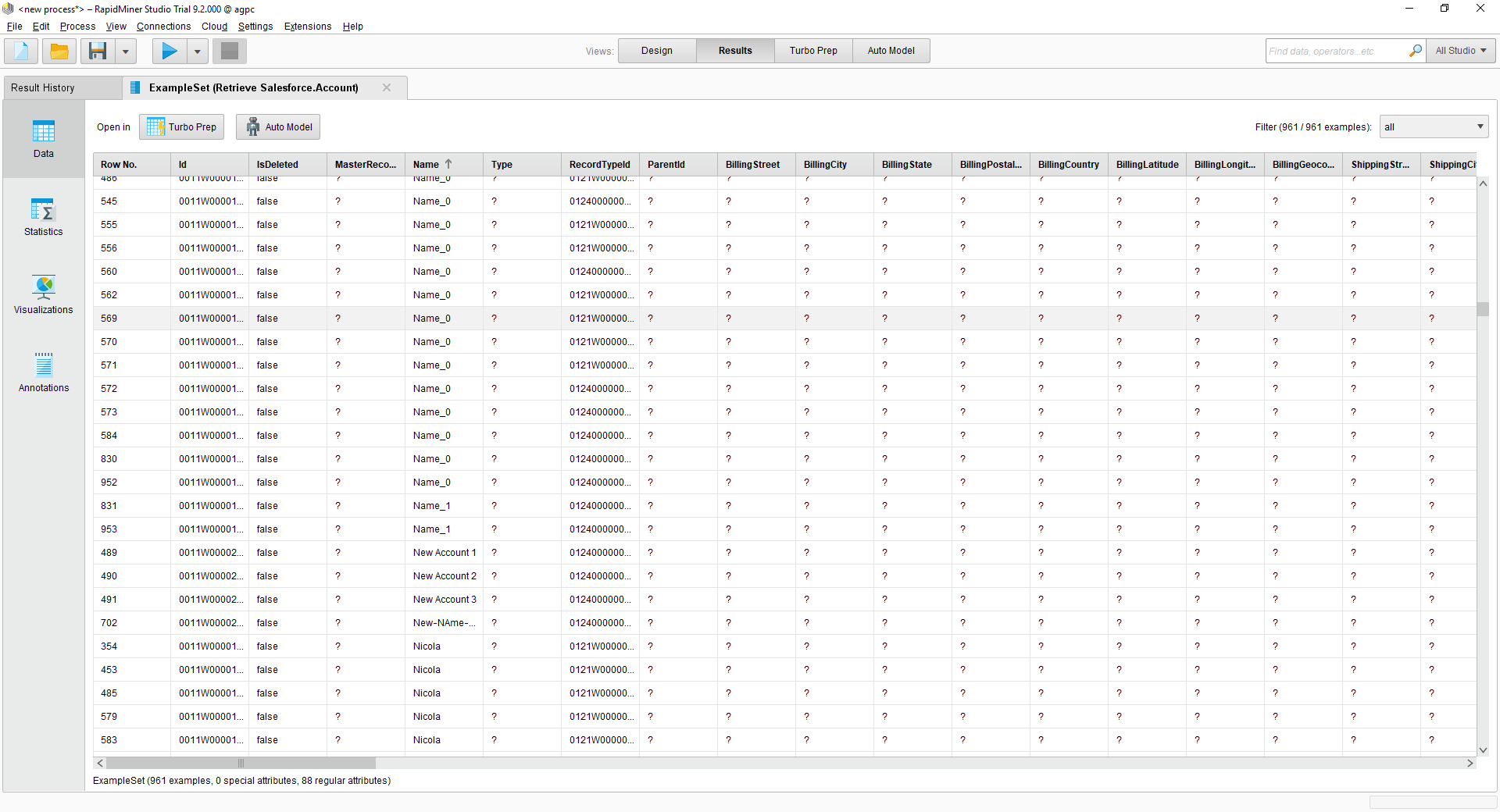
プロセス内の様々なRapidMiner オペレーターとのRedshift 接続を使用できます。Redshift を取得するには、[Operators]ビューから[Retrieve]をドラッグします。
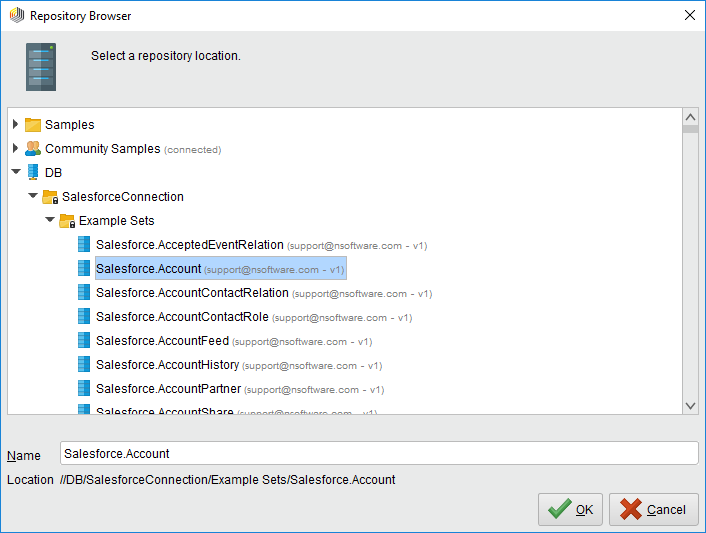 [Retrieve]オペレータを選択した状態で、[repository entry]の横にあるフォルダアイコンをクリックして[Parameters]ビューで取得するテーブルを定義できます。表示されるRepository ブラウザで接続ノードを展開し、目的のサンプルセットを選択できます。
[Retrieve]オペレータを選択した状態で、[repository entry]の横にあるフォルダアイコンをクリックして[Parameters]ビューで取得するテーブルを定義できます。表示されるRepository ブラウザで接続ノードを展開し、目的のサンプルセットを選択できます。
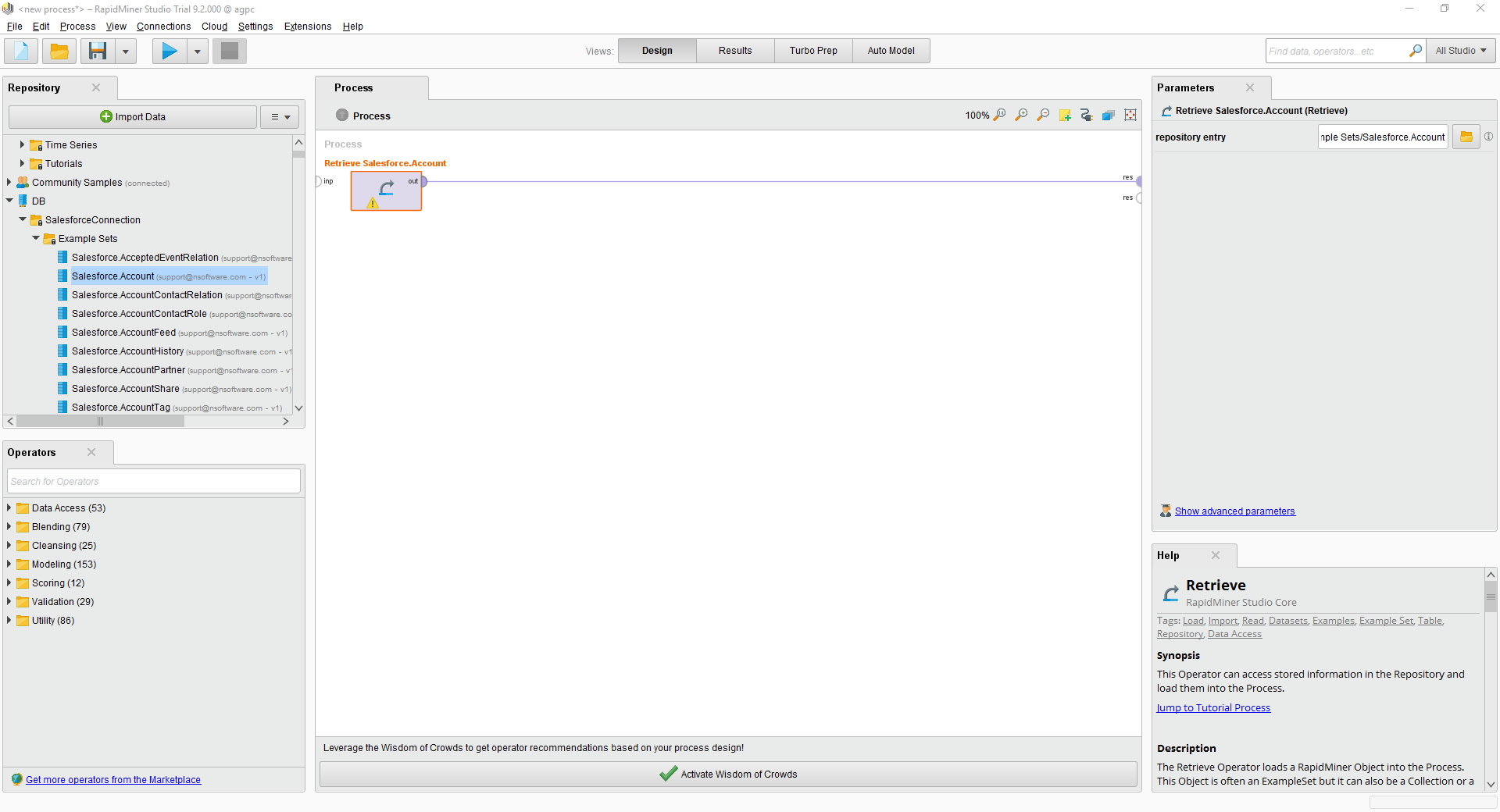
最後に、[Retrieve]プロセスから結果に出力をワイヤリングし、プロセスを実行してRedshift を確認します。
はじめる準備はできましたか?
Amazon Redshift Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード