





エンタープライズサーチのNeuron にKafka のデータを取り込んで検索利用

ブレインズテクノロジー社のNeuron は、先端OSS 技術(Apache Solr)を活用したエンタープライズサーチ(企業内検索エンジン)サービスです。Apache Solr は、エンタープライズサーチ機能をAPI として提供してくれますが、Neuron はApache Solr に企業ユーザーがデータを探索するためのシンプルかつ使いやすいユーザーインターフェースと管理画面・運用機能を提供してくれます。これによりエンドユーザーが簡単にエンタープライズサーチを利用することができます。管理画面では、ファイルやデータのクローリング設定がUI で行えるようになっています。この記事では、Neuron に備わっているJDBC インターフェース経由で、CData JDBC Driver for ApacheKafka を利用することでNeuron にKafka のデータを取り込んで検索で利用できるようにします。
Neuron にCData JDBC Driver for ApacheKafka データをロード
CData JDBC Driver for ApacheKafka のインストールと.jar ファイルの配置
- CData JDBC Driver for ApacheKafka をNeuron と同じマシンにインストールします。
-
以下のパスにJDBC Driver がインストールされます。
C:\Program Files\CData\CData JDBC Driver for ApacheKafka 20xxJ\lib\cdata.jdbc.apachekafka.jar
-
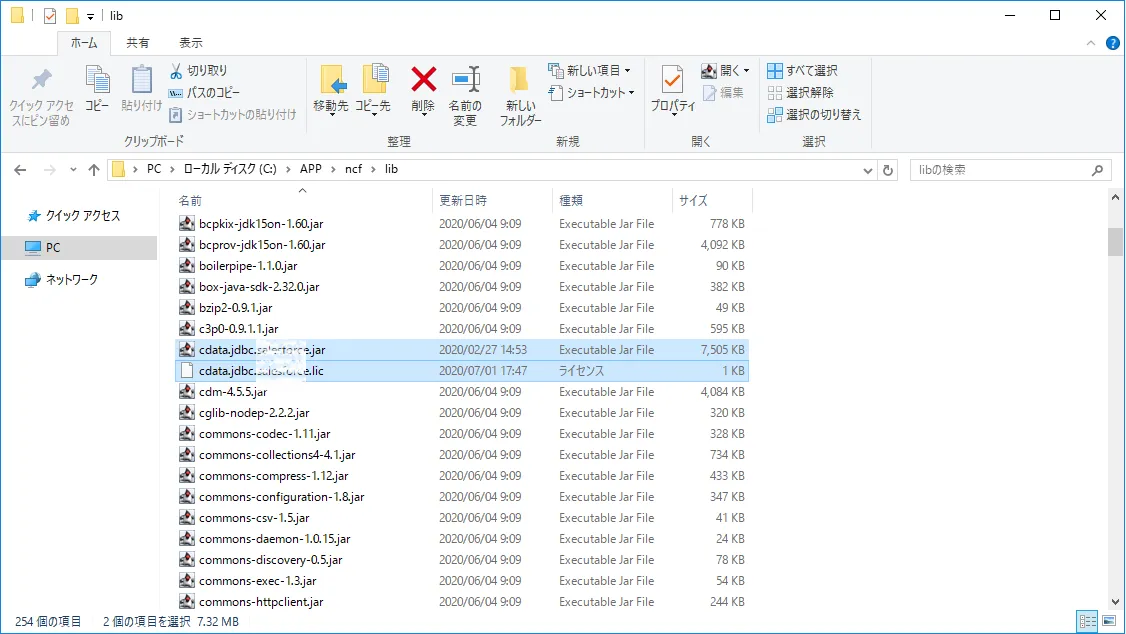
このcdata.jdbc.apachekafka.jar とcdata.jdbc.apachekafka.lic ファイルをコピーして、Neuron のC:\APP
cf\lib フォルダに配置します。
Neuron CF でのKafka のデータを扱うリポジトリの作成
-
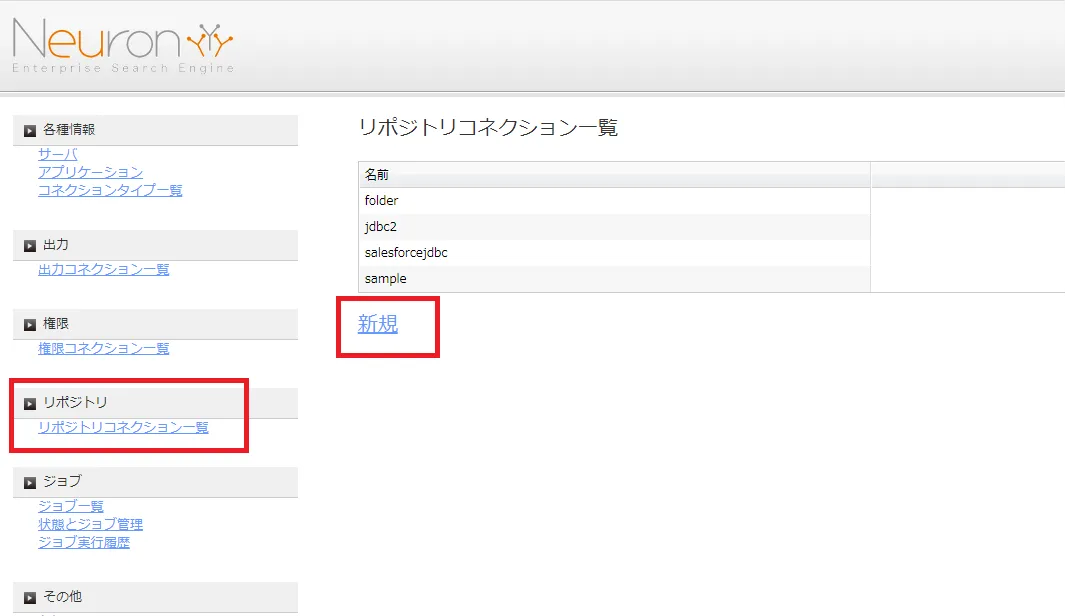
Neuron CF でクローラーの設定をGUI で行います。JDBC を読み取るためのリポジトリを作成します。Neuron の管理画面にログインし、[リポジトリ]→[リポジトリコレクション一覧]→[新規]をクリックします。
-
任意のリポジトリ名を入力します。タイプは[JDBC]を選択します。

-
次に、ドライバーのクラス名とJDBC 接続文字列でKafka への接続を行います。
Apache Kafka 接続プロパティの取得・設定方法
それでは、Apache Kafka に接続していきましょう。.NET ベースのエディションは、Confluent.Kafka およびlibrdkafka ライブラリに依存して機能します。 これらのアセンブリはインストーラーにバンドルされており、CData 製品と一緒に自動的にインストールされます。 別のインストール方法をご利用の場合は、NuGet から依存関係のあるConfluent.Kafka 2.6.0をインストールしてください。
Apache Kafka サーバーのアドレスを指定するには、BootstrapServers パラメータを使用します。
デフォルトでは、CData 製品はデータソースとPLAINTEXT で通信しており、これはすべてのデータが暗号化なしで送信されることを意味します。 通信を暗号化したい場合は、以下の設定を行ってください:
- UseSSL をtrue に設定し、CData 製品がSSL 暗号化を使用するように構成します
- SSLServerCert およびSSLServerCertType を設定して、サーバー証明書をロードします
Apache Kafka への認証
続いて、認証方法を設定しましょう。Apache Kafka データソースでは、以下の認証方法をサポートしています:
- Anonymous
- Plain
- SCRAM ログインモジュール
- SSL クライアント証明書
- Kerberos
Anonymous 認証
Apache Kafka の特定のオンプレミスデプロイメントでは、認証接続プロパティを設定することなくApache Kafka に接続できます。 このような接続はanonymous(匿名)と呼ばれます。
匿名認証を行うには、以下のプロパティを設定してください。
- AuthScheme:None
その他の認証方法については、ヘルプドキュメントをご確認ください。
ドライバクラス名:cdata.jdbc.apachekafka.ApacheKafkaDriver
接続文字列:jdbc:apachekafka:User=admin;Password=pass;BootStrapServers=https://localhost:9091;Topic=MyTopic;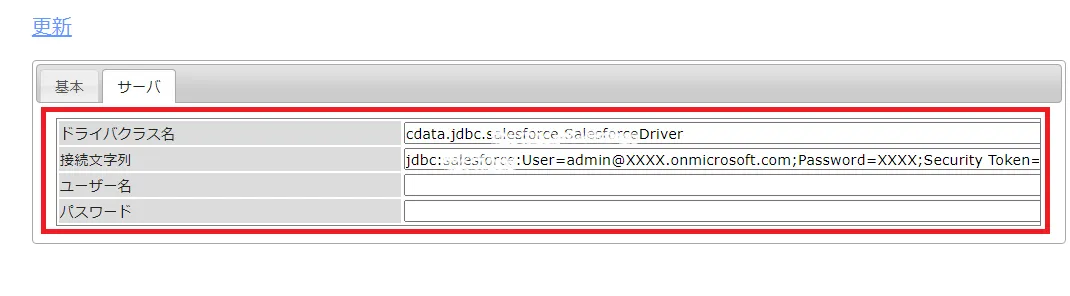
- [更新]をクリックして、Kafka に接続するリポジトリコレクションができました。
Neuron でKafka のデータをクローリングするジョブを作成
続いて、Kafka のどのデータをどのようにクローリングするのかをジョブで定義していきます。
-
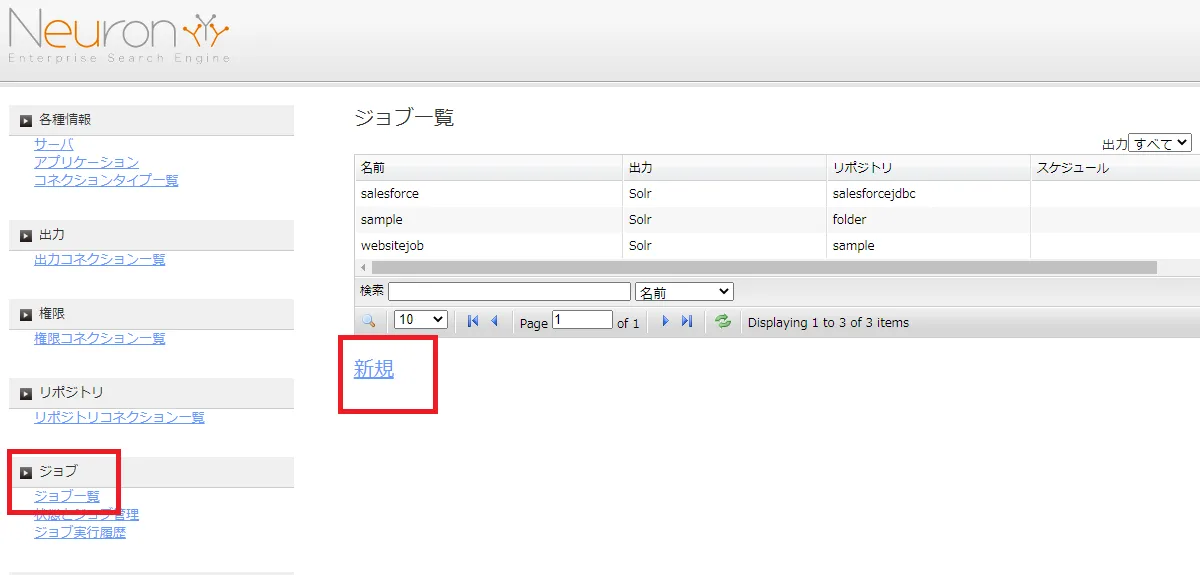
管理画面で[ジョブ]→[ジョブ一覧]→[新規]とクリックします。
-
任意のジョブ名を入力します。出力先にはSolr を選択します。リポジトリは先ほど作成したKafka に接続するリポジトリコレクションを選びます。
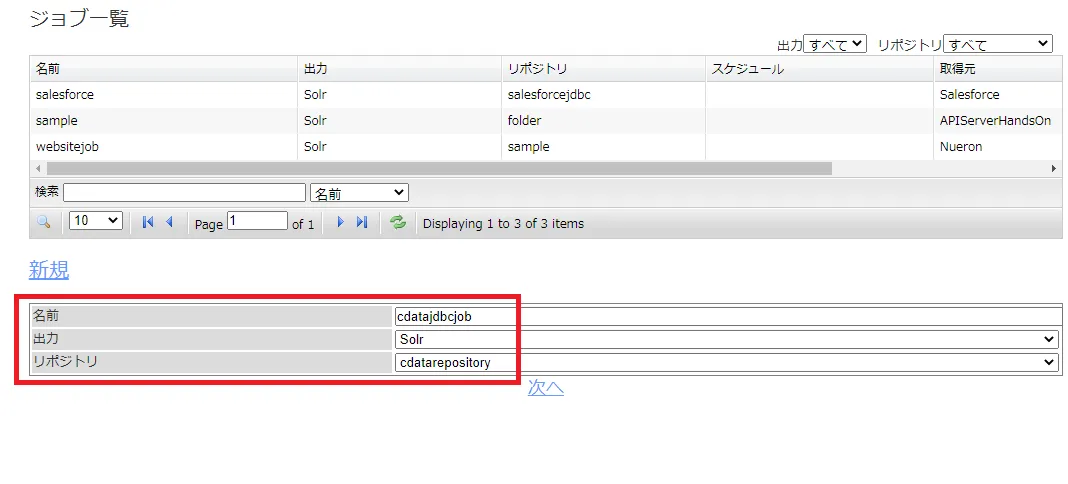
-
次に基本タブからジョブ実行を手動にするか、定期実行するかを自由に設定します。
-
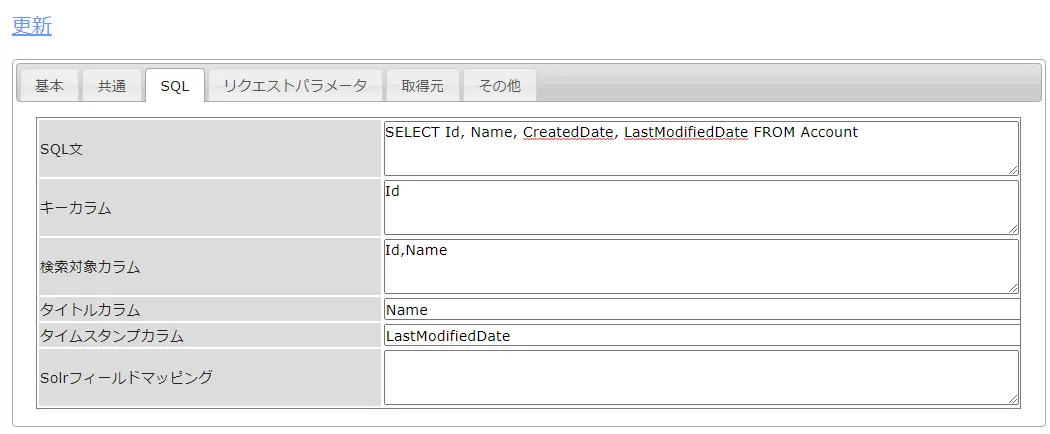
SQL タブでは、どんなデータを取得するのか、テーブル名やカラム、フィルタリング条件などを設定できます。CData JDBC ドライバがKafka のデータをテーブルにモデル化しているので、標準SQL でKafka をクエリすることができます。
- SQL文:SELECT Id, Column1 FROM SampleTable_1
- キーカラム:Id など取得テーブルのキーとなるカラム
- 検索対象カラム:検索の対象とするカラム
- タイトルカラム:検索結果のタイトルとするカラム
- タイムスタンプカラム:タイムスタンプとなるカラムがあれば、ここで指定します
- リクエストパラメータでは、検索結果レコードのURL (があれば)を設定することもできます。URL を表示できると表示された検索結果からレコードに簡単に移動できます。
- 取得元では、ラベルを設定しておきます。[更新]をクリックして、クローラージョブの設定を完了します。
Neuron でKafka のデータをクロールするジョブを実行
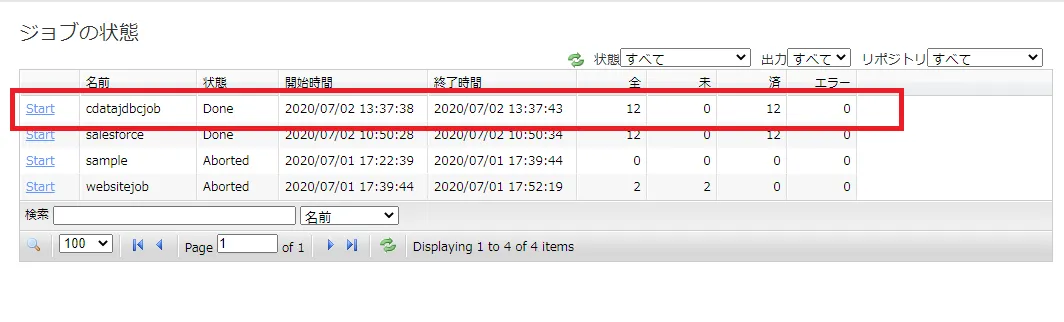
実際にNeuron で作成したジョブを実行します。[ジョブ]→[状態とジョブ管理]をクリックし、作成したジョブの[Start]をクリックします。
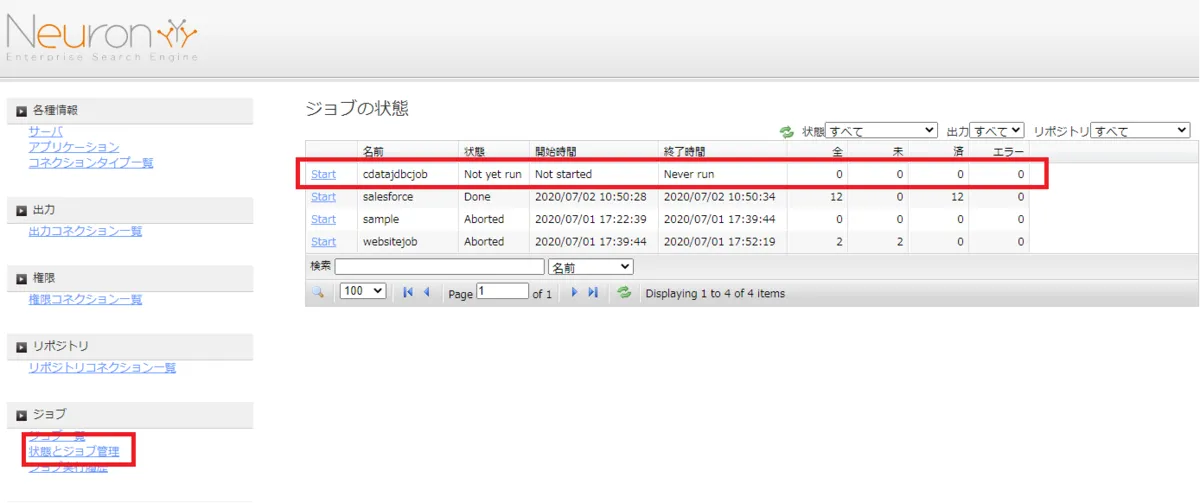
ジョブが正常完了すると、[Done]がステータスとして表示されます。
Neuron 上でのKafka のデータの検索の実施
実際にNeuron 上で検索ができるか確認してみます。取得元を絞り込むこと、内容やファイル名での検索、ファイルサイズやファイル更新日の絞り込み、部分一致や全部一致で検索が可能です。 検索をかけてみると、以下のようにデータを取得できました。
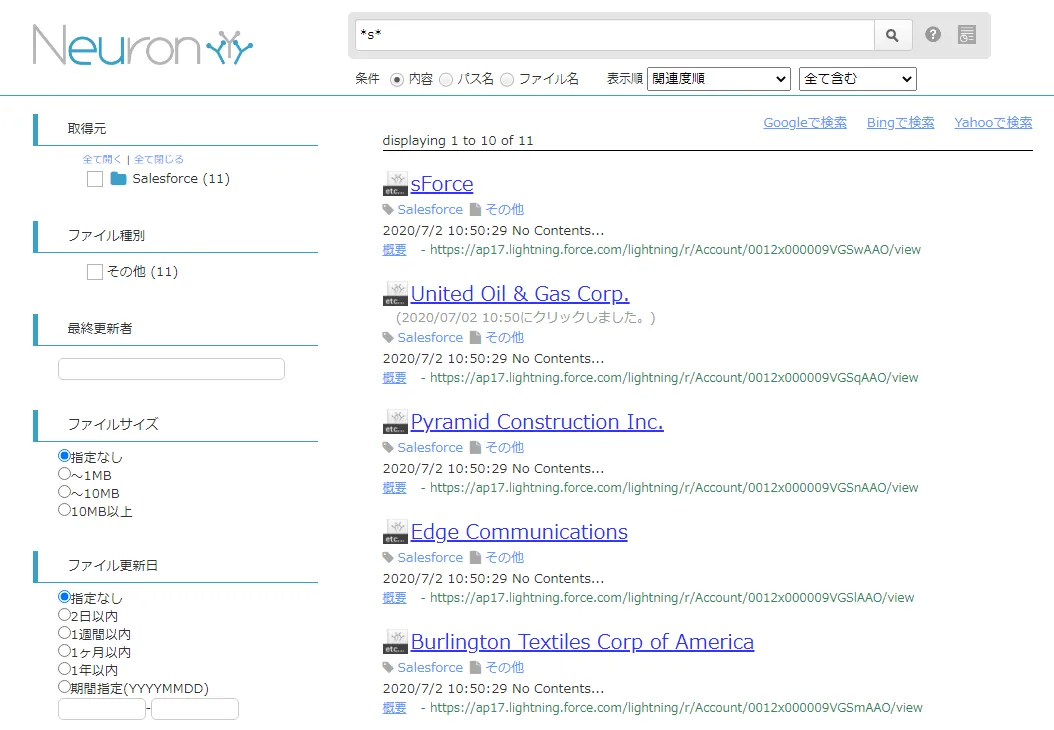
CData JDBC Driver for ApacheKafka をNeuron で使うことで、Kafka コネクタとして機能し、簡単にデータを取得して同期することができました。ぜひ、30日の無償評価版をお試しください。
はじめる準備はできましたか?
Apache Kafka Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード