





Azure Data Factory を使用してHive のデータをインポート

Azure Data Factory(ADF)は、フルマネージドのサーバーレスデータ統合サービスです。 CData Connect AI と組み合わせると、ADF はデータフローでHive のデータにクラウドベースで即座にアクセスできます。 この記事では、Connect AI を使用してHive に接続し、ADF でHive のデータにアクセスする方法を紹介します。
Connect AI からHive への接続
CData Connect AI では、直感的なクリック操作ベースのインターフェースを使ってデータソースに接続できます。
- Connect AI にログインし、 Add Connection をクリックします。
- Add Connection パネルで「Hive」を選択します。
-
必要な認証プロパティを入力し、Hive に接続します。
Apache Hive への接続を確立するには以下を指定します。
- Server:HiveServer2 をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:HiveServer2 インスタンスへの接続用のポートに設定。
- TransportMode:Hive サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
- CData 製品においてTLS/SSL を有効化するには、UseSSL をTrue に設定します
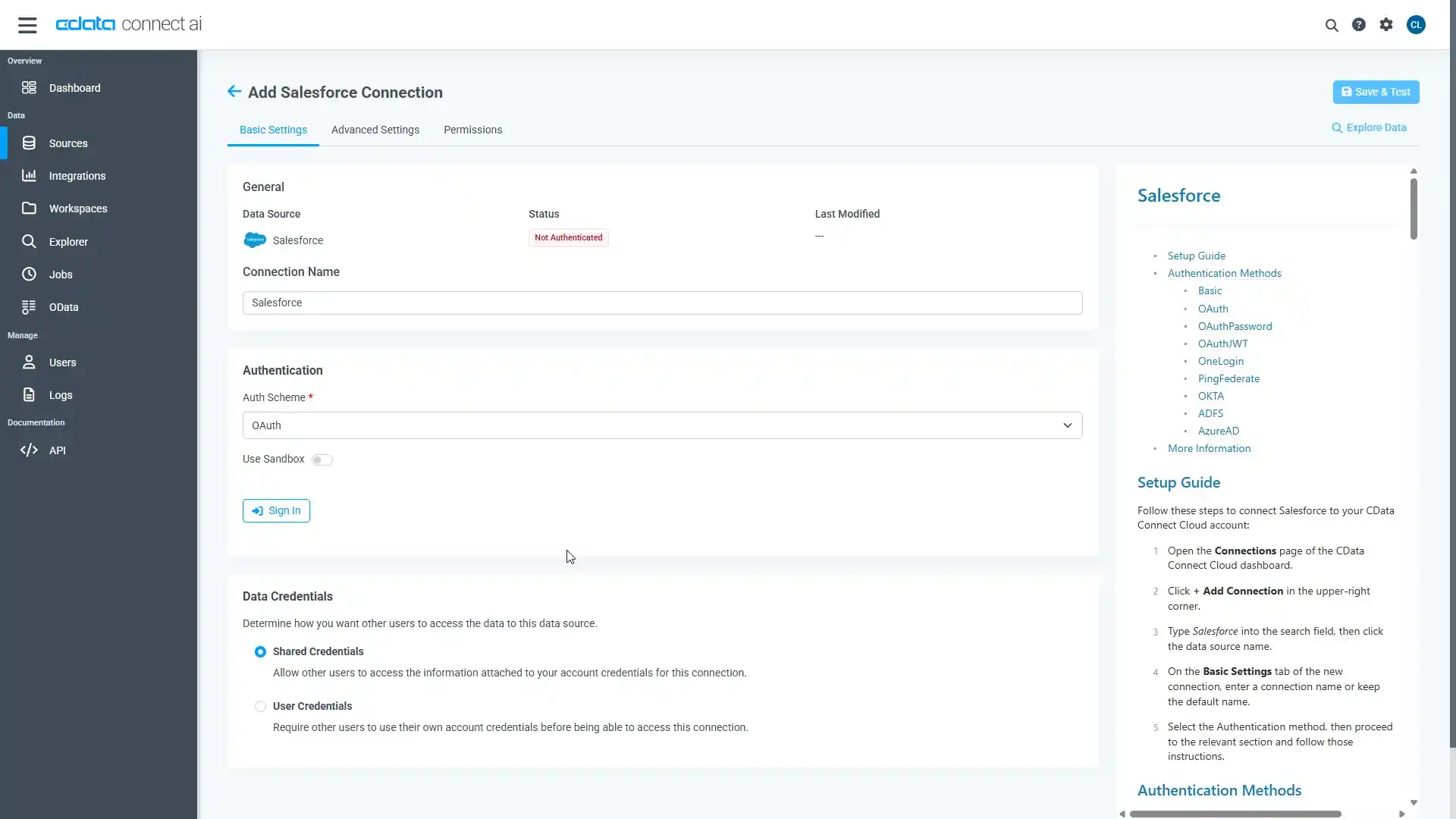
- Create & Test をクリックします。
-
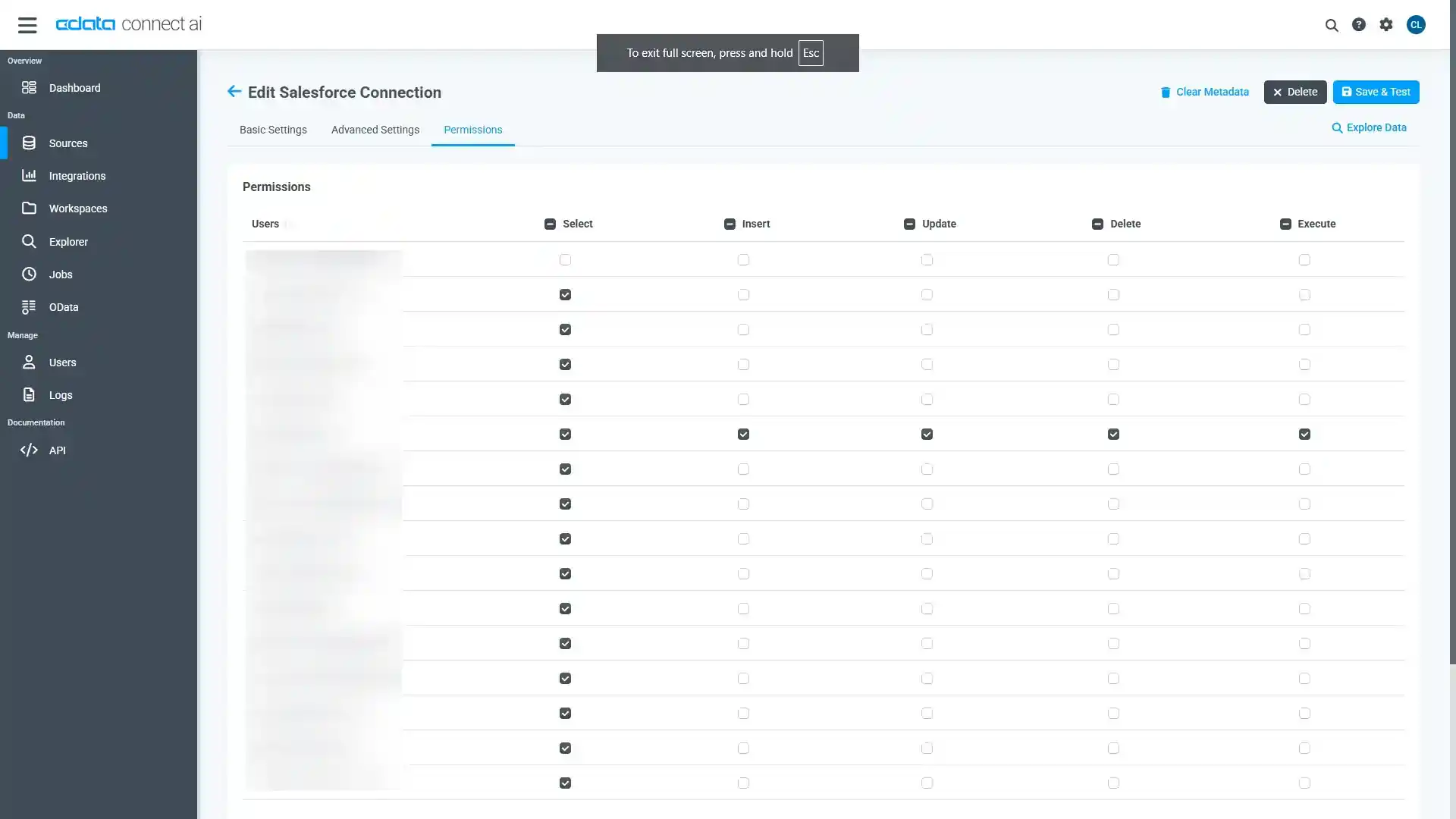
Add Hive Connection ページのPermissions タブに移動し、ユーザーベースのアクセス許可を更新します。

パーソナルアクセストークンの取得
OAuth 認証をサポートしていないサービス、アプリケーション、プラットフォーム、またはフレームワークから接続する場合は、認証に使用するパーソナルアクセストークン(PAT)を作成できます。 きめ細かなアクセス管理を行うために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
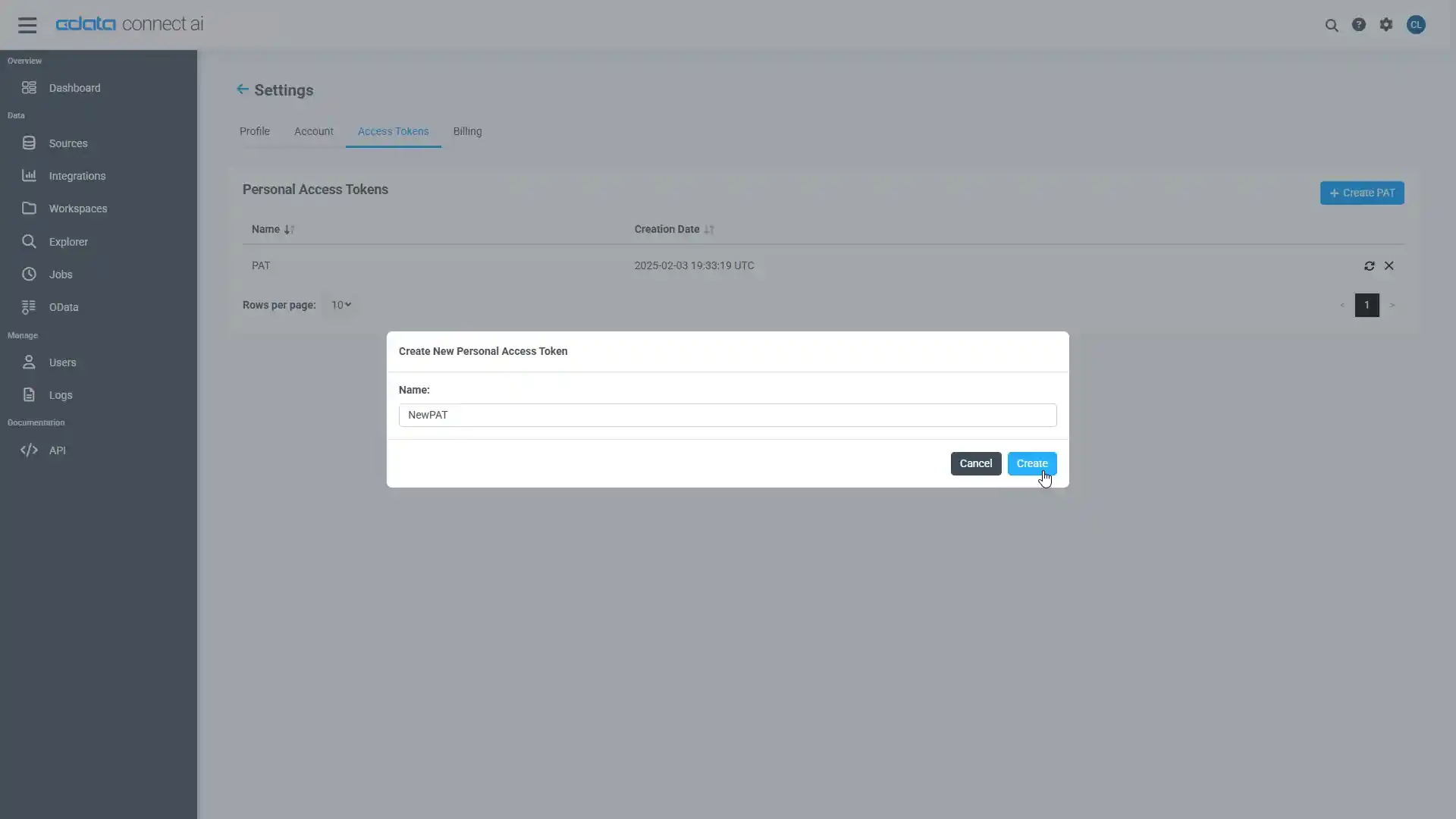
- Connect AI アプリの右上にあるユーザー名をクリックし、「User Profile」をクリックします。
- User Profile ページでPersonal Access Token セクションにスクロールし、 Create PAT をクリックします。
- PAT の名前を入力して Create をクリックします。
- パーソナルアクセストークンは作成時にしか表示されないため、必ずコピーして安全に保存してください。
接続設定が完了すると、Azure Data Factory からHive のデータへ接続できるようになります。
Azure Data Factory からリアルタイムHive のデータにアクセス
Azure Data Factory からCData Connect AI の仮想SQL Server API への接続を確立するには、以下の手順を実行します。
- Azure Data Factory にログインします。
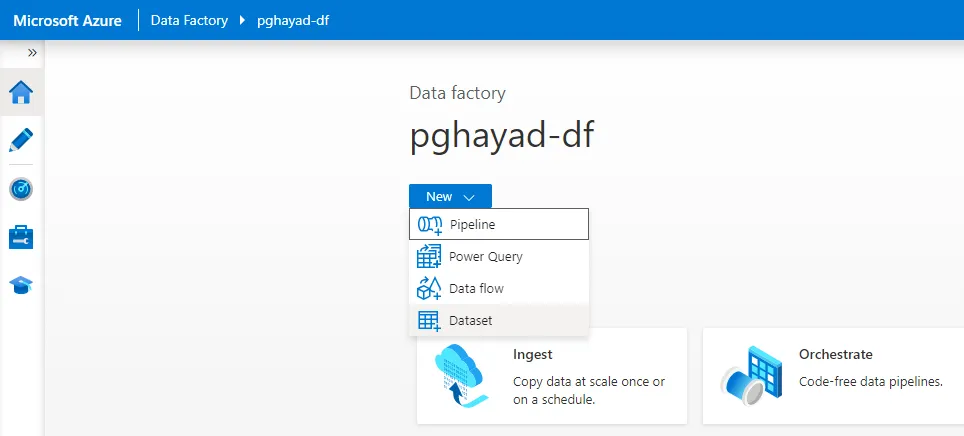
- まだData Factory を作成していない場合は、「New -> Dataset」をクリックします。
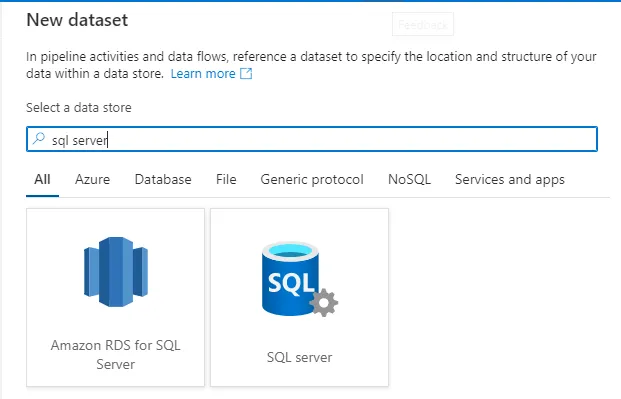
- 検索バーにSQL Server と入力し、表示されたら選択します。次の画面で、サーバーの名前を入力します。 Linked service フィールドで「New」を選択します。
-
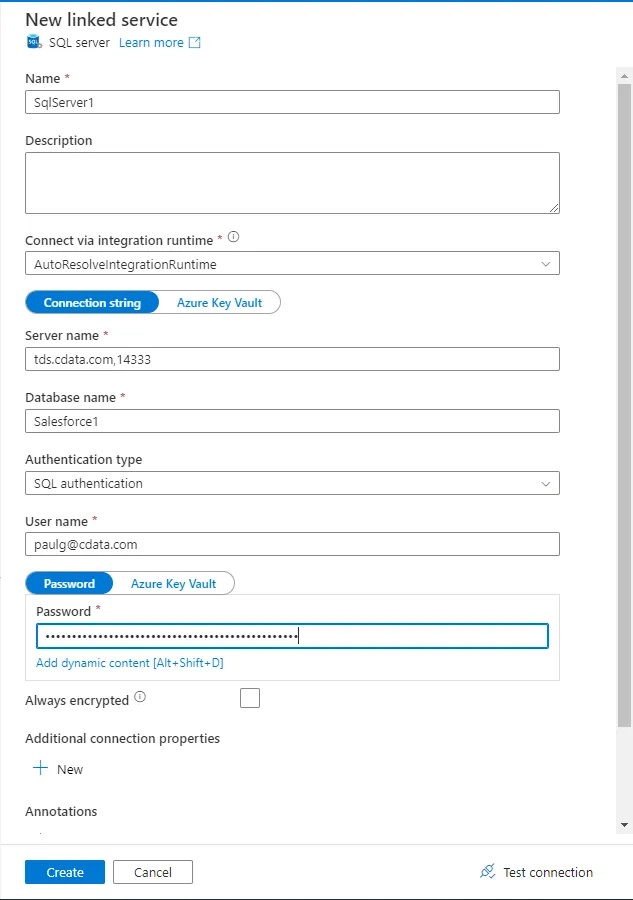
接続設定を入力します。
- Name - 任意の名前を入力。
- Server name - 仮想SQL Server のエンドポイントとポートをカンマで区切って入力。例:tds.cdata.com,14333
- Database name - 接続したいCData Connect AI データソースのConnection Name を入力。例:ApacheHive1
- User Name - CData Connect AI のユーザー名を入力。ユーザー名はCData Connect AI のインターフェースの右上に表示されています。 例:test@cdata.com
- Password - Password(Azure Key Vault ではありません)を選択してSettings ページで生成したPAT を入力。
- 「Create」をクリックします。
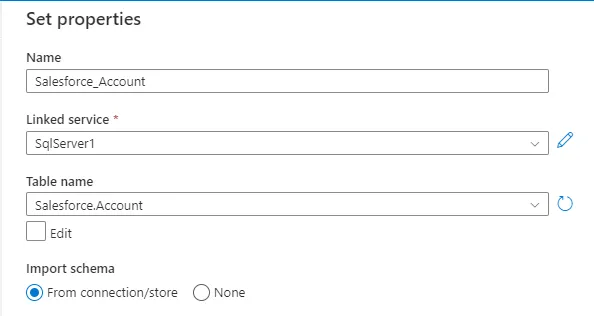
- Set properties で、Name を設定し、続けて先ほど作成したLinked service、利用可能なTable name、Import schema のfrom connection/store を選択します。 「OK」をクリックします。
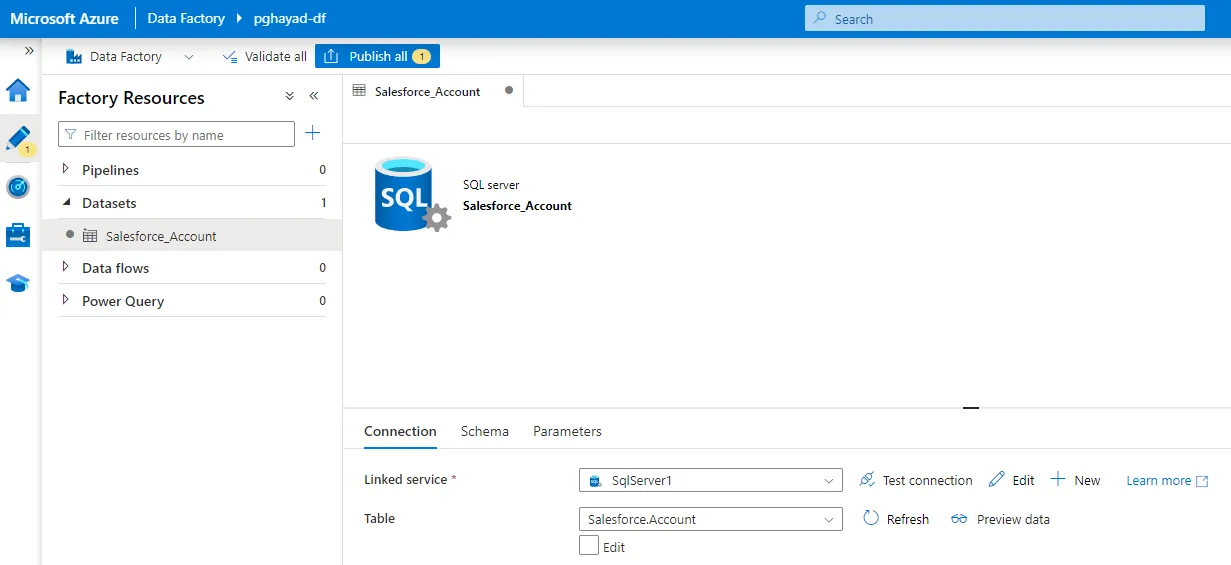
- リンクされたサービスを作成すると、以下の画面が表示されます。
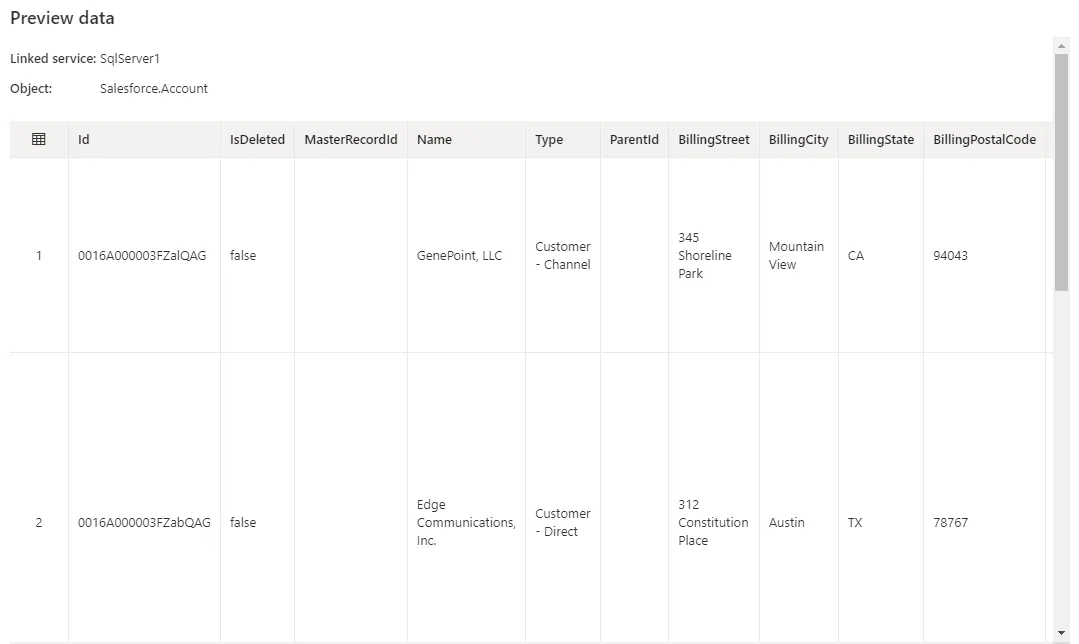
- Preview data をクリックすると、インポートされたHive テーブルが表示されます。
 Azure Data Factory でデータフローを作成する際、このデータセットを使用できるようになりました。
Azure Data Factory でデータフローを作成する際、このデータセットを使用できるようになりました。
CData Connect AI の入手
CData Connect AI の14日間無償トライアルを利用して、クラウドアプリケーションから直接100を超えるSaaS、ビッグデータ、NoSQL データソースへのSQL アクセスをお試しください!