





Google Data Catalog のデータをAI アシスタントのPEP から利用する方法

CData API Server と ADO.NET Provider / JDBC Driver for GoogleDataCatalog を使って、AI アシスタントPEP(https://pep.work/) から Google Data Catalog に接続して、チャットボットでリアルタイムGoogle Data Catalogデータを使った応答を可能にする方法を説明します。
API Server の設定
以下のリンクからAPI Server の無償トライアルをスタートしたら、セキュアなGoogle Data Catalog OData サービスを作成していきましょう。
Google Data Catalog への接続
PEP からGoogle Data Catalog のデータを操作するには、まずGoogle Data Catalog への接続を作成・設定します。
- API Server にログインして、「Connections」をクリック、さらに「接続を追加」をクリックします。
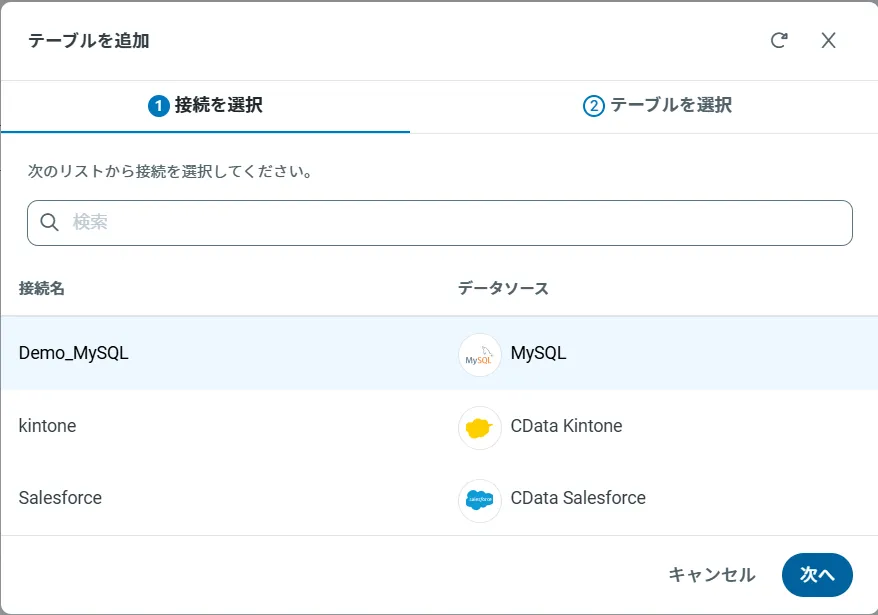
- 「接続を追加」をクリックして、データソースがAPI Server に事前にインストールされている場合は、一覧から「Google Data Catalog」を選択します。
- 事前にインストールされていない場合は、コネクタを追加していきます。コネクタ追加の手順は以下の記事にまとめてありますので、ご確認ください。
CData コネクタの追加方法はこちら >> - それでは、Google Data Catalog への接続設定を行っていきましょう!
-
Google Data Catalog 接続プロパティの取得・設定方法
認証プロパティを追加する前に、次の接続プロパティを設定してください。
- OrganizationId:接続するGoogle Cloud Platform の組織リソースに関連付けられたID。これはGCP コンソールに移動して確認してください。 「プロジェクト」ドロップダウンメニューを開き、リストから組織へのリンクをクリックします。このページから組織ID を取得できます。
- ProjectId:接続するGCP のプロジェクトリソースに関連付けられたID。GCP コンソールのダッシュボードに移動し、「プロジェクトを選択」のメニューからお好みのプロジェクトを選択して確認してください。プロジェクトID は、「プロジェクト情報」項目に表示されます。
Google Data Catalog への認証
CData 製品は、認証にユーザーアカウント、サービスアカウント、およびGCP インスタンスアカウントの使用をサポートします。
OAuth の設定方法については、ヘルプドキュメントの「OAuth」セクションを参照してください。
- 接続情報の入力が完了したら、「保存およびテスト」をクリックします。
Google Data Catalog 接続プロパティの取得・設定方法
認証プロパティを追加する前に、次の接続プロパティを設定してください。
- OrganizationId:接続するGoogle Cloud Platform の組織リソースに関連付けられたID。これはGCP コンソールに移動して確認してください。 「プロジェクト」ドロップダウンメニューを開き、リストから組織へのリンクをクリックします。このページから組織ID を取得できます。
- ProjectId:接続するGCP のプロジェクトリソースに関連付けられたID。GCP コンソールのダッシュボードに移動し、「プロジェクトを選択」のメニューからお好みのプロジェクトを選択して確認してください。プロジェクトID は、「プロジェクト情報」項目に表示されます。
Google Data Catalog への認証
CData 製品は、認証にユーザーアカウント、サービスアカウント、およびGCP インスタンスアカウントの使用をサポートします。
OAuth の設定方法については、ヘルプドキュメントの「OAuth」セクションを参照してください。
API Server のユーザー設定
次に、API Server 経由でGoogle Data Catalog にアクセスするユーザーを作成します。「Users」ページでユーザーを追加・設定できます。やってみましょう。
- 「Users」ページで ユーザーを追加をクリックすると、「ユーザーを追加」ポップアップが開きます。
-
次に、「ロール」、「ユーザー名」、「権限」プロパティを設定し、「ユーザーを追加」をクリックします。

-
その後、ユーザーの認証トークンが生成されます。各ユーザーの認証トークンとその他の情報は「Users」ページで確認できます。

Google Data Catalog 用のAPI エンドポイントの作成
ユーザーを作成したら、Google Data Catalog のデータ用のAPI エンドポイントを作成していきます。
-
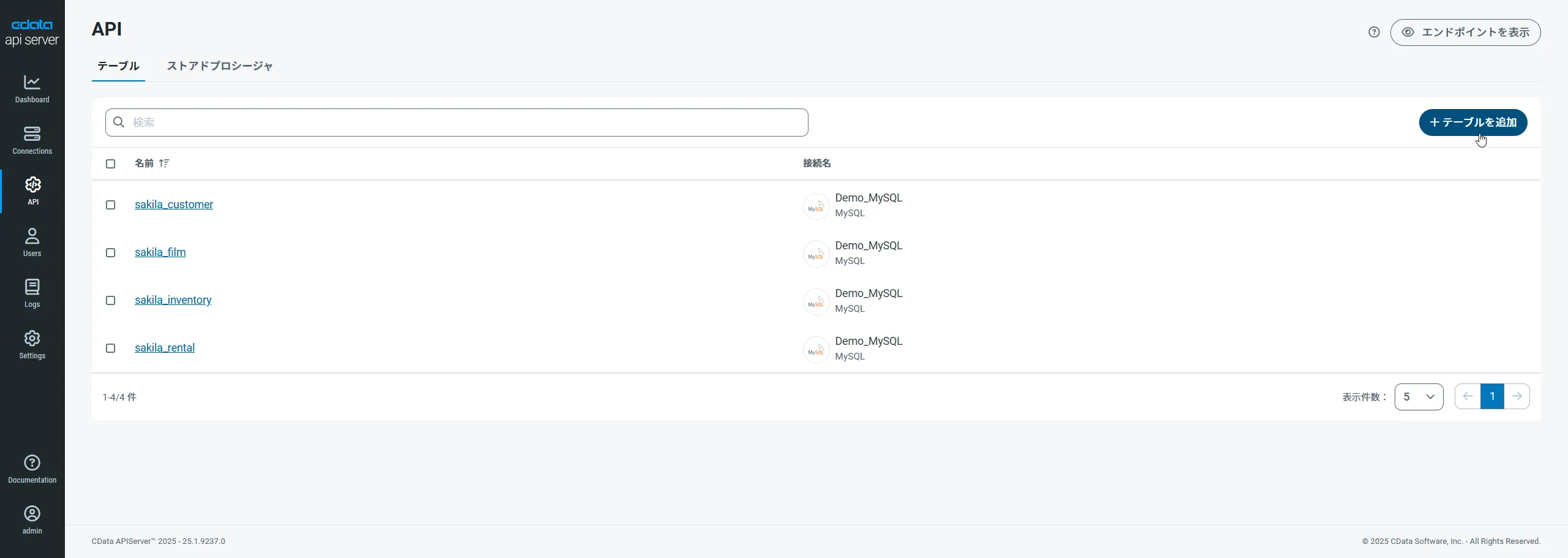
まず、「API」ページに移動し、
「 テーブルを追加」をクリックします。
-
アクセスしたい接続を選択し、次へをクリックします。
-
接続を選択した状態で、各テーブルを選択して確認をクリックすることでエンドポイントを作成します。

OData のエンドポイントを取得
以上でGoogle Data Catalog への接続を設定してユーザーを作成し、API Server でGoogle Data Catalog データのAPI を追加しました。これで、OData 形式のGoogle Data Catalog データをREST API で利用できます。API Server の「API」ページから、API のエンドポイントを表示およびコピーできます。

オンプレミスDB やファイルからのAPI Server 使用(オプション)
オンプレミスRDB やExcel/CSV などのファイルのデータを使用する場合には、API Server のCloug Gateway / SSH ポートフォワーディングが便利です。是非、Cloud Gatway の設定方法 記事を参考にしてください。
PEP でGoogle Data Catalog のデータをチャットで使う設定
前項まででAPI ができたので、ここからはPEP 側での設定作業です。
PEP でGoogle Data Catalog のAPI をコールするシナリオを作成
PEP 側ではあらかじめSlack などのアプリケーションを構成しておきます。ここにAPI Server をコールするAI アシスタントのシナリオを追加していきます。
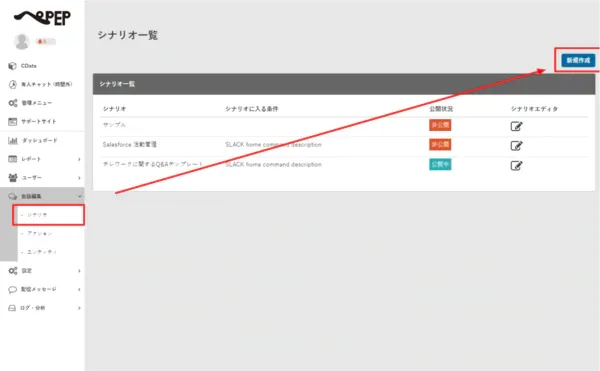
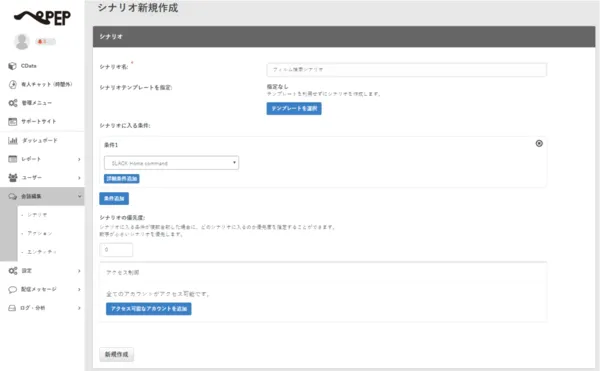
- 「会話編集」→「シナリオ」に移動し、新しいシナリオを作成します。
- シナリオ名を入力します。この例では、条件はSlack Homeを 選択しています。
- 「新規作成」ボタンをクリックすると、以下のようなシナリオエディタ画面に移動します。これでシナリオを作成する準備ができました。
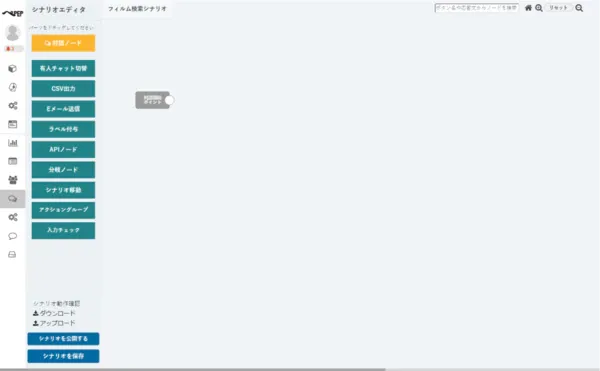
Google Data Catalog のAPI の接続箇所の設定
具体的にAPI連携を含めたシナリオを作っていきます。
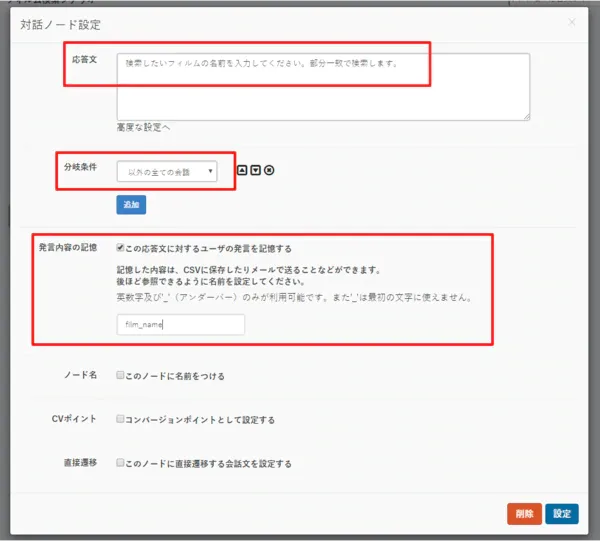
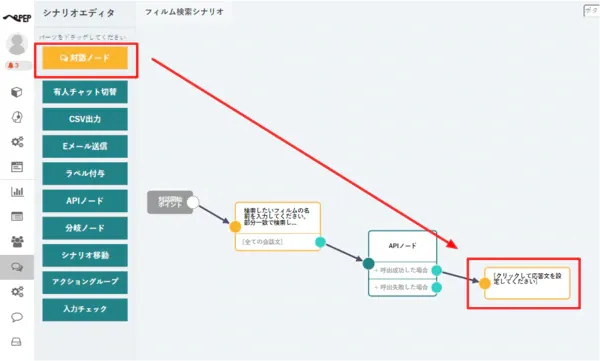
- 最初に検索したい文字列を受け取るための対話ノードを配置して、以下のように構成します。
- ポイントは分岐条件で「以下のすべての会話」、発言内容の記憶で「film_name」として、会話した内容を変数に保存することです。
- 対話ノードを配置したら、APIノードを追加して、対話ノードから接続していきます。
- APIノードでは、以下のように CData API Server へのリクエストを構成します。
ポイントは2つです。CData API Server は Filter 機能によって、取得するデータを絞り込むことができます。その指定が「$filter=contains(title,'{{ state.scenario_4.form.film_name }}')」の部分です。 「{{ state.scenario_4.form.film_name }}」は直前の対話ノードで設定した変数をパラメータとして渡しています。「scenario_4」はPEP のシナリオIDですので、作成したシナリオに合わせて変更してください。 - HTTPヘッダーにAPI Server のユーザートークンを指定します。
- API名:任意の名前を設定
- URL:http://apiserverurl/api.rsc/film_list?$filter=contains(title,'{{ state.scenario_4.form.film_name }}')
- HTTPメソッド:GET
- Content-Type:JSON
- HTTPヘッダー:キー「x-cdata-authtoken」、値「予め取得したAPI Serverのトークン」を指定

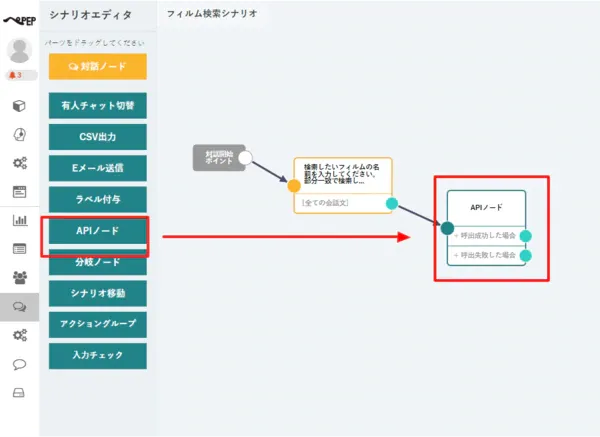

これで保存すると、API ノードが使えるようになります。
取得したGoogle Data Catalog からのレスポンスの表示方法
最後に後続の対話ノードを構成し、取得した検索結果を表示します。
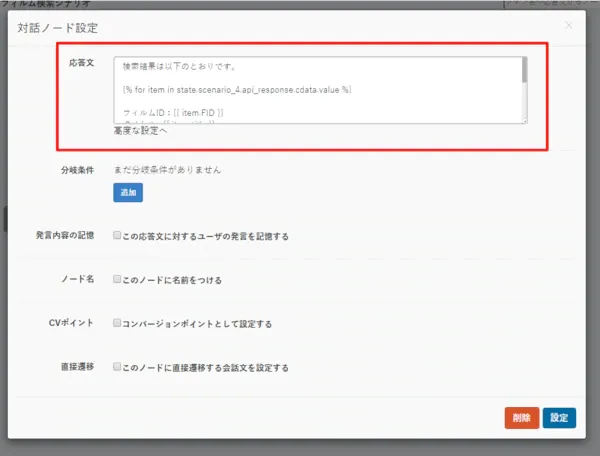
対話ノードの応答文には、以下のような文章を埋め込みます。
検索結果は以下のとおりです。
{% for item in state.scenario_4.api_response.film_search.value %}
フィルムID:{{ item.FID }}
タイトル : {{ item.title }}
値段:{{ item.price }}
カテゴリー:{{ item.category }}
俳優: -----
{% endfor %}
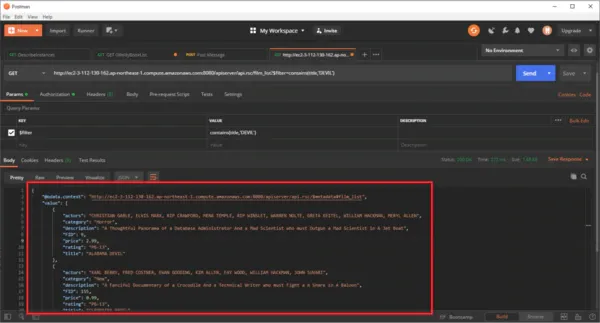
ここでポイントになるのは、API Server から受け取るJSONのレスポンスの分解方法です。
API Server のレスポンスはオブジェクト直下にvalueという配列要素があり、このレスポンスは「{{state.scenario_4.api_response.film_search.value}}」の形でアクセスできます。
設定イメージ:state.シナリオID.api_response.APIノード名.value
これを「FOR」での繰り返し処理で取得して、文章として表示する仕組みになっています。
これで設定は完了です。実際に動かしてみると、Google Data Catalog →API Server → PEP 経由でデータを取得して表示していることがわかるかと思います。
CData API Server の無償版およびトライアル
CData API Server は、無償版および30日の無償トライアルがあります。是非、API Server ページ から製品をダウンロードしてお試しください。