





【ノーコード】Slingshot からDatabricks のデータに接続するバックエンドAPI を開発

CData API Server を使って、Slingshot から Databricks に接続してダッシュボードを作成する方法を説明します。
Databricks データ連携について
CData を使用すれば、Databricks のライブデータへのアクセスと統合がこれまでになく簡単になります。お客様は CData の接続機能を以下の目的で利用しています:
- Runtime バージョン 9.1 - 13.X から Pro および Classic Databricks SQL バージョンまで、すべてのバージョンの Databricks にアクセスできます。
- あらゆるホスティングソリューションとの互換性により、お好みの環境で Databricks を使用し続けることができます。
- パーソナルアクセストークン、Azure サービスプリンシパル、Azure AD など、さまざまな方法で安全に認証できます。
- Databricks ファイルシステム、Azure Blob ストレージ、AWS S3 ストレージを使用して Databricks にデータをアップロードできます。
多くのお客様が、さまざまなシステムから Databricks データレイクハウスにデータを移行するために CData のソリューションを使用していますが、ライブ接続ソリューションを使用して、データベースと Databricks 間の接続をフェデレートしているお客様も多数います。これらのお客様は、SQL Server リンクサーバーまたは Polybase を使用して、既存の RDBMS 内から Databricks へのライブアクセスを実現しています。
一般的な Databricks のユースケースと CData のソリューションがデータの問題解決にどのように役立つかについては、ブログをご覧ください:What is Databricks Used For? 6 Use Cases
はじめに
API Server の設定
以下のリンクからAPI Server の無償トライアルをスタートしたら、セキュアなDatabricks OData サービスを作成していきましょう。
Databricks への接続
Slingshot からDatabricks のデータを操作するには、まずDatabricks への接続を作成・設定します。
- API Server にログインして、「Connections」をクリック、さらに「接続を追加」をクリックします。
- 「接続を追加」をクリックして、データソースがAPI Server に事前にインストールされている場合は、一覧から「Databricks」を選択します。
- 事前にインストールされていない場合は、コネクタを追加していきます。コネクタ追加の手順は以下の記事にまとめてありますので、ご確認ください。
CData コネクタの追加方法はこちら >> - それでは、Databricks への接続設定を行っていきましょう!
-
Databricks 接続プロパティの取得・設定方法
Databricks クラスターに接続するには、以下のプロパティを設定します。
- Database:Databricks データベース名。
- Server:Databricks クラスターのサーバーのホスト名。
- HTTPPath:Databricks クラスターのHTTP パス。
- Token:個人用アクセストークン。この値は、Databricks インスタンスのユーザー設定ページに移動してアクセストークンタブを選択することで取得できます。
Databricks への認証
CData は、次の認証スキームをサポートしています。
- 個人用アクセストークン
- Microsoft Entra ID(Azure AD)
- Azure サービスプリンシパル
- OAuthU2M
- OAuthM2M
個人用アクセストークン
認証するには、次を設定します。
- AuthScheme:PersonalAccessToken。
- Token:Databricks サーバーへの接続に使用するトークン。Databricks インスタンスのユーザー設定ページに移動してアクセストークンタブを選択することで取得できます。
その他の認証方法については、ヘルプドキュメント の「はじめに」セクションを参照してください。
- 接続情報の入力が完了したら、「保存およびテスト」をクリックします。
Databricks 接続プロパティの取得・設定方法
Databricks クラスターに接続するには、以下のプロパティを設定します。
- Database:Databricks データベース名。
- Server:Databricks クラスターのサーバーのホスト名。
- HTTPPath:Databricks クラスターのHTTP パス。
- Token:個人用アクセストークン。この値は、Databricks インスタンスのユーザー設定ページに移動してアクセストークンタブを選択することで取得できます。
Databricks への認証
CData は、次の認証スキームをサポートしています。
- 個人用アクセストークン
- Microsoft Entra ID(Azure AD)
- Azure サービスプリンシパル
- OAuthU2M
- OAuthM2M
個人用アクセストークン
認証するには、次を設定します。
- AuthScheme:PersonalAccessToken。
- Token:Databricks サーバーへの接続に使用するトークン。Databricks インスタンスのユーザー設定ページに移動してアクセストークンタブを選択することで取得できます。
その他の認証方法については、ヘルプドキュメント の「はじめに」セクションを参照してください。
API Server のユーザー設定
次に、API Server 経由でDatabricks にアクセスするユーザーを作成します。「Users」ページでユーザーを追加・設定できます。やってみましょう。
- 「Users」ページで ユーザーを追加をクリックすると、「ユーザーを追加」ポップアップが開きます。
-
次に、「ロール」、「ユーザー名」、「権限」プロパティを設定し、「ユーザーを追加」をクリックします。

-
その後、ユーザーの認証トークンが生成されます。各ユーザーの認証トークンとその他の情報は「Users」ページで確認できます。

Databricks 用のAPI エンドポイントの作成
ユーザーを作成したら、Databricks のデータ用のAPI エンドポイントを作成していきます。
-
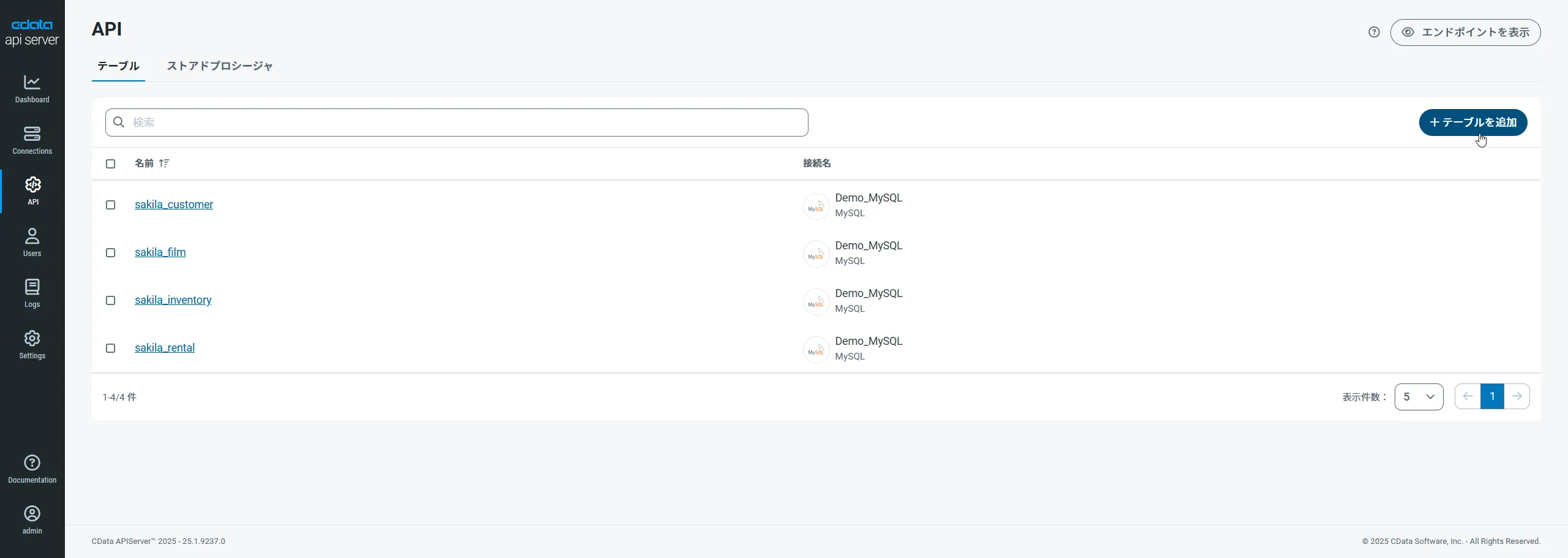
まず、「API」ページに移動し、
「 テーブルを追加」をクリックします。
-
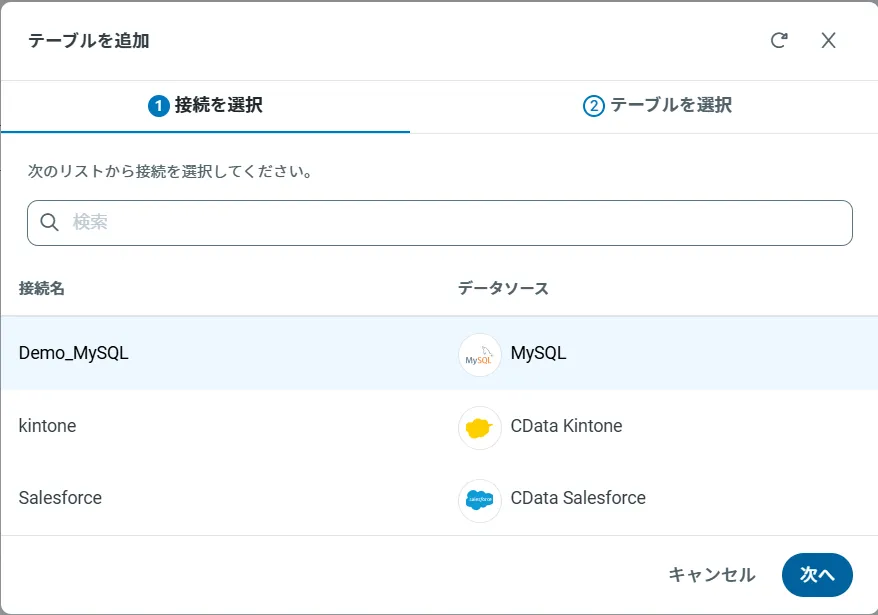
アクセスしたい接続を選択し、次へをクリックします。
-
接続を選択した状態で、各テーブルを選択して確認をクリックすることでエンドポイントを作成します。

OData のエンドポイントを取得
以上でDatabricks への接続を設定してユーザーを作成し、API Server でDatabricks データのAPI を追加しました。これで、OData 形式のDatabricks データをREST API で利用できます。API Server の「API」ページから、API のエンドポイントを表示およびコピーできます。

(任意)オンプレミスDB やファイルからのAPI Server 使用
オンプレミスRDB やExcel / CSV などのファイルのデータをセキュアに外部公開する場合には、API Server のCloud Gateway / SSH ポートフォワーディングが便利です。Cloud Gateway の設定方法 記事を参考にしてください。
Slingshot にデータソースを追加する
CData API Server の設定が完了したら、Slingshot 側に接続設定を追加しましょう。
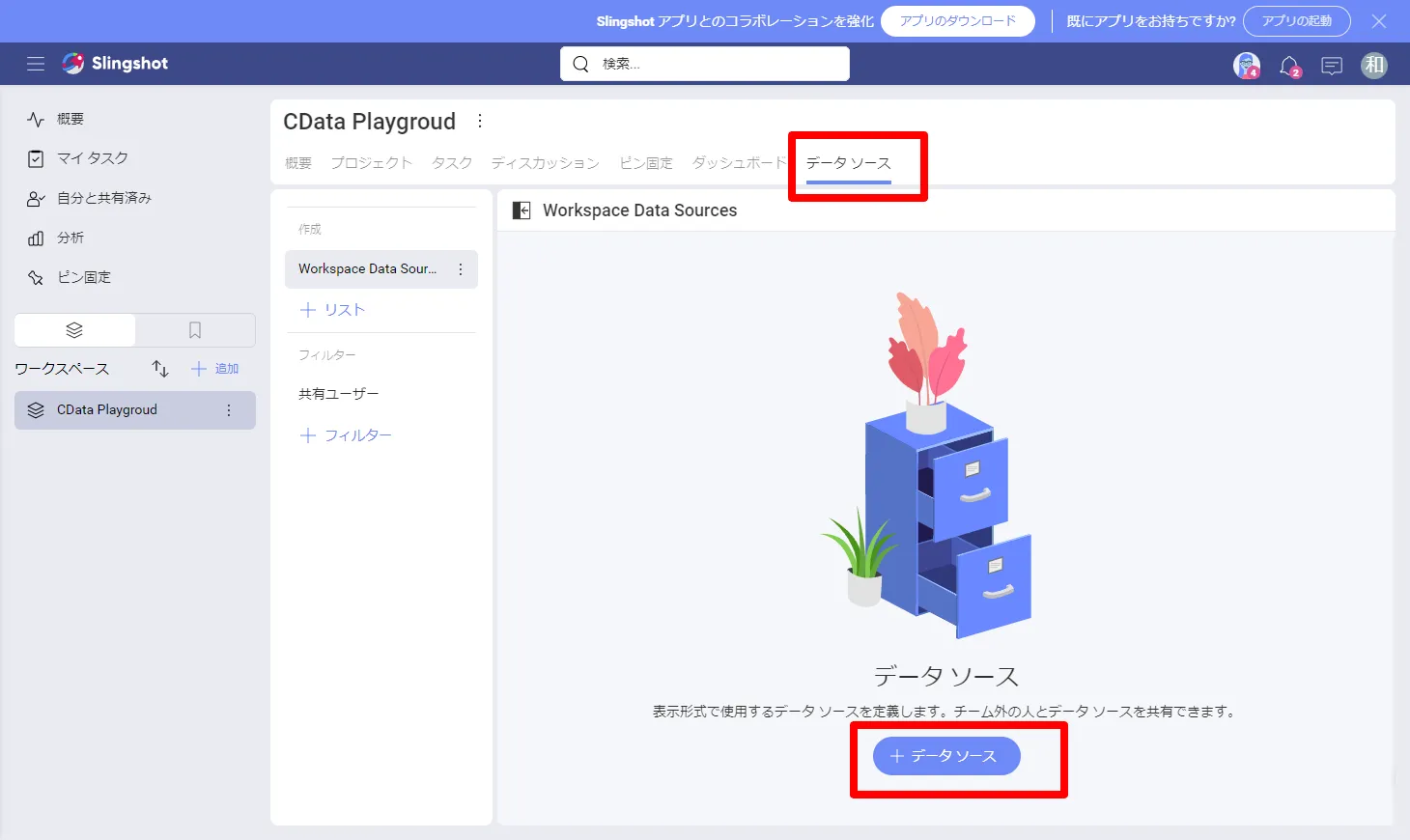
- Slingshot の対象のワークスペースに移動して「データソース」タブに移動し「+データソース」をクリックします。
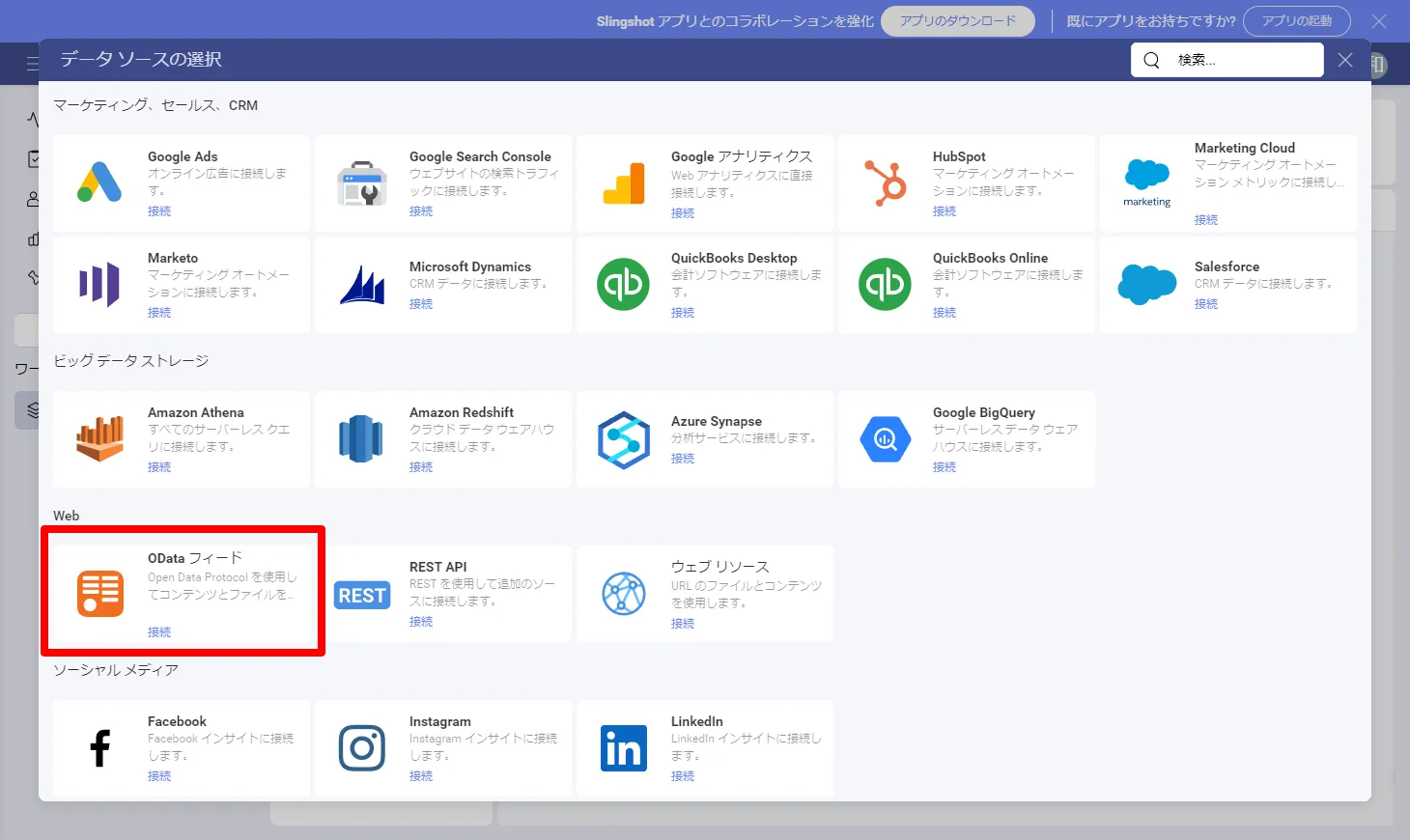
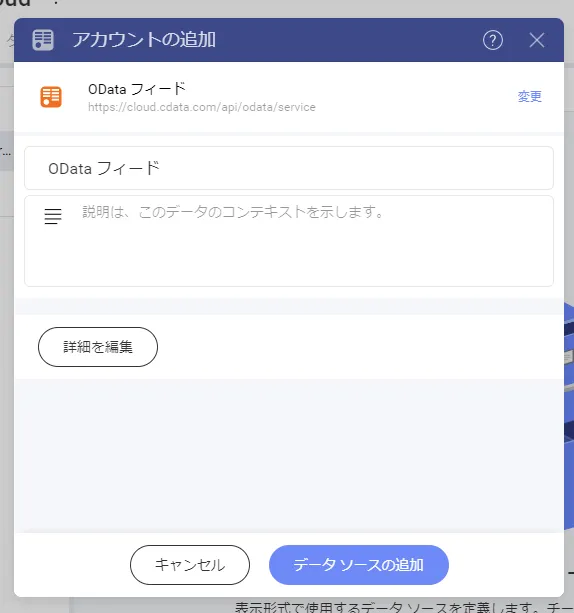
- データソースの一覧から利用したいサービスを選択します。ここで先程CData API Server で設定したOData エンドポイントの接続を追加します。
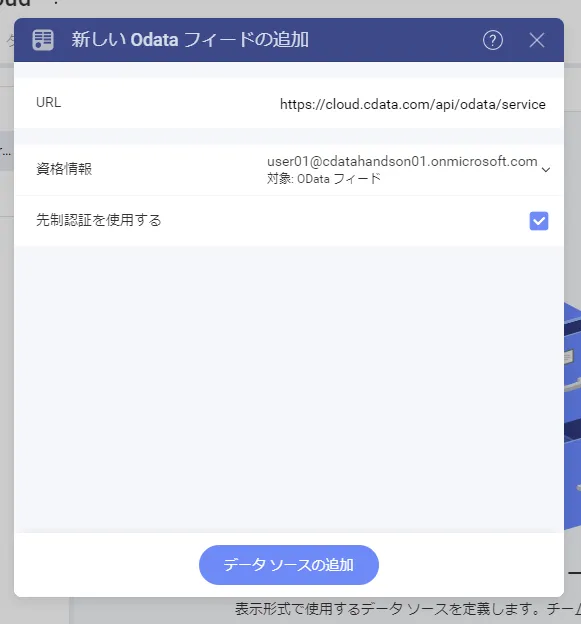
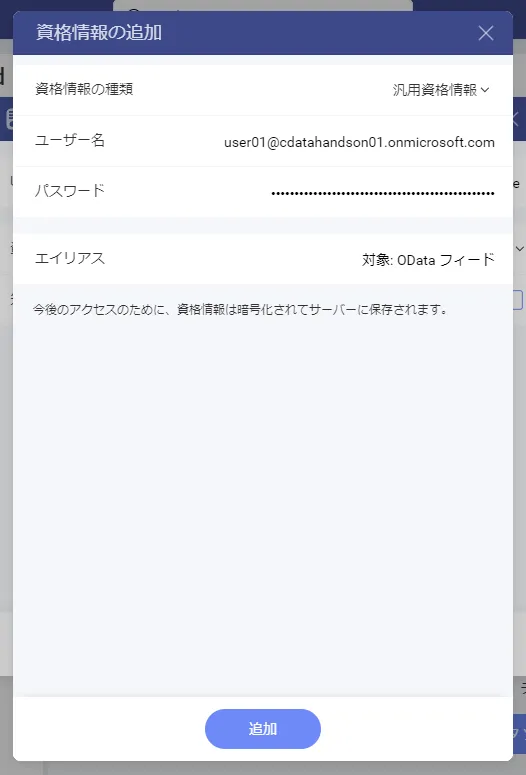
- 「URL」にOData エンドポイントのURL を指定し「先制認証を使用する」にチェックを入れます。その上で「資格情報」を追加しましょう。
- 資格情報の種類は「汎用資格情報」になります。合わせてCData API Server のユーザー名を入力し、パスワードには先程生成したトークンを入力します。
- あとは「データソースの追加」をクリックすれば、データソースの接続設定は完了になります。
ダッシュボードを作成する
すべての準備が整ったのでDatabricks のデータを活用してダッシュボードを作成していきましょう。
- 「ダッシュボード」タブに移動して「+ダッシュボード」をクリックします。
- 先程追加したCData API Server へのOData フィードデータソースが表示されるので、これを選択します。
- すると、事前にCData API Server 上で登録しておいたテーブルの一覧がエンティティのセットとして表示されるので、任意のエンティティを選択しましょう。
- これでSlingshot 上に対象のデータがシームレスに読み込まれます。あとは可視化するためのラベルや値を選択することで、以下のように簡単にビジュアライズが実施できます。


まとめと30日の無償評価版のご案内
このように Databricks 内のデータをSlingshot で利用することができるようになります。CData API Server は、30日の無償評価版があります。是非、お試しいただき、Slingshot からのデータ参照を体感ください。