





Coopel のシナリオで使えるDatabricks のデータ連携用のバックエンドAPI をノーコードで開発

CData API Server を使って、Coopel から Databricks に接続、データを取得する方法を説明します。
Databricks データ連携について
CData を使用すれば、Databricks のライブデータへのアクセスと統合がこれまでになく簡単になります。お客様は CData の接続機能を以下の目的で利用しています:
- Runtime バージョン 9.1 - 13.X から Pro および Classic Databricks SQL バージョンまで、すべてのバージョンの Databricks にアクセスできます。
- あらゆるホスティングソリューションとの互換性により、お好みの環境で Databricks を使用し続けることができます。
- パーソナルアクセストークン、Azure サービスプリンシパル、Azure AD など、さまざまな方法で安全に認証できます。
- Databricks ファイルシステム、Azure Blob ストレージ、AWS S3 ストレージを使用して Databricks にデータをアップロードできます。
多くのお客様が、さまざまなシステムから Databricks データレイクハウスにデータを移行するために CData のソリューションを使用していますが、ライブ接続ソリューションを使用して、データベースと Databricks 間の接続をフェデレートしているお客様も多数います。これらのお客様は、SQL Server リンクサーバーまたは Polybase を使用して、既存の RDBMS 内から Databricks へのライブアクセスを実現しています。
一般的な Databricks のユースケースと CData のソリューションがデータの問題解決にどのように役立つかについては、ブログをご覧ください:What is Databricks Used For? 6 Use Cases
はじめに
API Server の設定
以下のリンクからAPI Server の無償トライアルをスタートしたら、セキュアなDatabricks OData サービスを作成していきましょう。
Databricks への接続
Coopel からDatabricks のデータを操作するには、まずDatabricks への接続を作成・設定します。
- API Server にログインして、「Connections」をクリック、さらに「接続を追加」をクリックします。
- 「接続を追加」をクリックして、データソースがAPI Server に事前にインストールされている場合は、一覧から「Databricks」を選択します。
- 事前にインストールされていない場合は、コネクタを追加していきます。コネクタ追加の手順は以下の記事にまとめてありますので、ご確認ください。
CData コネクタの追加方法はこちら >> - それでは、Databricks への接続設定を行っていきましょう!
-
Databricks 接続プロパティの取得・設定方法
Databricks クラスターに接続するには、以下のプロパティを設定します。
- Database:Databricks データベース名。
- Server:Databricks クラスターのサーバーのホスト名。
- HTTPPath:Databricks クラスターのHTTP パス。
- Token:個人用アクセストークン。この値は、Databricks インスタンスのユーザー設定ページに移動してアクセストークンタブを選択することで取得できます。
Databricks への認証
CData は、次の認証スキームをサポートしています。
- 個人用アクセストークン
- Microsoft Entra ID(Azure AD)
- Azure サービスプリンシパル
- OAuthU2M
- OAuthM2M
個人用アクセストークン
認証するには、次を設定します。
- AuthScheme:PersonalAccessToken。
- Token:Databricks サーバーへの接続に使用するトークン。Databricks インスタンスのユーザー設定ページに移動してアクセストークンタブを選択することで取得できます。
その他の認証方法については、ヘルプドキュメント の「はじめに」セクションを参照してください。
- 接続情報の入力が完了したら、「保存およびテスト」をクリックします。
Databricks 接続プロパティの取得・設定方法
Databricks クラスターに接続するには、以下のプロパティを設定します。
- Database:Databricks データベース名。
- Server:Databricks クラスターのサーバーのホスト名。
- HTTPPath:Databricks クラスターのHTTP パス。
- Token:個人用アクセストークン。この値は、Databricks インスタンスのユーザー設定ページに移動してアクセストークンタブを選択することで取得できます。
Databricks への認証
CData は、次の認証スキームをサポートしています。
- 個人用アクセストークン
- Microsoft Entra ID(Azure AD)
- Azure サービスプリンシパル
- OAuthU2M
- OAuthM2M
個人用アクセストークン
認証するには、次を設定します。
- AuthScheme:PersonalAccessToken。
- Token:Databricks サーバーへの接続に使用するトークン。Databricks インスタンスのユーザー設定ページに移動してアクセストークンタブを選択することで取得できます。
その他の認証方法については、ヘルプドキュメント の「はじめに」セクションを参照してください。
API Server のユーザー設定
次に、API Server 経由でDatabricks にアクセスするユーザーを作成します。「Users」ページでユーザーを追加・設定できます。やってみましょう。
- 「Users」ページで ユーザーを追加をクリックすると、「ユーザーを追加」ポップアップが開きます。
-
次に、「ロール」、「ユーザー名」、「権限」プロパティを設定し、「ユーザーを追加」をクリックします。

-
その後、ユーザーの認証トークンが生成されます。各ユーザーの認証トークンとその他の情報は「Users」ページで確認できます。

Databricks 用のAPI エンドポイントの作成
ユーザーを作成したら、Databricks のデータ用のAPI エンドポイントを作成していきます。
-
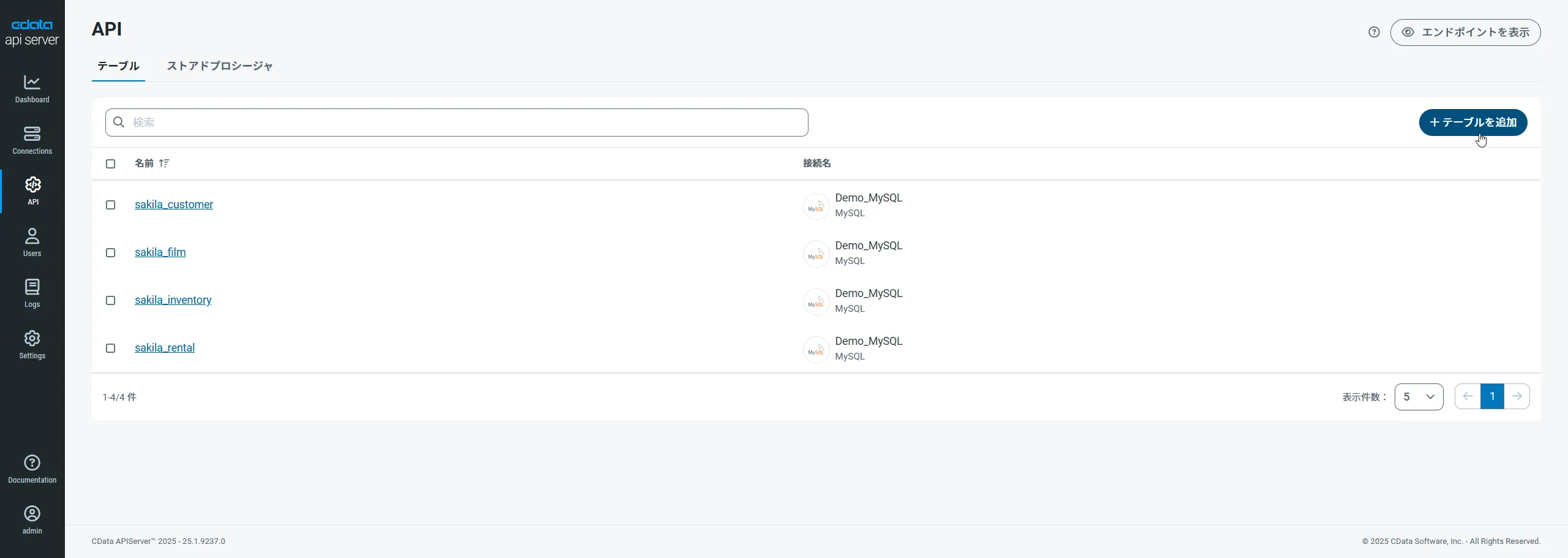
まず、「API」ページに移動し、
「 テーブルを追加」をクリックします。
-
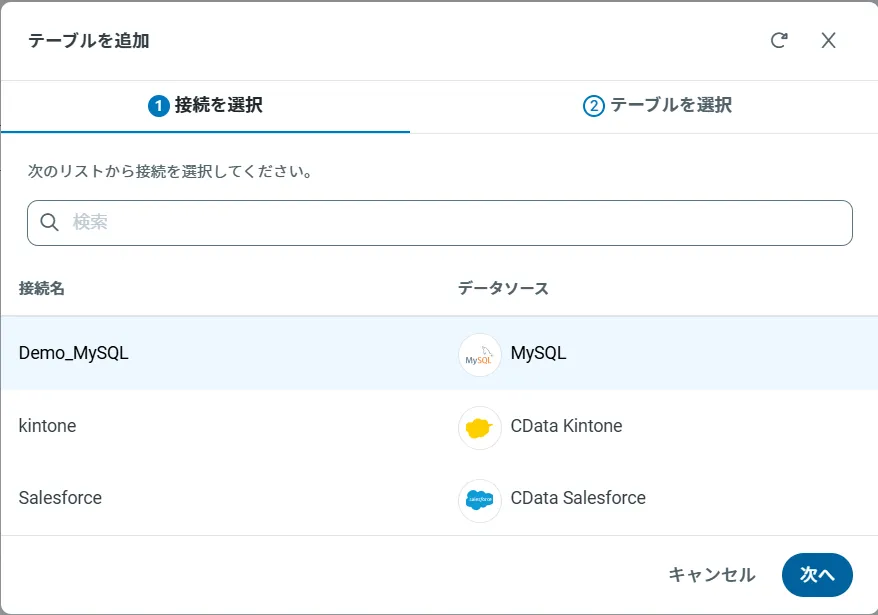
アクセスしたい接続を選択し、次へをクリックします。
-
接続を選択した状態で、各テーブルを選択して確認をクリックすることでエンドポイントを作成します。

OData のエンドポイントを取得
以上でDatabricks への接続を設定してユーザーを作成し、API Server でDatabricks データのAPI を追加しました。これで、OData 形式のDatabricks データをREST API で利用できます。API Server の「API」ページから、API のエンドポイントを表示およびコピーできます。

オンプレミスDB やファイルからのAPI Server 使用(オプション)
オンプレミスRDB やExcel/CSV などのファイルのデータを使用する場合には、API Server のCloug Gateway / SSH ポートフォワーディングが便利です。是非、Cloud Gatway の設定方法 記事を参考にしてください。
Coopel でシナリオを作成する
CData API Server 側の準備が完了したら、早速Coopel 側でシナリオの作成を開始します。
- まず、Coopel にログインし、必要に応じて新しいワークスペースを作成します。
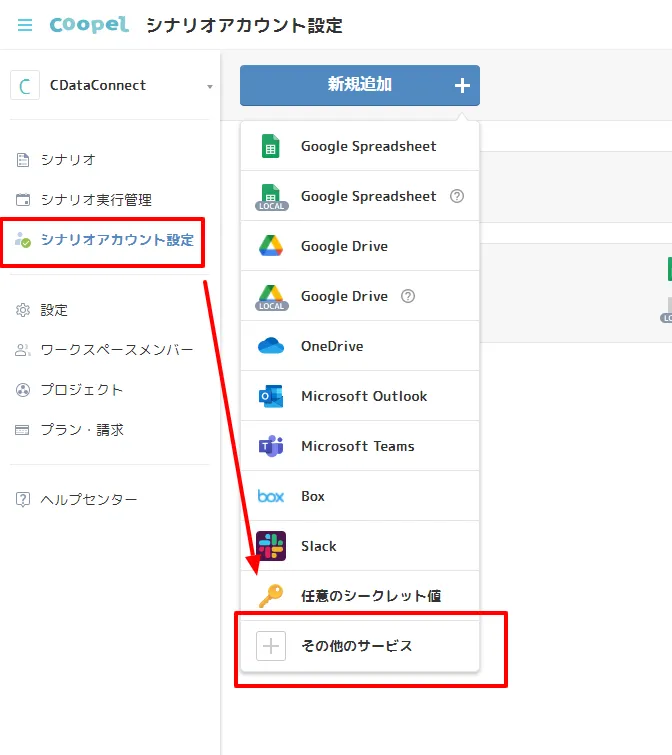
- ワークスペースを作成後、CData API Server にアクセスするための認証情報をCoopel 上に保存しましょう。「シナリオアカウント設定」→「新規追加」→「その他のサービス」を選択します。
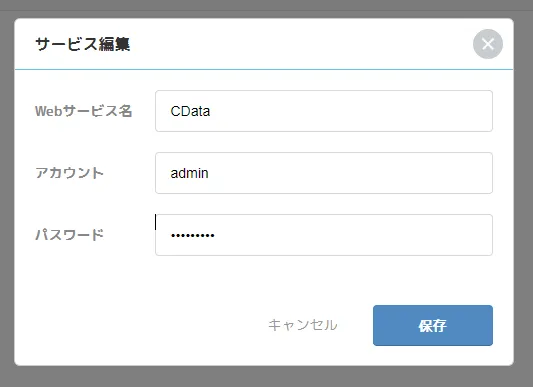
- ここで、CData API Server にアクセスするためのUserID とPassword を入力し、保存じます。Web サービス名には任意の名称を入力してください。
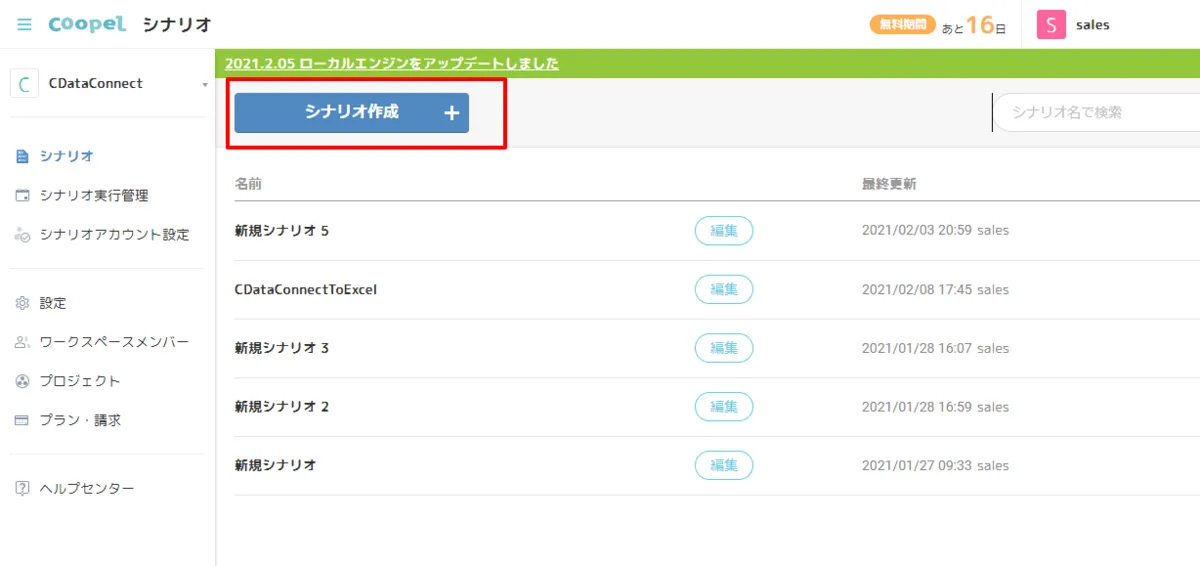
- 次にメインとなるシナリオを作成します。「シナリオ作成」をクリックし
- 任意の名称を入力します。

Databricks のデータを取得する処理を作成
シナリオを作成したらDatabricks のデータを取得する処理の作成を進めましょう。
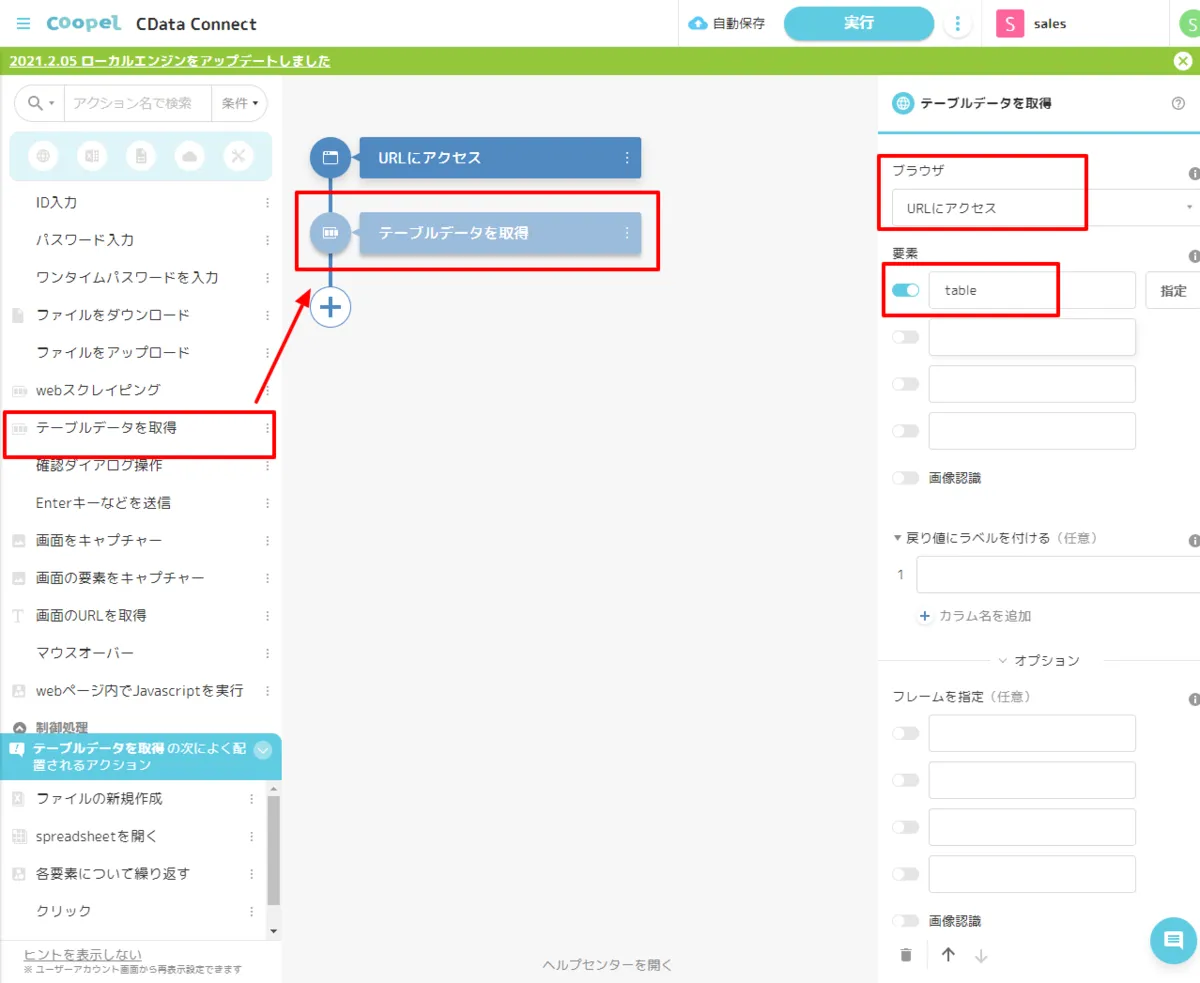
- Coopel からDatabricks のデータを取得するためには、CData API Server を経由します。Coopelでは、ブラウザアクセスと同じような方法でCData API Server にアクセスするので、「URL にアクセス」のアクションを使って、データ取得を行います。Coopel のアクション一覧から「URL にアクセス」を配置し、先程検証した以下の「URL」および、「Basic 認証アカウント」に指定します。
- 続いて、表示されたデータをCoopel 上で扱いやすい形にするためにテーブルデータとして取得を行います。Coopel アクションの一覧から「テーブルデータを取得」を配置し、先程作成した「URL にアクセス」をブラウザへ指定。テーブルの要素として「table」を指定します。
- これで、Coopel 上でCData API Server 経由で取得したデータを操作する準備が整いました。あとはCoopel の様々なアクションを駆使して、フローを作成していきます。

ファイル出力処理を作成
データを取得する処理が作成できたら、そのデータをExcel ファイルに出力してみましょう。
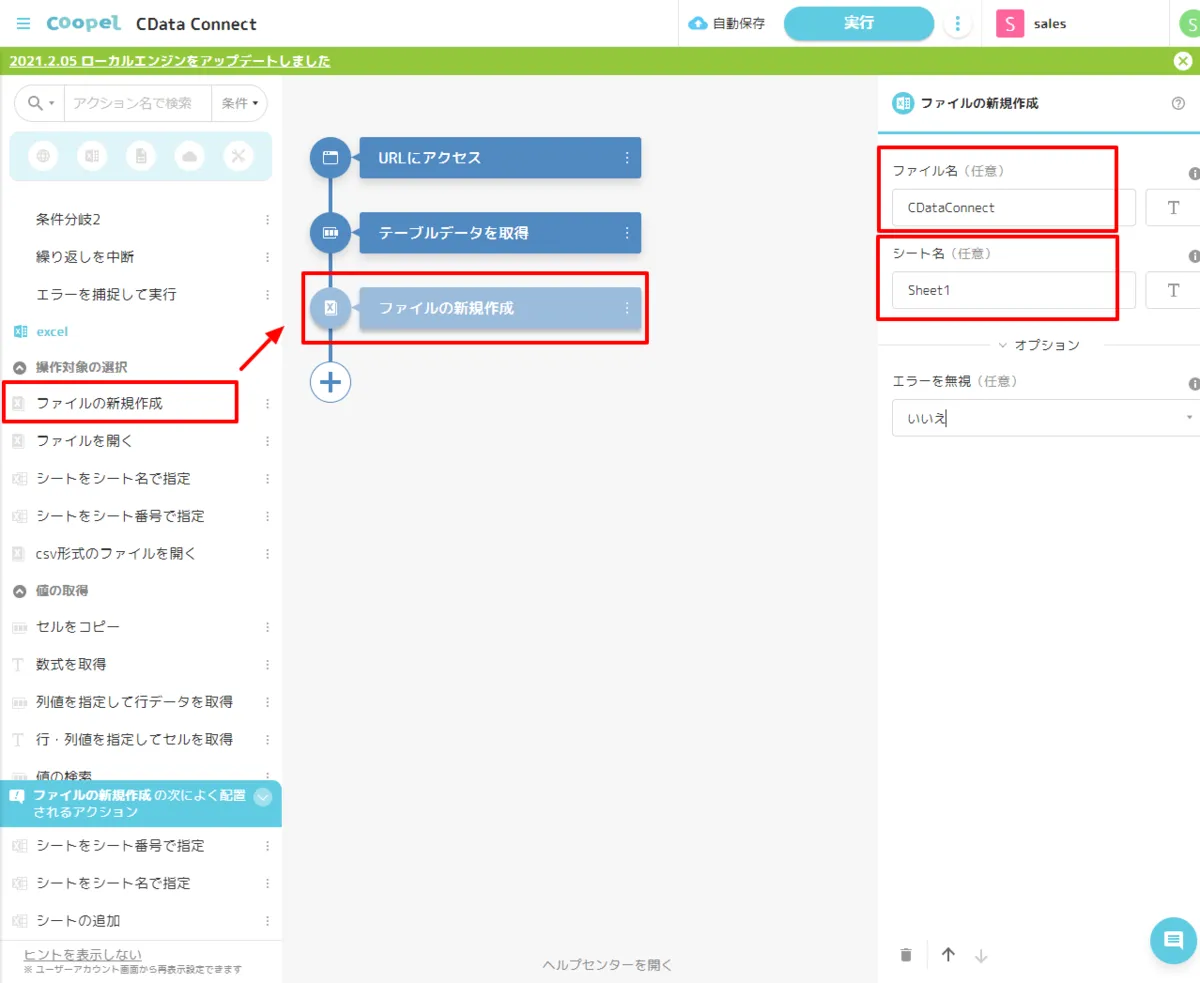
- 最初に「ファイルの新規作成」アクションを使って、Excel ファイルを作成します。任意の名称でファイル名とシート名を指定してください。
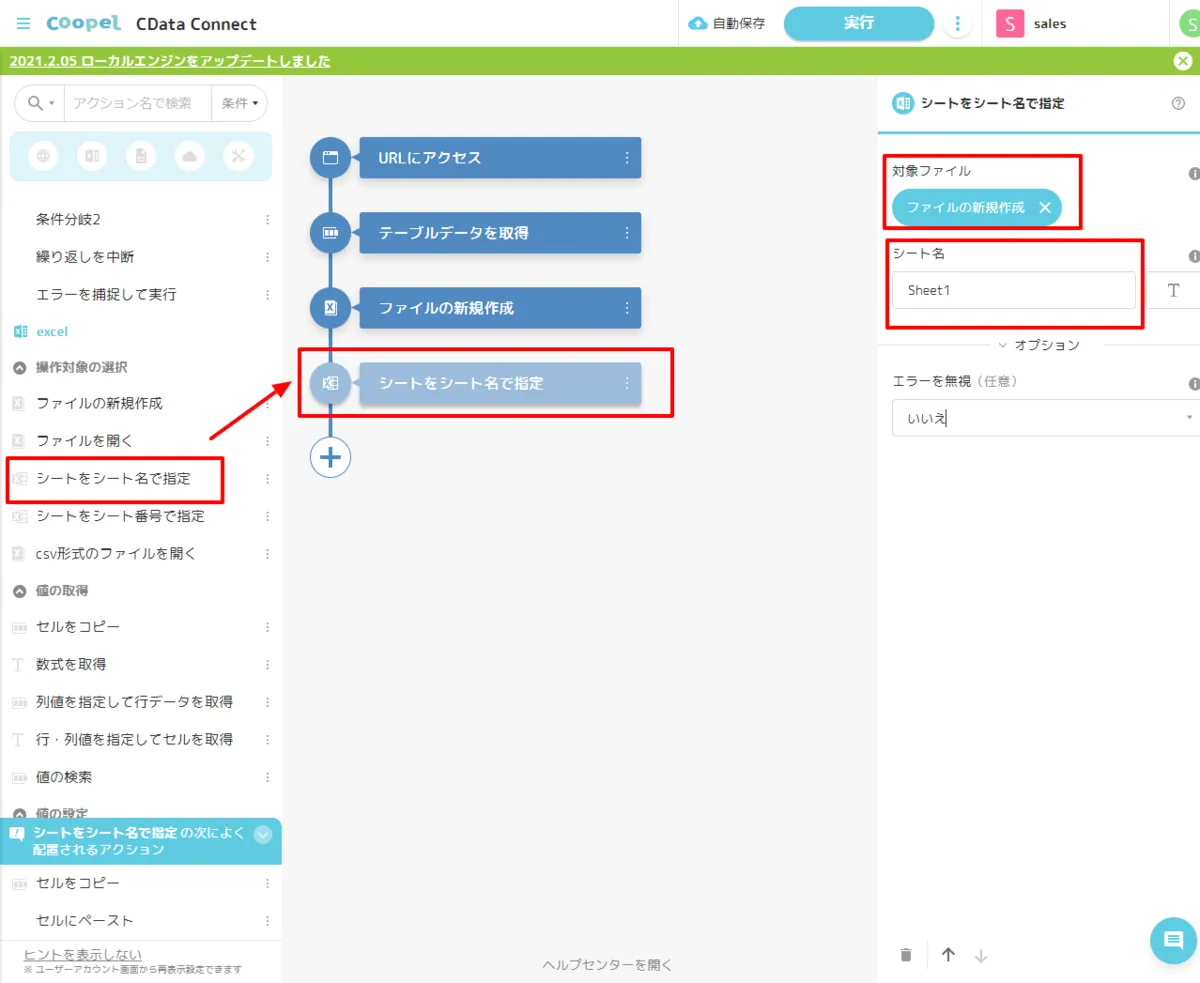
- 次に「シートをシート名で指定」のアクションを配置して、先程作成したExcel ファイルのシートを参照します。
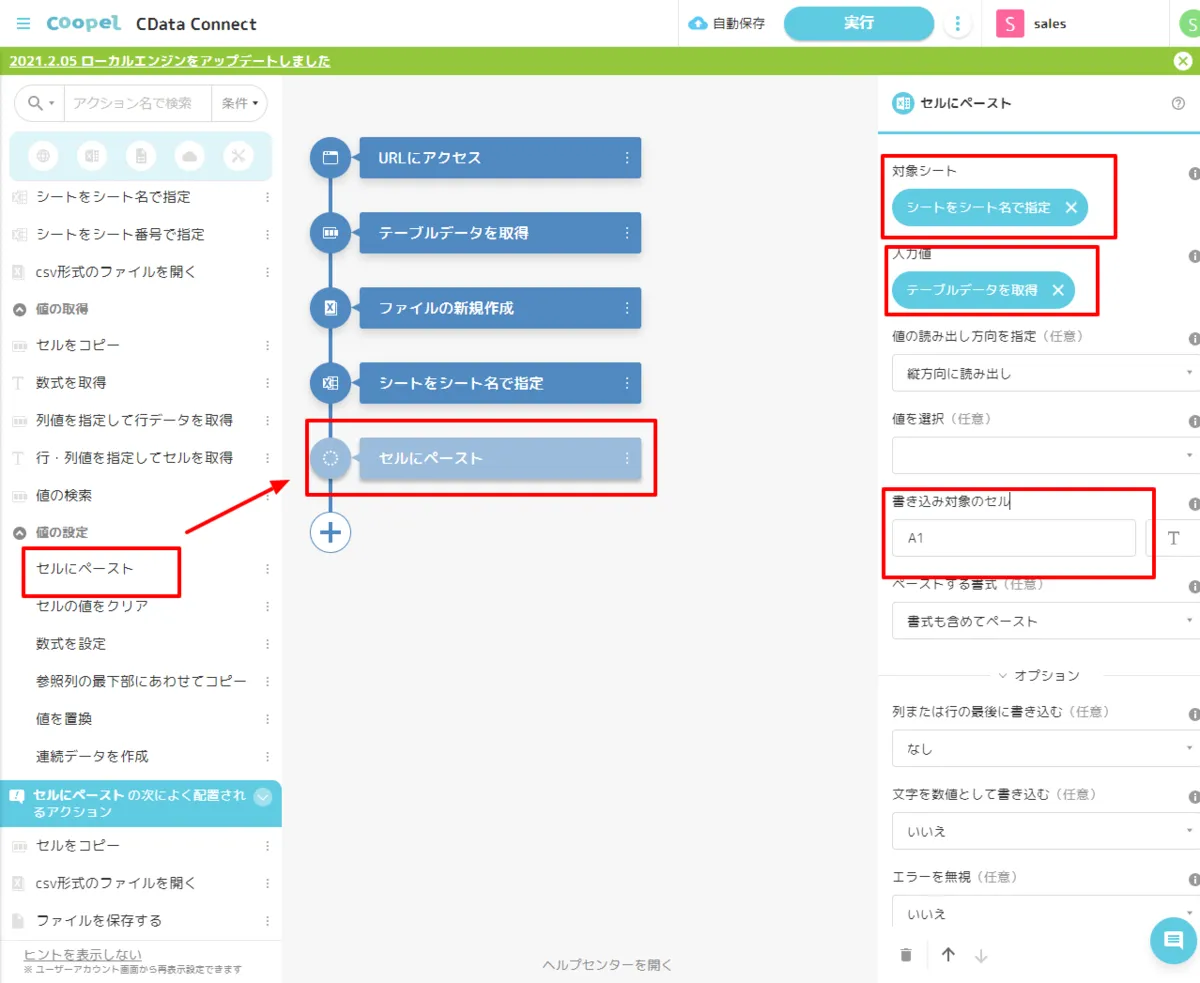
- シートを開いたら、取得したデータを「セルにペースト」アクションで貼り付けます。事前に作成した「対象シート」と、CData API Server から取得した「テーブルデータ」を指定します。書き込み対象セルは一番左上のセルから入力するので「A1」を指定しました。
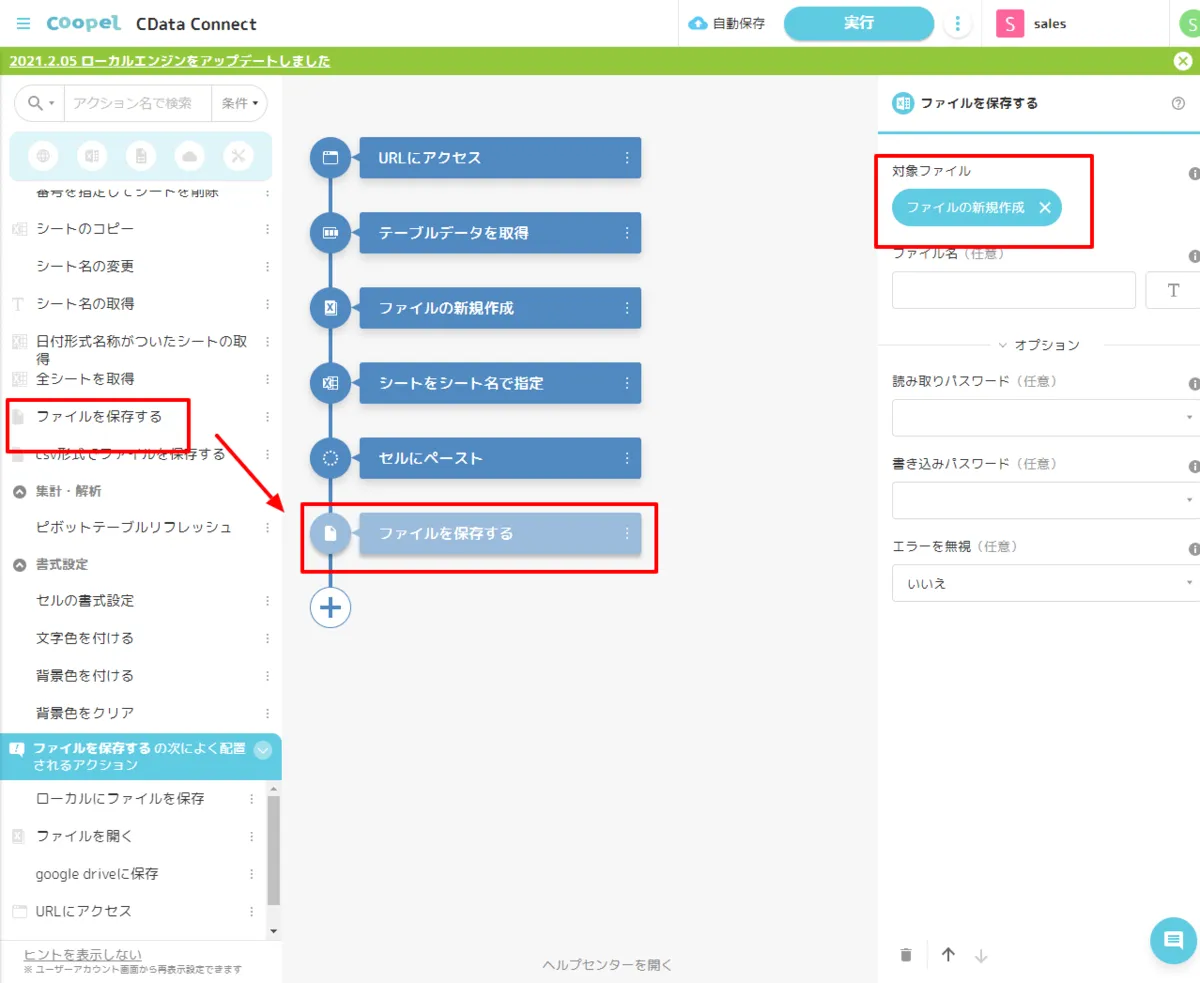
- 最後に作成したExcelファイルを「ファイルを保存する」アクションで保存します。以上ですべてのシナリオが完成しました。
実行
それでは完成したシナリオを実行してみましょう。
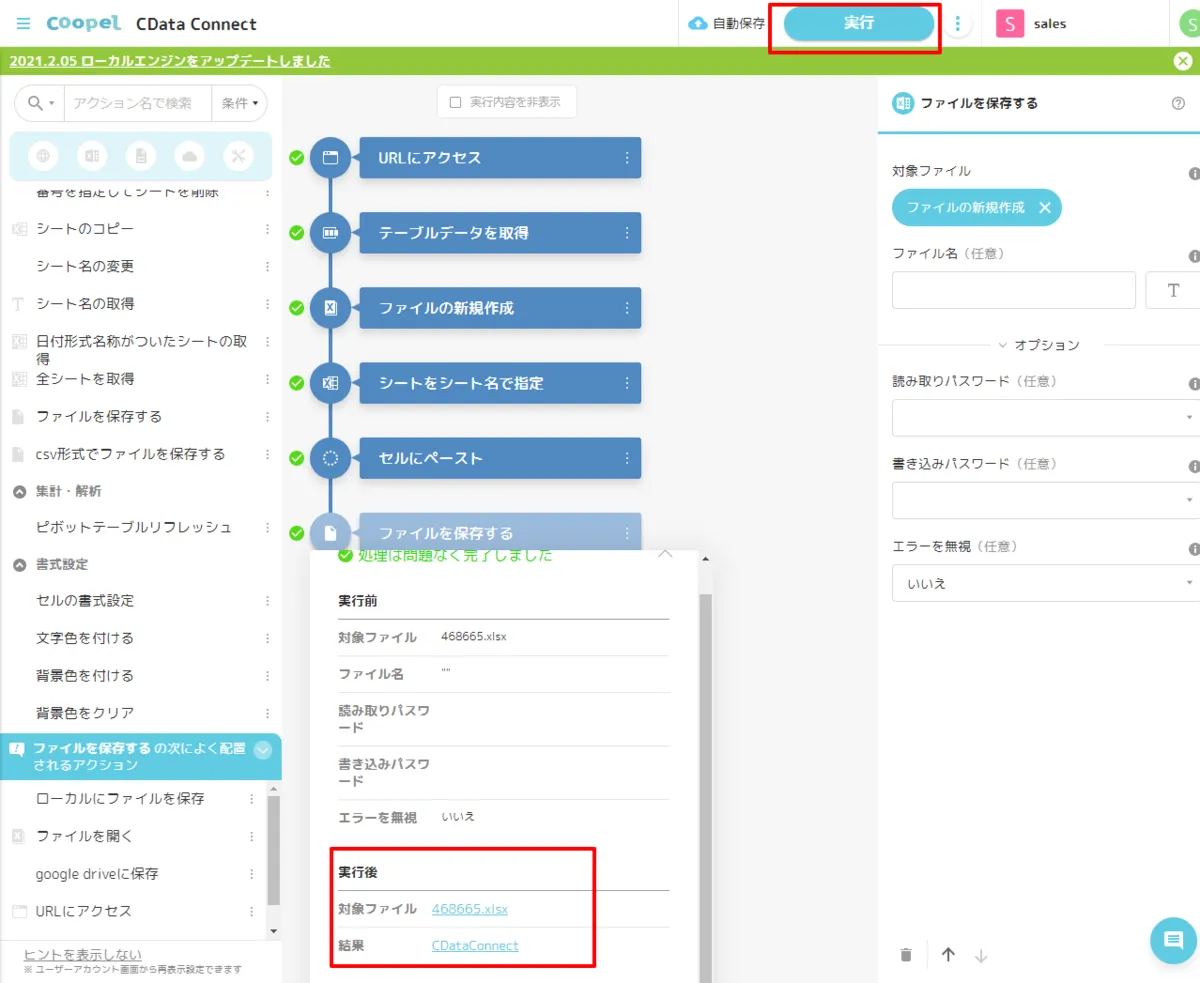
- Coopelでは画面右上の「実行」ボタンでシナリオを試すことができます。正常に実行されると、以下のように「ファイルを保存する」アクションのダイアログに生成されたExcelファイルが表示されます。
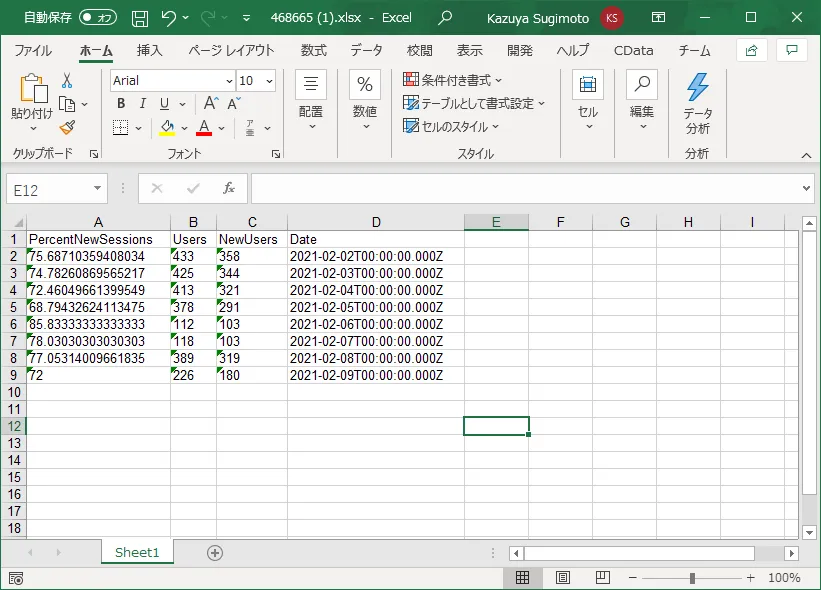
- これをダウンロードして、Excel で開いてみると、以下のようにCData API Server 経由で取得したデータが入力されていることが確認できます。
まとめと30日の無償評価版のご案内
このように Databricks 内のデータをCoopel で利用することができるようになります。CData API Server は、30日の無償評価版があります。是非、お試しいただき、Coopel からのデータ参照を体感ください。