





Azure Data Factory を使用してDatabricks のデータをインポート

Azure Data Factory(ADF)は、フルマネージドのサーバーレスデータ統合サービスです。 CData Connect AI と組み合わせると、ADF はデータフローでDatabricks のデータにクラウドベースで即座にアクセスできます。 この記事では、Connect AI を使用してDatabricks に接続し、ADF でDatabricks のデータにアクセスする方法を紹介します。
Databricks データ連携について
CData を使用すれば、Databricks のライブデータへのアクセスと統合がこれまでになく簡単になります。お客様は CData の接続機能を以下の目的で利用しています:
- Runtime バージョン 9.1 - 13.X から Pro および Classic Databricks SQL バージョンまで、すべてのバージョンの Databricks にアクセスできます。
- あらゆるホスティングソリューションとの互換性により、お好みの環境で Databricks を使用し続けることができます。
- パーソナルアクセストークン、Azure サービスプリンシパル、Azure AD など、さまざまな方法で安全に認証できます。
- Databricks ファイルシステム、Azure Blob ストレージ、AWS S3 ストレージを使用して Databricks にデータをアップロードできます。
多くのお客様が、さまざまなシステムから Databricks データレイクハウスにデータを移行するために CData のソリューションを使用していますが、ライブ接続ソリューションを使用して、データベースと Databricks 間の接続をフェデレートしているお客様も多数います。これらのお客様は、SQL Server リンクサーバーまたは Polybase を使用して、既存の RDBMS 内から Databricks へのライブアクセスを実現しています。
一般的な Databricks のユースケースと CData のソリューションがデータの問題解決にどのように役立つかについては、ブログをご覧ください:What is Databricks Used For? 6 Use Cases
はじめに
Connect AI からDatabricks への接続
CData Connect AI では、直感的なクリック操作ベースのインターフェースを使ってデータソースに接続できます。
- Connect AI にログインし、 Add Connection をクリックします。
- Add Connection パネルで「Databricks」を選択します。
-
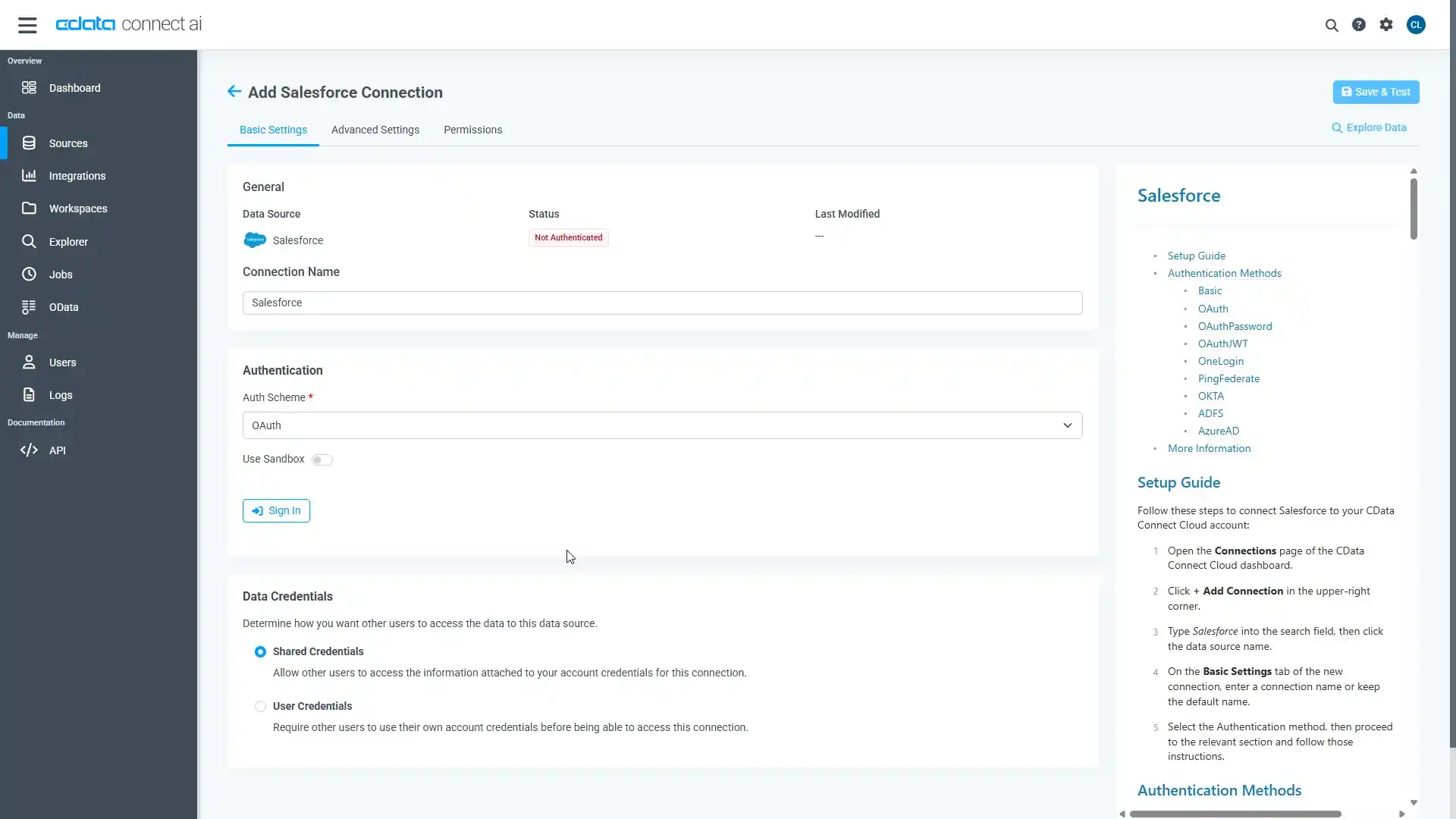
必要な認証プロパティを入力し、Databricks に接続します。
Databricks 接続プロパティの取得・設定方法
Databricks クラスターに接続するには、以下のプロパティを設定します。
- Database:Databricks データベース名。
- Server:Databricks クラスターのサーバーのホスト名。
- HTTPPath:Databricks クラスターのHTTP パス。
- Token:個人用アクセストークン。この値は、Databricks インスタンスのユーザー設定ページに移動してアクセストークンタブを選択することで取得できます。
Databricks への認証
CData は、次の認証スキームをサポートしています。
- 個人用アクセストークン
- Microsoft Entra ID(Azure AD)
- Azure サービスプリンシパル
- OAuthU2M
- OAuthM2M
個人用アクセストークン
認証するには、次を設定します。
- AuthScheme:PersonalAccessToken。
- Token:Databricks サーバーへの接続に使用するトークン。Databricks インスタンスのユーザー設定ページに移動してアクセストークンタブを選択することで取得できます。
その他の認証方法については、ヘルプドキュメント の「はじめに」セクションを参照してください。
- Create & Test をクリックします。
-
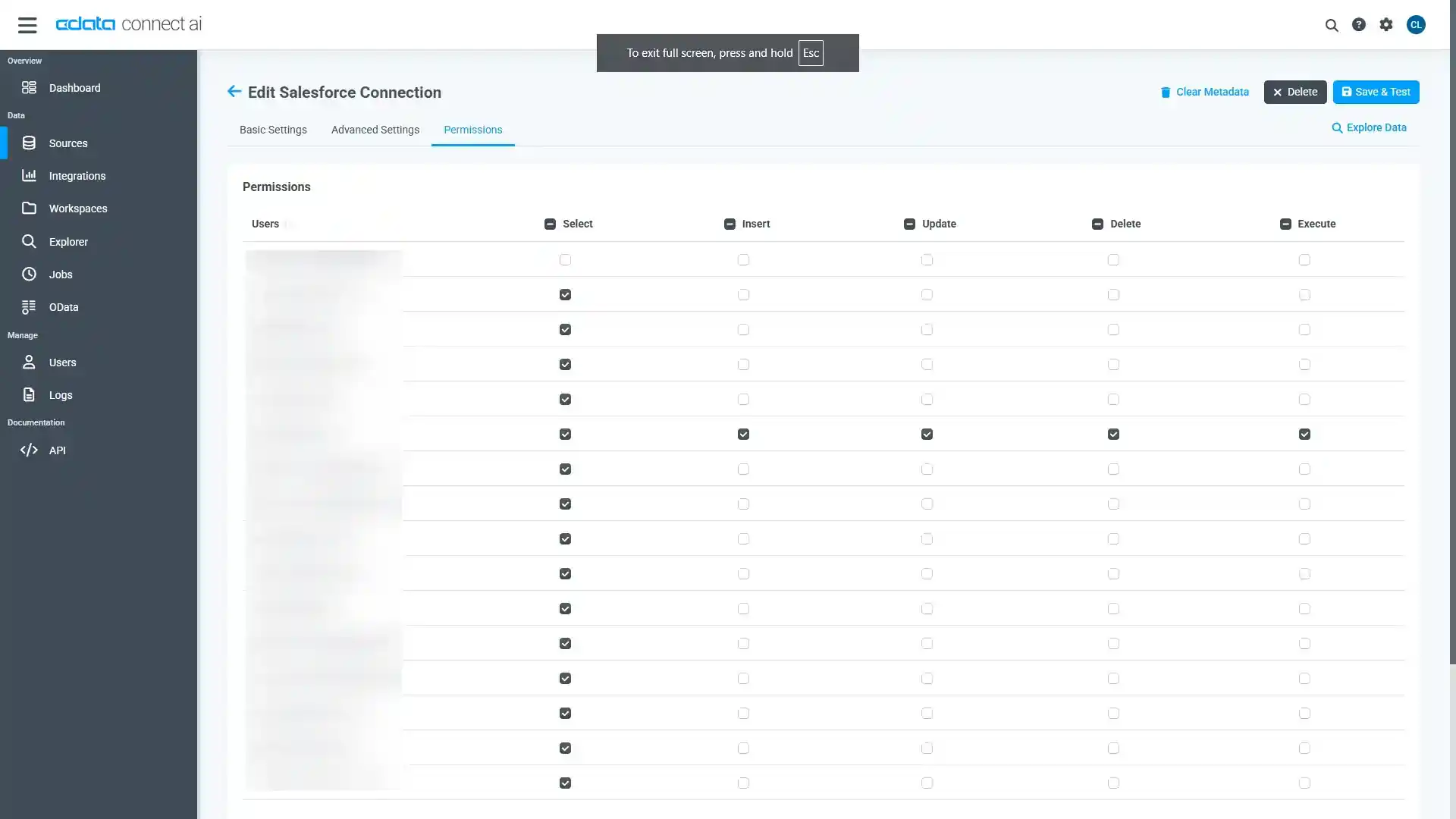
Add Databricks Connection ページのPermissions タブに移動し、ユーザーベースのアクセス許可を更新します。

パーソナルアクセストークンの取得
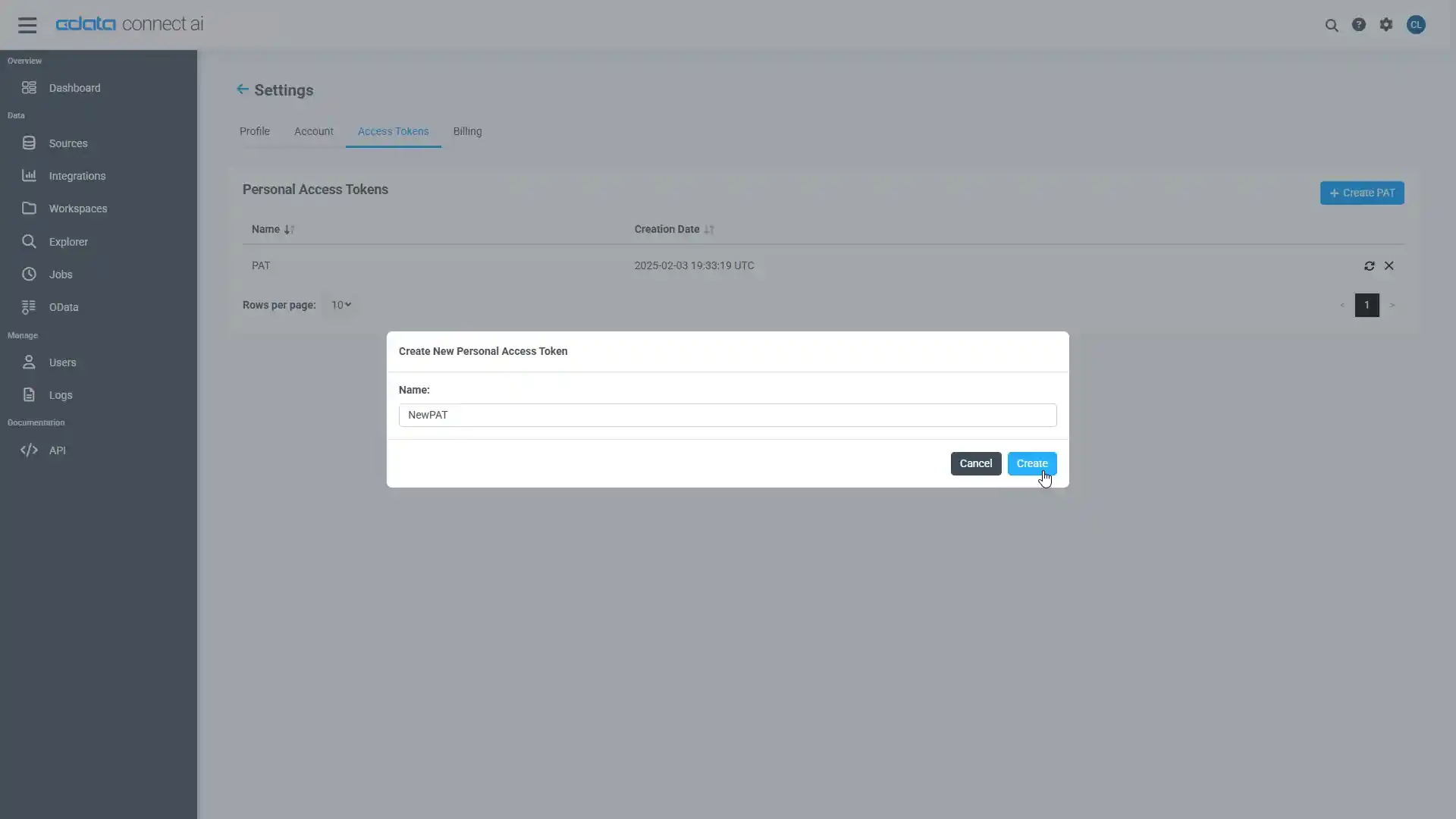
OAuth 認証をサポートしていないサービス、アプリケーション、プラットフォーム、またはフレームワークから接続する場合は、認証に使用するパーソナルアクセストークン(PAT)を作成できます。 きめ細かなアクセス管理を行うために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
- Connect AI アプリの右上にあるユーザー名をクリックし、「User Profile」をクリックします。
- User Profile ページでPersonal Access Token セクションにスクロールし、 Create PAT をクリックします。
- PAT の名前を入力して Create をクリックします。
- パーソナルアクセストークンは作成時にしか表示されないため、必ずコピーして安全に保存してください。
接続設定が完了すると、Azure Data Factory からDatabricks のデータへ接続できるようになります。
Azure Data Factory からリアルタイムDatabricks のデータにアクセス
Azure Data Factory からCData Connect AI の仮想SQL Server API への接続を確立するには、以下の手順を実行します。
- Azure Data Factory にログインします。
- まだData Factory を作成していない場合は、「New -> Dataset」をクリックします。
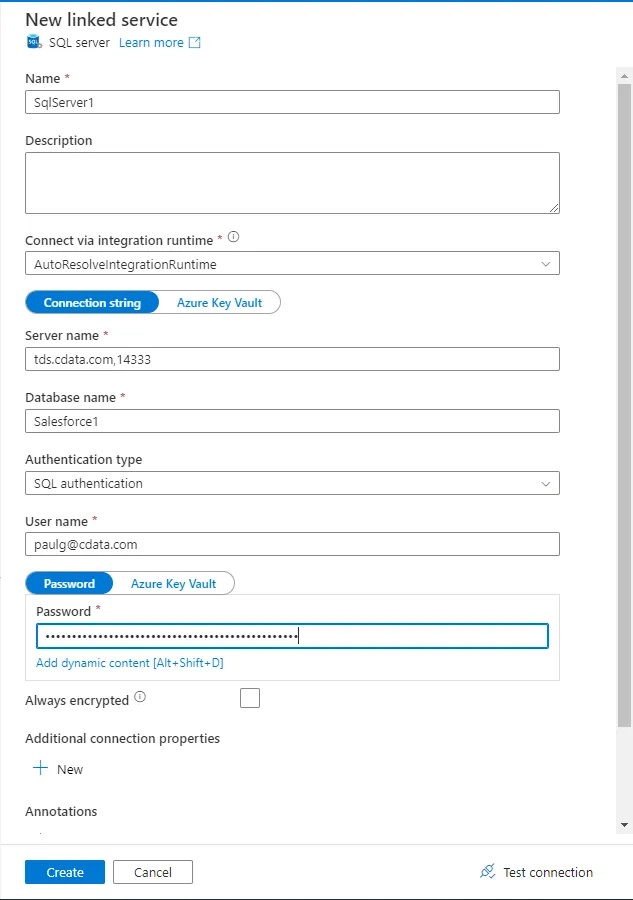
- 検索バーにSQL Server と入力し、表示されたら選択します。次の画面で、サーバーの名前を入力します。 Linked service フィールドで「New」を選択します。
-
接続設定を入力します。
- Name - 任意の名前を入力。
- Server name - 仮想SQL Server のエンドポイントとポートをカンマで区切って入力。例:tds.cdata.com,14333
- Database name - 接続したいCData Connect AI データソースのConnection Name を入力。例:Databricks1
- User Name - CData Connect AI のユーザー名を入力。ユーザー名はCData Connect AI のインターフェースの右上に表示されています。 例:test@cdata.com
- Password - Password(Azure Key Vault ではありません)を選択してSettings ページで生成したPAT を入力。
- 「Create」をクリックします。
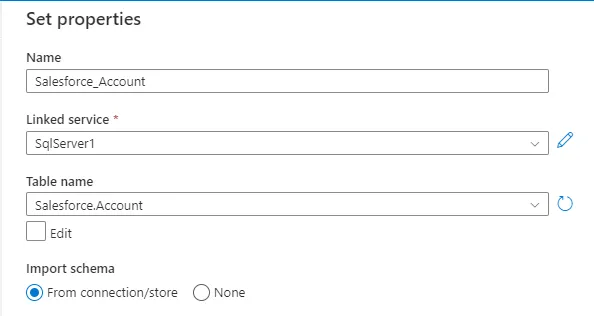
- Set properties で、Name を設定し、続けて先ほど作成したLinked service、利用可能なTable name、Import schema のfrom connection/store を選択します。 「OK」をクリックします。
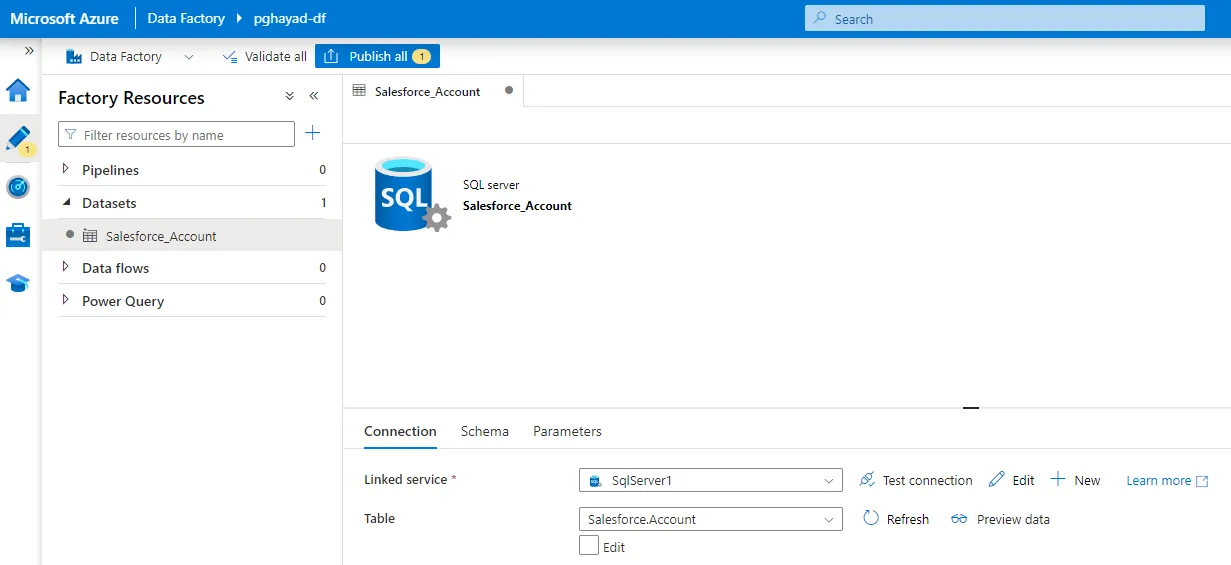
- リンクされたサービスを作成すると、以下の画面が表示されます。
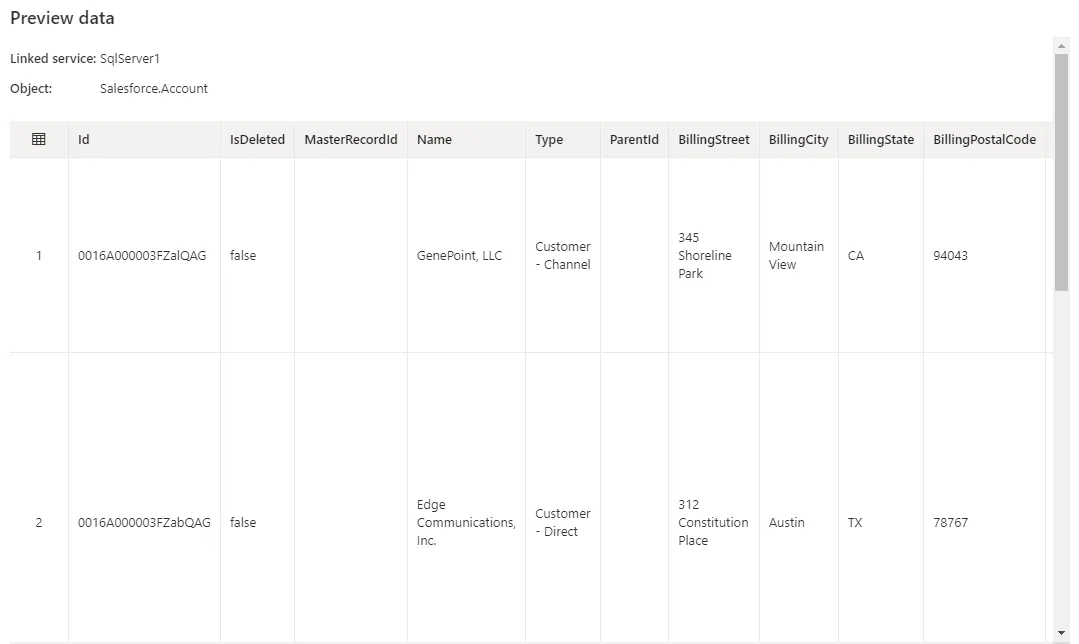
- Preview data をクリックすると、インポートされたDatabricks テーブルが表示されます。
 Azure Data Factory でデータフローを作成する際、このデータセットを使用できるようになりました。
Azure Data Factory でデータフローを作成する際、このデータセットを使用できるようになりました。
CData Connect AI の入手
CData Connect AI の14日間無償トライアルを利用して、クラウドアプリケーションから直接100を超えるSaaS、ビッグデータ、NoSQL データソースへのSQL アクセスをお試しください!