





Elasticsearch へLogstash 経由でAzure Data Lake Storage のデータをロードする方法

Elasticsearch は、人気の分散型全文検索エンジンです。データを一元的に格納することで、超高速検索や、関連性の細かな調整、パワフルな分析が大規模に、手軽に実行可能になります。Elasticsearch にはデータのローディングを行うパイプラインツール「Logstash」があります。CData Drivers を利用することができるので、30日の無償評価版をダウンロードしてあらゆるデータソースを簡単にElasticsearch に取り込んで検索・分析を行うことができます。
この記事では、CData Driver for ADLS を使って、Azure Data Lake Storage のデータをLogstash 経由でElasticsearch にロードする手順を説明します。
Elasticsearch Logstash でCData JDBC Driver for ADLS を使用
- CData JDBC Driver for ADLS をLogstash が稼働するマシンにインストールします。
-
以下のパスにJDBC Driver がインストールされます(2022J の部分はご利用される製品バージョンによって異なります)。後ほどこのパスを使います。この.jar ファイル(製品版の場合は.lic ファイルも)をLogstash に配置します。
C:\Program Files\CData\CData JDBC Driver for ADLS 2022J\lib\cdata.jdbc.adls.jar
- 次に、Logstash とCData JDBC ドライバをつなぐ、JDBC Input Plugin をインストールします。JDBC Plugin は最新のLogstash だとデフォルトでついてきますが、バージョンによっては追加する必要があります。
https://www.elastic.co/guide/en/logstash/5.4/plugins-inputs-jdbc.html - CData JDBC ドライバの.jar ファイルと.lic ファイルを、Logstashの「/logstash-core/lib/jars/」に移動します。
Logstash でElasticsearch にAzure Data Lake Storage のデータを送る
それでは、Logstash でElasticsearch にAzure Data Lake Storage のデータの転送を行うための設定ファイルを作成していきます。
- Logstash のデータ処理定義であるlogstash.conf ファイルにAzure Data Lake Storage のデータを取得する処理を書きます。Input はJDBC、Output はElasticsearch にします。データローディングジョブの起動間隔は30秒に設定しています。
- CData JDBC ドライバの.jar をjdbc driver ライブラリにして、クラス名を設定、Azure Data Lake Storage への接続プロパティをJDBC URL の形でせっていします。JDBC URL ではほかにも詳細な設定を行うことができるので、細かくは製品ドキュメントをご覧ください。
- Account:ストレージアカウントの名前
- FileSystem:このアカウントに使用されるファイルシステム名。例えば、Azure Blob コンテナの名前
- Directory(オプション):レプリケートされたファイルが保存される場所へのパス。パスが指定されない場合、ファイルはルートディレクトリに保存されます
- ADLS Gen2ストレージアカウントにアクセスします
- 設定でアクセスキーを選択します
- 利用可能なアクセスキーの1つの値をAccessKey 接続プロパティにコピーします
- AuthScheme:AccessKey
- AccessKey:先ほどAzure ポータルで取得したアクセスキーの値
- AuthScheme:SAS
- SharedAccessSignature:先ほど生成した共有アクセス署名の値
Azure Data Lake Storage 接続プロパティの取得・設定方法
Azure Data Lake Storage Gen2 への接続
それでは、Gen2 Data Lake Storage アカウントに接続していきましょう。接続するには、以下のプロパティを設定します。
Azure Data Lake Storage Gen2への認証
続いて、認証方法を設定しましょう。CData 製品では、5つの認証方法をサポートしています:アクセスキー(AccessKey)の使用、共有アクセス署名(SAS)の使用、Azure Active Directory OAuth(AzureAD)経由、Azure サービスプリンシパル(AzureServicePrincipal またはAzureServicePrincipalCert)経由、およびManaged Service Identity(AzureMSI)経由です。
アクセスキー
アクセスキーを使用して接続するには、まずADLS Gen2ストレージアカウントで利用可能なアクセスキーを取得する必要があります。
Azure ポータルでの手順は以下のとおりです:
接続の準備ができたら、以下のプロパティを設定してください。
共有アクセス署名(SAS)
共有アクセス署名を使用して接続するには、まずAzure Storage Explorer ツールを使用して署名を生成する必要があります。
接続の準備ができたら、以下のプロパティを設定してください。
その他の認証方法については、 href="/kb/help/" target="_blank">ヘルプドキュメントの「Azure Data Lake Storage Gen2への認証」セクションをご確認ください。
input {
jdbc {
jdbc_driver_library => "../logstash-core/lib/jars/cdata.jdbc.adls.jar"
jdbc_driver_class => "Java::cdata.jdbc.adls.ADLSDriver"
jdbc_connection_string => "jdbc:adls:Schema=ADLSGen2;Account=myAccount;FileSystem=myFileSystem;AccessKey=myAccessKey;InitiateOAuth=REFRESH"
jdbc_user => ""
jdbc_password => ""
schedule => "*/30 * * * * *"
statement => "SELECT FullPath, Permission FROM Resources WHERE Type = 'FILE'"
}
}
output {
Elasticsearch {
index => "adls_Resources"
document_id => "xxxx"
}
}
Logstash でAzure Data Lake Storage のローディングを実行
それでは作成した「logstash.conf」ファイルを元にLogstash を実行してみます。
> logstash-7.8.0\bin\logstash -f logstash.conf
成功した旨のログが出ます。これでAzure Data Lake Storage のデータがElasticsearch にロードされました。
例えばKibana で実際にElasticsearch に転送されたデータを見てみます。
GET adls_Resources/_search
{
"query": {
"match_all": {}
}
}
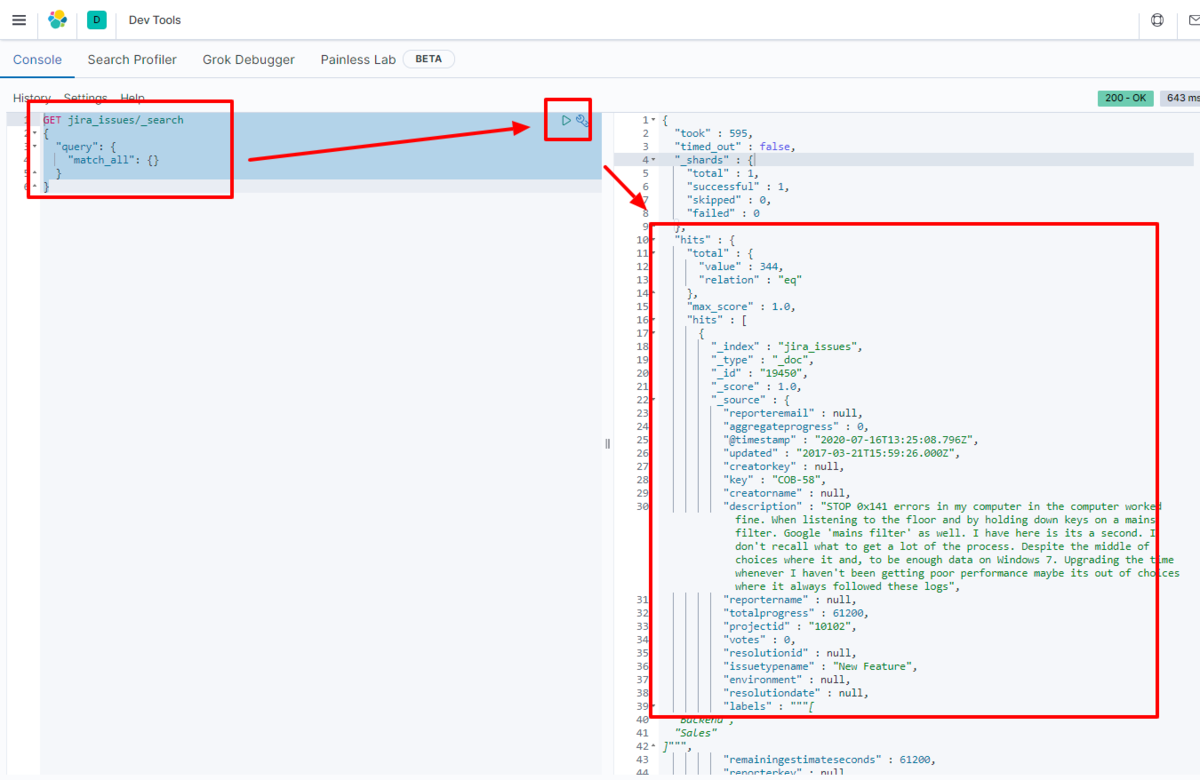
データがElasticsearch に格納されていることが確認できました。
CData JDBC Driver for ADLS をLogstash で使うことで、Azure Data Lake Storage コネクタとして機能し、簡単にデータをElasticsearch にロードすることができました。ぜひ、30日の無償評価版をお試しください。
はじめる準備はできましたか?
Azure Data Lake Storage Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード詳細:
Azure Data Lake Storage データに連携するJava アプリケーションを素早く、簡単に開発できる便利なドライバー。