





エンタープライズサーチのNeuron にAdobe Target のデータを取り込んで検索利用

ブレインズテクノロジー社のNeuron は、先端OSS 技術(Apache Solr)を活用したエンタープライズサーチ(企業内検索エンジン)サービスです。Apache Solr は、エンタープライズサーチ機能をAPI として提供してくれますが、Neuron はApache Solr に企業ユーザーがデータを探索するためのシンプルかつ使いやすいユーザーインターフェースと管理画面・運用機能を提供してくれます。これによりエンドユーザーが簡単にエンタープライズサーチを利用することができます。管理画面では、ファイルやデータのクローリング設定がUI で行えるようになっています。この記事では、Neuron に備わっているJDBC インターフェース経由で、CData JDBC Driver for AdobeTarget を利用することでNeuron にAdobe Target のデータを取り込んで検索で利用できるようにします。
Neuron にCData JDBC Driver for AdobeTarget データをロード
CData JDBC Driver for AdobeTarget のインストールと.jar ファイルの配置
- CData JDBC Driver for AdobeTarget をNeuron と同じマシンにインストールします。
-
以下のパスにJDBC Driver がインストールされます。
C:\Program Files\CData\CData JDBC Driver for AdobeTarget 20xxJ\lib\cdata.jdbc.adobetarget.jar
-
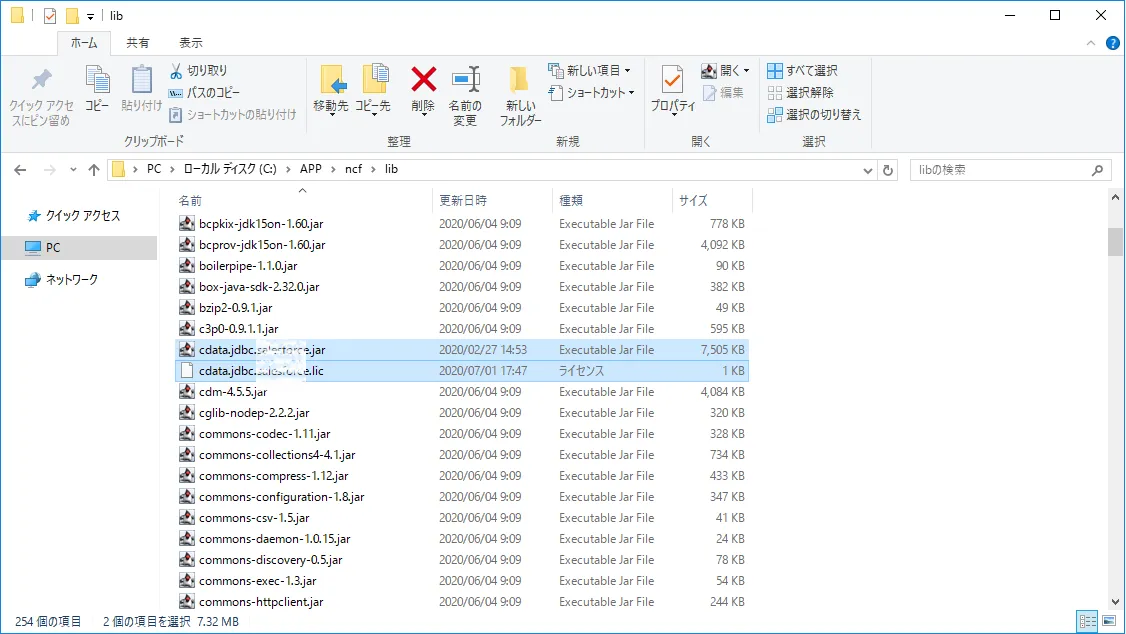
このcdata.jdbc.adobetarget.jar とcdata.jdbc.adobetarget.lic ファイルをコピーして、Neuron のC:\APP
cf\lib フォルダに配置します。
Neuron CF でのAdobe Target のデータを扱うリポジトリの作成
-
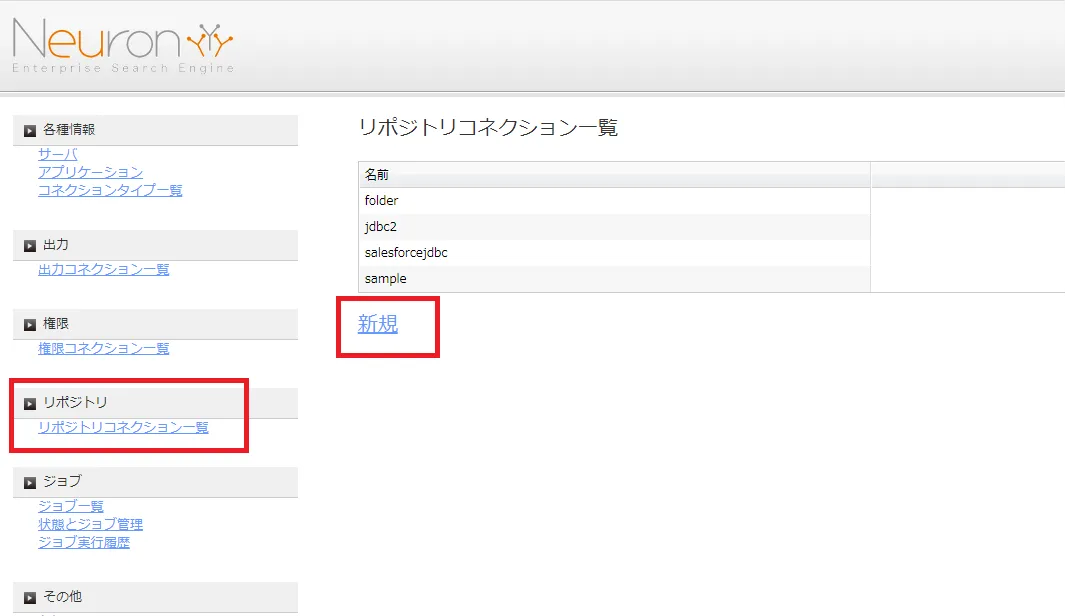
Neuron CF でクローラーの設定をGUI で行います。JDBC を読み取るためのリポジトリを作成します。Neuron の管理画面にログインし、[リポジトリ]→[リポジトリコレクション一覧]→[新規]をクリックします。
-
任意のリポジトリ名を入力します。タイプは[JDBC]を選択します。

-
次に、ドライバーのクラス名とJDBC 接続文字列でAdobe Target への接続を行います。
Adobe Target に接続するには、以下に記載されているOAuth 接続プロパティとともにTenant プロパティを指定する必要があります。他の接続プロパティは処理動作に影響を与える可能性がありますが、接続には影響しません。
以下のステップでTenant 名を確認できます。
- Adobe Experience にログインします。URL は「https://experience.adobe.com/#/@mycompanyname/preferences/general-section」です。
- 「/#/@」の後の値を抽出します。この例では「mycompanyname」です。
- Tenant 接続プロパティをその値に設定します。
ユーザーアカウント(OAuth)
すべてのユーザーアカウントフローでAuthScheme をOAuthClient に設定する必要があります。
注意:OAuth を介したAdobe 認証では、2週間ごとにトークンを更新する必要があります。
すべてのアプリケーション
CData では、OAuth 認証を簡素化する組み込みOAuth アプリケーションを提供しています。または、カスタムOAuth アプリケーションを作成することもできます。詳細については、ヘルプドキュメントの「カスタムOAuthアプリの作成」をご確認ください。OAuth アクセストークンの取得
接続するには以下のプロパティを設定します:
- InitiateOAuth:GETANDREFRESH に設定して、OAuth 交換を自動的に実行し、必要に応じてOAuthAccessToken を更新します。
- OAuthClientId:アプリを登録した際に割り当てられたクライアントID に設定します。
- OAuthClientSecret:アプリを登録した際に割り当てられたクライアントシークレットに設定します。
- CallbackURL:アプリを登録した際に定義されたリダイレクトURI に設定します。例:https://localhost:3333
これらの設定により、プロバイダーはAdobe Target からアクセストークンを取得し、それを使用してデータを要求します。OAuth値はOAuthSettingsLocation で指定された場所に保存され、接続間で確実に保持されます。
ドライバクラス名:cdata.jdbc.adobetarget.AdobeTargetDriver
接続文字列:jdbc:adobetarget:Tenant=mycompanyname;InitiateOAuth=REFRESH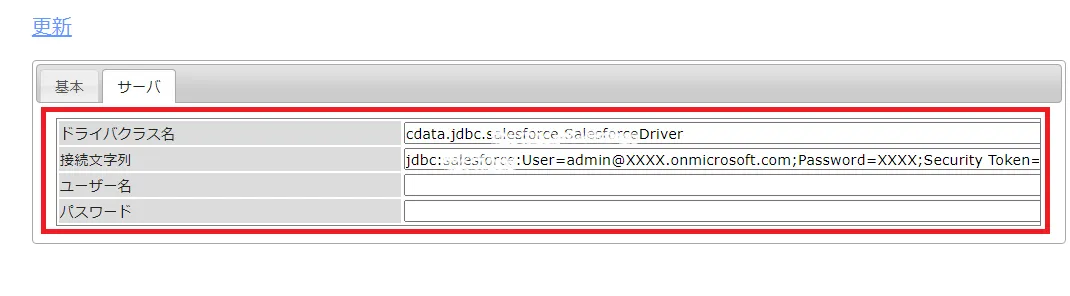
- [更新]をクリックして、Adobe Target に接続するリポジトリコレクションができました。
Neuron でAdobe Target のデータをクローリングするジョブを作成
続いて、Adobe Target のどのデータをどのようにクローリングするのかをジョブで定義していきます。
-
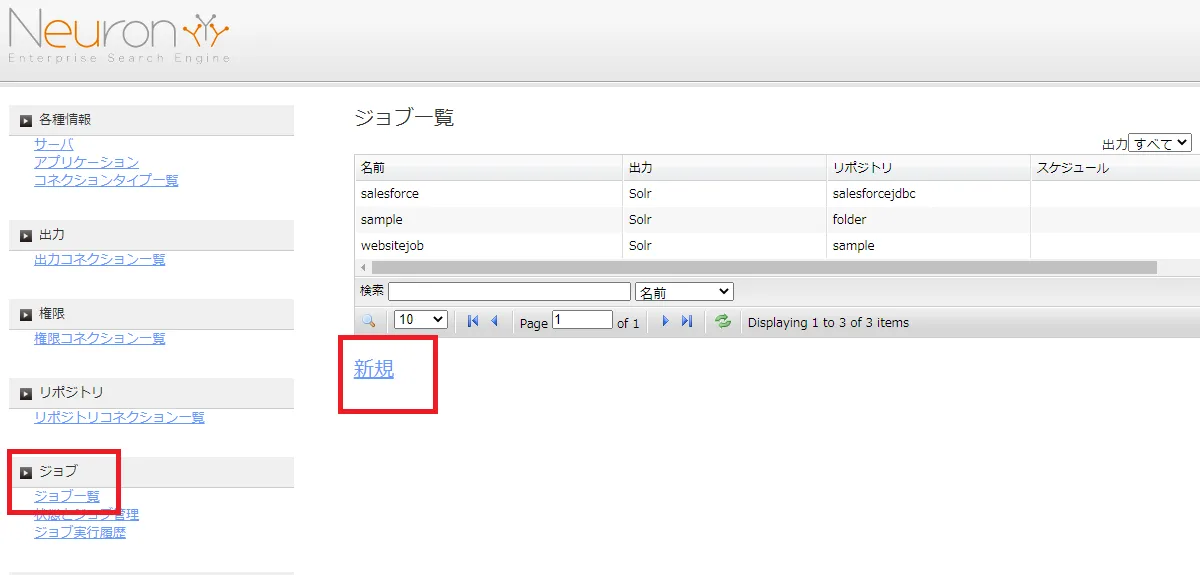
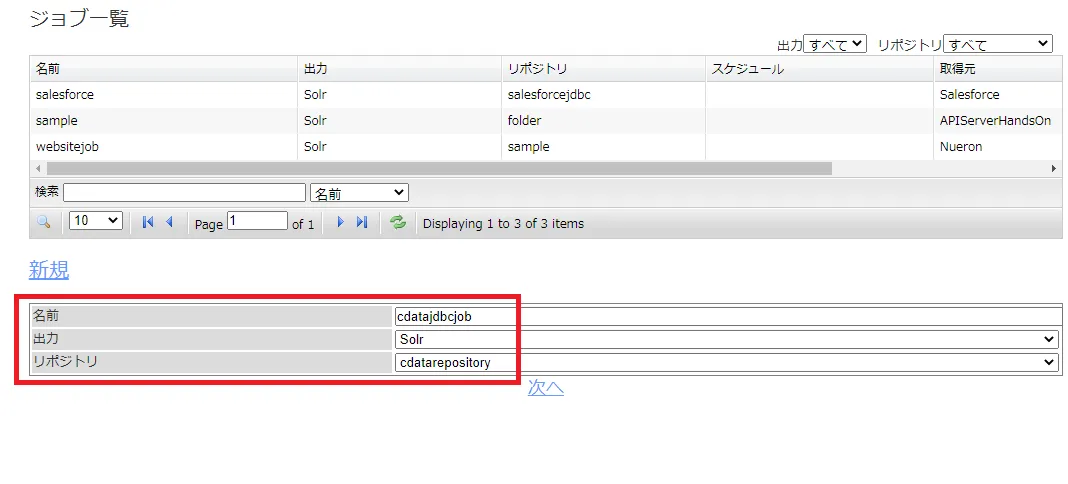
管理画面で[ジョブ]→[ジョブ一覧]→[新規]とクリックします。
-
任意のジョブ名を入力します。出力先にはSolr を選択します。リポジトリは先ほど作成したAdobe Target に接続するリポジトリコレクションを選びます。
-
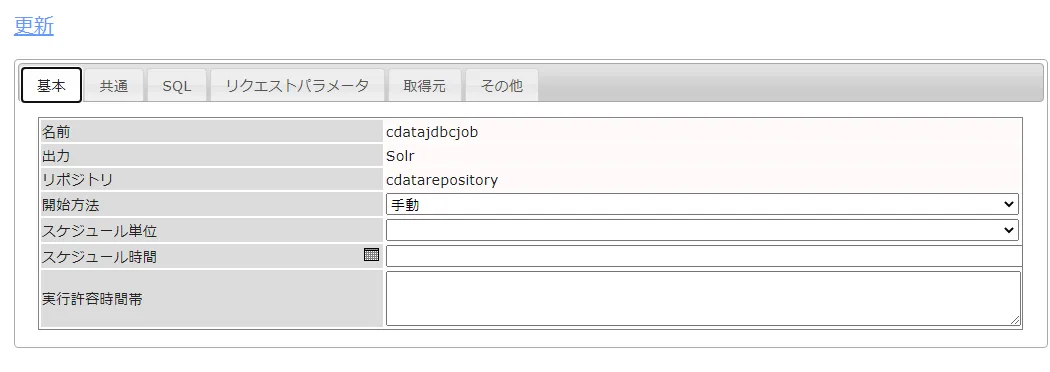
次に基本タブからジョブ実行を手動にするか、定期実行するかを自由に設定します。
-
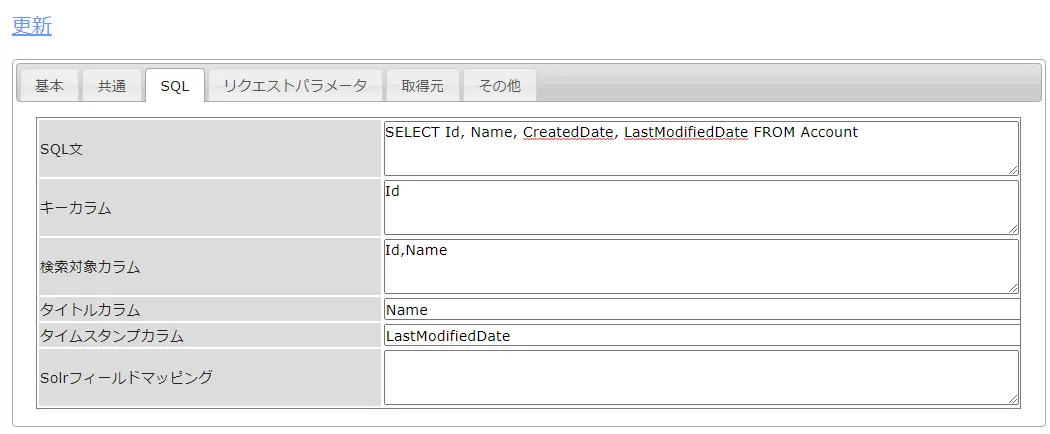
SQL タブでは、どんなデータを取得するのか、テーブル名やカラム、フィルタリング条件などを設定できます。CData JDBC ドライバがAdobe Target のデータをテーブルにモデル化しているので、標準SQL でAdobe Target をクエリすることができます。
- SQL文:SELECT Id, Name FROM Activities
- キーカラム:Id など取得テーブルのキーとなるカラム
- 検索対象カラム:検索の対象とするカラム
- タイトルカラム:検索結果のタイトルとするカラム
- タイムスタンプカラム:タイムスタンプとなるカラムがあれば、ここで指定します
- リクエストパラメータでは、検索結果レコードのURL (があれば)を設定することもできます。URL を表示できると表示された検索結果からレコードに簡単に移動できます。
- 取得元では、ラベルを設定しておきます。[更新]をクリックして、クローラージョブの設定を完了します。
Neuron でAdobe Target のデータをクロールするジョブを実行
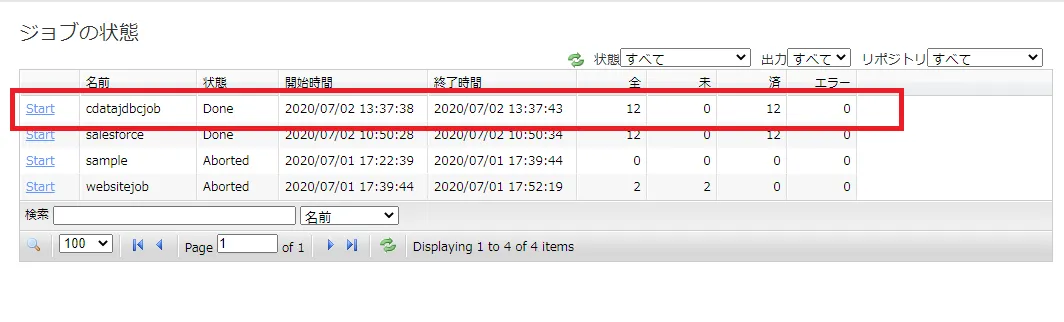
実際にNeuron で作成したジョブを実行します。[ジョブ]→[状態とジョブ管理]をクリックし、作成したジョブの[Start]をクリックします。
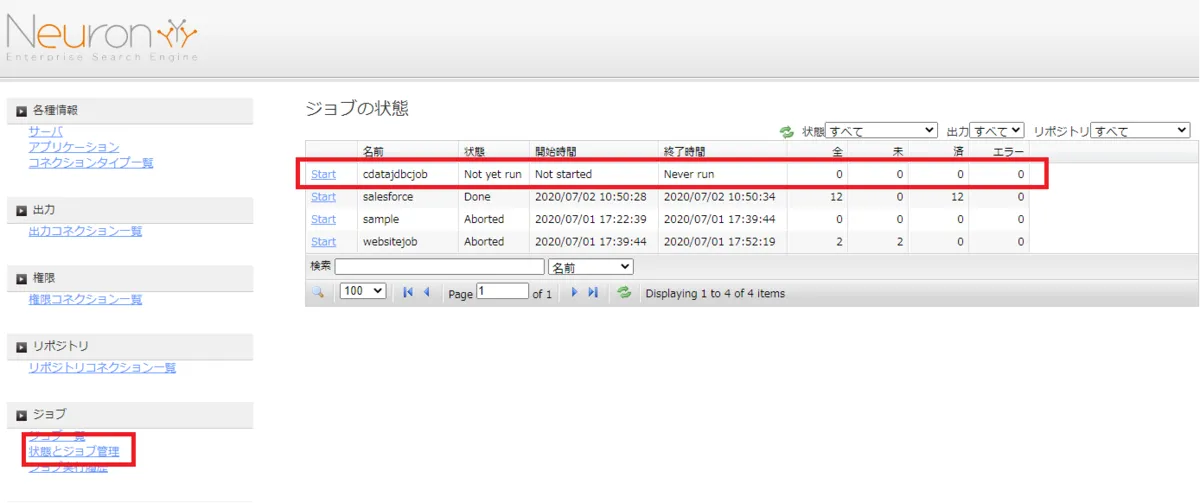
ジョブが正常完了すると、[Done]がステータスとして表示されます。
Neuron 上でのAdobe Target のデータの検索の実施
実際にNeuron 上で検索ができるか確認してみます。取得元を絞り込むこと、内容やファイル名での検索、ファイルサイズやファイル更新日の絞り込み、部分一致や全部一致で検索が可能です。 検索をかけてみると、以下のようにデータを取得できました。
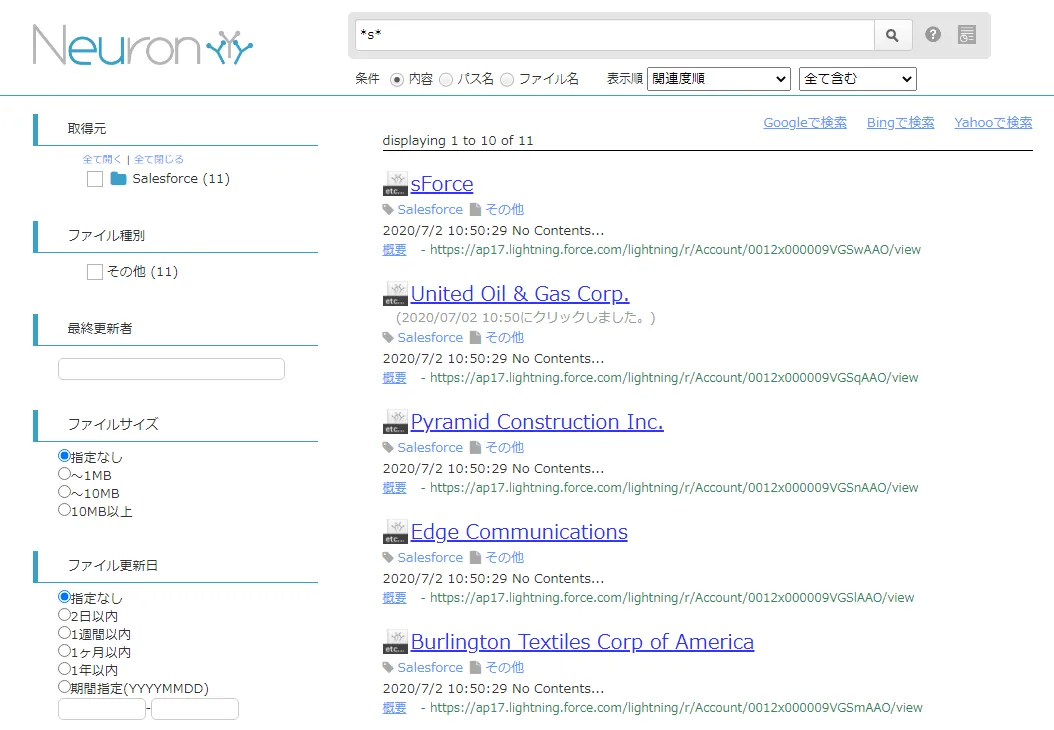
CData JDBC Driver for AdobeTarget をNeuron で使うことで、Adobe Target コネクタとして機能し、簡単にデータを取得して同期することができました。ぜひ、30日の無償評価版をお試しください。
はじめる準備はできましたか?
Adobe Target Driver の無料トライアルをダウンロードしてお試しください:
ダウンロード